Challenge 2 : Alignment
- 정의
- 서로 다른 모달리티에 존재하는 여러 element 사이에 connection 을 어떻게 식별하고 모델링할 것인지를 다룬다.
- Sub-challenges

- Connections
- 모달리티 사이에서 어떤 요소가 어떤 요소와 대응하는지 (grounding) 를 명시적으로 밝히고, 이를 구조적으로 연결하는 방법을 찾는 과제
- Aligned Representation
- 연결을 기반으로, 모달리티의 정보를 하나로 통합하거나 적절히 표현(embedding) 하는 방법을 찾는 과제
- Segmentation
- 모달리티 간에 개별 요소들을 얼마나 세밀하게 나눌 것인지 (분할의 granularity) 를 결정하고 처리하는 과제
- 예를 들어, Image 에서는 픽셀 단위로 나눌 것인지, 객체 단위로 나눌 것인지
텍스트에서는 문장 단위인지 단어 단위인지 등을 정하는 과정
- 예를 들어, Image 에서는 픽셀 단위로 나눌 것인지, 객체 단위로 나눌 것인지
- 모달리티 간에 개별 요소들을 얼마나 세밀하게 나눌 것인지 (분할의 granularity) 를 결정하고 처리하는 과제
- 순서의 논리
- 먼저: Connection을 통해 각 모달리티 간의 기본 대응 관계를 파악하고, Aligned Representation을 통해 이를 통합된 표현으로 만들어낸다.
- 그 다음: Segmentation을 통해 이 통합된 표현을 기반으로, 실제로 어떤 부분이 중요한지, 그리고 그 부분을 어떻게 분할(예: 이미지의 객체 단위, 텍스트의 단어나 구 단위)할 것인지를 결정다.
- Connections
그렇다면, Explicit alignment 와 Implicit alignment 의 차이점은 무엇인가?
- Explicit Alignment (명시적 정렬)
- 직접적으로 대응관계를 표시한다.
- 예를 들어, 텍스트와 이미지가 있을 때, 이미지 속 특정 객체가 텍스트의 특정 단어(혹은 구절)와 연결됨을 명시적으로 레이블하거나 바운딩 박스를 그려 매핑 정보를 기록한다.
- 모델 입장에서는 사람이 제공한(or 미리 정의된) ‘이 부분이 이 부분에 해당한다’라는 정확한 짝(pairing) 정보를 통해 학습하므로, 정확하고 해석 가능한 대응이 가능하다는 장점이 있다.
- 다만, 이러한 정렬 정보를 **직접 만들기 위해서는 많은 노력(레이블링 비용)**이 든다는 점이 단점이다.
- Implicit Alignment (암묵적 정렬)
- 직접적인 레이블 없이, 모델 내부에서 정렬 관계를 학습한다.
- 예를 들어, 텍스트와 이미지를 각각 동일한 임베딩 공간에 투영(embedding)해서, 유사한 의미나 맥락을 공유하는 요소들끼리 공간적으로 가깝게 위치시키도록 학습하는 방식이다.
- 명시적으로 “이것이 이것과 짝이 된다”라고 말하지 않더라도, 모델이 학습 과정에서 자연스럽게(혹은 간접적인 지도신호를 통해) 대응관계를 찾게 된다.
Sub-Challenge 2a: Connections

- 정의
- 여러 모달리티(텍스트, 이미지, 오디오 등)에서 나오는 요소들 중, 어떤 것들이 왜 연결(관계)되어야 하는가
- 연결 방식


여러 모달리티(삼각형, 원 등)에서 들어오는 신호(signals) 를 종합해 추론(inference) 을 수행하고, 이를 기반으로 응답(response) 을 생성한다.

- 조건부(Conditional):
- 어떤 맥락이나 조건에 따라 두 요소가 연결되거나 영향을 주고받는 경우.
- 예: 특정 상황에서만 텍스트와 이미지가 매칭된다거나, “if-then” 관계로 이어지는 대화 흐름.
- 무조건(Unconditional):
- 별도의 조건 없이, 그 자체로 함께 존재하거나 연결되는 경우.
- 예: 일반적인 공출(co-occurrence), 또는 상호 맥락이 없는 단순 연결.

이전 Chapter 에서 서로 다른 모달리티는 공통의 정보를 가지고 있을 수 있다고 언급하였다.
예를 들면, language grounding 가 될 수 있겠다.
“A woman”이라는 텍스트는 이미지에서 사람(여성) 객체와 연결될 수 있고, “reading”은 ‘읽는 동작’, “newspaper”는 ‘신문 객체’ 등으로 연결될 수 있음.


텍스트 토큰 “woman”이 자주 등장하는 이미지 영역이 여성의 모습이라면, 두 요소(“woman” 텍스트와 해당 이미지 영역) 간에 통계적으로 공출(co-occurrence) 하거나 상관관계(correlation) 가 높다고 볼 수 있다.
이제, Supervised Approach 를 살펴보자.
텍스트 토큰 "woman" 과 여성 이미지 객체가 대응(Correspondence)되어 contrastive learning 을 통해 positive pair 가 유사도가 높아지고 negative pair 는 유사도가 낮아지는 방향으로 학습될 것이다.

그러면, Unsupervised Approach 는 어떨까?

쌍(pair) 데이터 자체가 없는 경우가 되겠다. (예: 이미지와 텍스트가 서로 짝지어져 있지 않음)
이 경우엔 Optimal Transport(최적 운송) 기법을 사용.
- Optimal Coupling(최적 짝지음) 구하기
- 모든 삼각형(시각 임베딩)과 원(언어 임베딩)을 어떻게 매칭하면 총 비용이 가장 작아지는지 찾는 문제이다.
- 즉, $z_{A}, z_{B}$를 잇는 “연결선(커플링)”의 가중치를 최적화해 분포 간 차이를 최소화한다.
- 결과
- 이 Optimal Coupling 을 통해 같은 의미를 가질 가능성이 높은 쌍들이 자연스럽게 가까워지도록 학습된다.
Sub-Challenge 2b: Aligned Representation

- 정의
- 모든 cross-modal 연결과 상호작용을 모델링하여 더 나은 멀티모달 representation 을 얻는 것

- 모든 cross-modal 연결과 상호작용을 모델링하여 더 나은 멀티모달 representation 을 얻는 것
- 목표
- 앞 단계(Connections) 에서 어떤 element 가 어떤 element 와 대응되는지를 찾았다면, 이 단계에서는 여러 모달리티에서 얻은 정보를 통합된 형태로 정렬해 하나의 모델을 만드는 것이 목표
Aligned Representations - A Popular Approach

- Assumptions
- Segmented elements
- Image 는 객체 단위 (예: bounding box), Text 는 단어 단위 처럼, 미리 분할된 요소들을 가정
-> 이 가정에 대해서 더 많은 detail 은 다음 sub-challenge 인 Segmentations 에서 다루도록 하자.
- Image 는 객체 단위 (예: bounding box), Text 는 단어 단위 처럼, 미리 분할된 요소들을 가정
- List of elements (with position encodings)
- 각 모달리티에서 얻어진 element 들을 list 형태로 나열하고, 위치 정보를 함께 부여
ex) Image 객체 순서 + Text 토근 순서
- 각 모달리티에서 얻어진 element 들을 list 형태로 나열하고, 위치 정보를 함께 부여
- Early fusion (concatenated modalities)
- 여러 모달리티에서 나온 element 들을 하나의 sequence 로 concatenation 하여 동일한 모델 (주로 transformer) 에 입력

- 여러 모달리티에서 나온 element 들을 하나의 sequence 로 concatenation 하여 동일한 모델 (주로 transformer) 에 입력
- Segmented elements
이렇게 모달리티별 요소들을 한 줄로 연결하면, Transformer의 self-attention 메커니즘을 통해 서로 다른 모달리티 요소들 간의 크로스 어텐션이 자연스럽게 일어난다. 즉, 모델은 이미지 토큰과 텍스트 토큰 사이의 상호작용을 자동으로 학습하게 되어, 멀티모달 정렬(align) 이 내부적으로 이루어짐.
Aligned Representation - Early Fusion
Li et al., VisualBERT: A Simple and Performant Baseline for Vision and Language, arxiv 2019

- VisualBERT (Li et al., 2019)
- 이미지를 CNN 혹은 Region Proposal Network 등을 통해 객체 임베딩(벡터)으로 추출하고, 텍스트는 BERT 토크나이저로 나눈 뒤 임베딩을 얻음.
- 이미지 임베딩 + 텍스트 임베딩을 하나의 시퀀스로 합쳐서 BERT 구조(혹은 변형된 Transformer)에 입력.
- 결과적으로, 모델이 양쪽 정보를 동시에 학습하며, 텍스트와 이미지가 서로 어떻게 대응되는지 내부적으로 정렬하게 됨.
Aligned Representations - Two-Way Directional Alignment

- 두 모달리티(예: 텍스트 모델, 이미지 모델)가 서로 양방향으로 정보를 주고받으며 정렬(align)되는 개념을 보여줌.
- 한쪽에서 텍스트 임베딩을 학습하고, 다른 쪽에서 이미지 임베딩을 학습한 뒤, 서로 동일하거나 유사한 표현 공간으로 매핑.
- 결과: 텍스트와 이미지가 서로를 맞춰가며(two-way alignment) 공통 표현 또는 상호 호환되는 표현을 학습함.
Multimodal Transformer - Pairwise Cross-Modal

- 여러 모달리티(Visual, Vocal, Verbal)가 각각 Unimodal Representations(각 모달리티 전용 인코더)를 거쳐서 1차 표현을 만듦.
- 이후, Cross-Modal Attention Block을 통해, 시각 정보가 언어 정보를, 언어 정보가 시각 정보를, 음성 정보가 언어 정보를, … 식으로 서로 교차 주목(cross-attention)함.
- 이를 N개 레이어(계층) 반복하며, 점차 멀티모달 통합 표현을 완성.
Cross-Modal Transfomer Module (V->L)
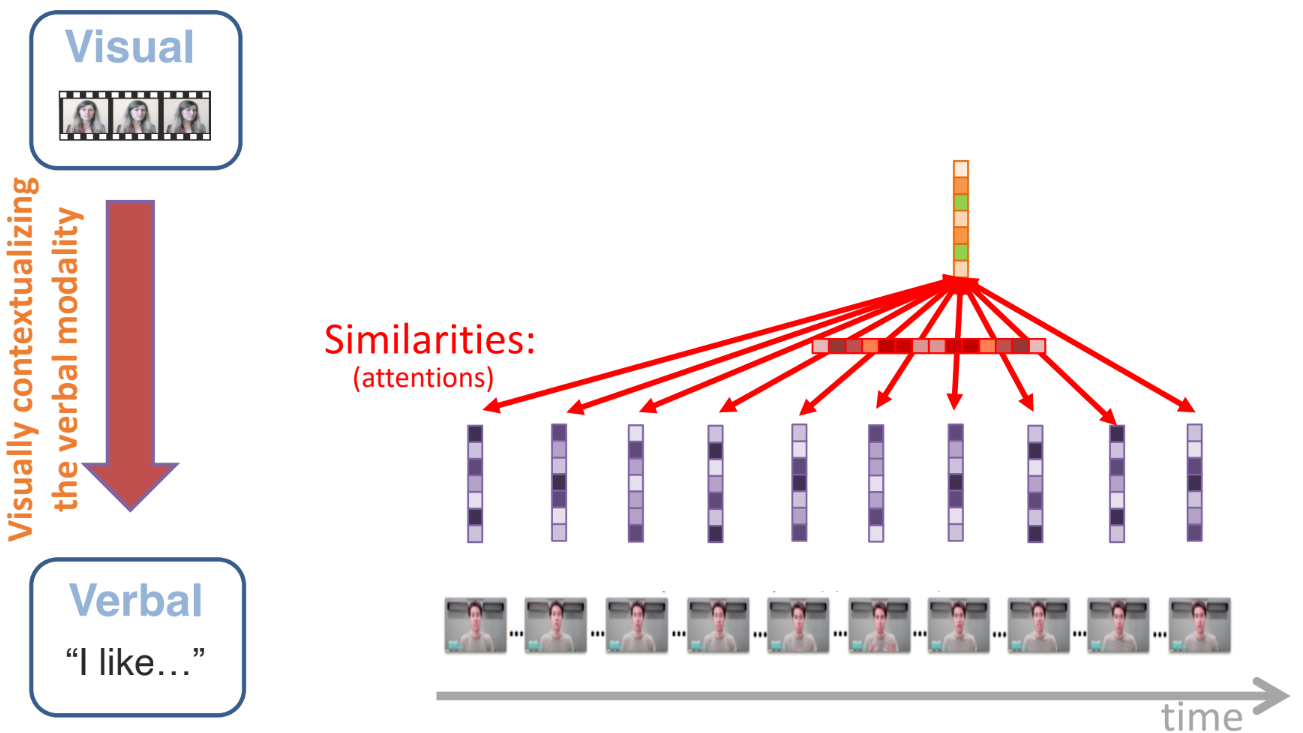
- 시각(Visual) 모달리티가 언어(Verbal) 모달리티를 맥락화(contextualize) 하는 과정.
- 예: 이미지에서 얻은 임베딩을 언어 쪽 Transformer에 공급하여, 텍스트 임베딩이 “이미지 정보를 반영한 상태”로 업데이트됨.

- 과정
- 유사도 계산(Similarities / Attentions):
- 텍스트 토큰(Verbal) 각각이 어떤 시각 임베딩(Visual)에 주목해야 하는지 어텐션으로 결정.
- Residual Connection:
- Transformer 구조 특유의 Residual Connection 을 통해, 원래 텍스트 정보 + 시각 정보가 합쳐진 새로운 표현을 생성.
- 결과:
- 텍스트가 시각적 맥락(Visual context)으로 보강된 “visually-contextualized representation of language”가 됨.
- 유사도 계산(Similarities / Attentions):
Example of Two-Way Directional Alignment - VilBERT

ViLBERT (Lu et al., 2019)은 시각(이미지) 모달리티와 언어(텍스트) 모달리티를 분리된 두 스트림(두 개의 Unimodal Transformer)으로 먼저 처리한 뒤, Cross-Modal Transformer Modules에서 서로 교차로 정보를 주고받으며 정렬(align)하는 구조를 가진다.
- 구성
- Unimodal Transformer
- 텍스트: BERT 유사 구조로 텍스트 임베딩을 학습.
- 이미지: CNN 또는 영역추출(Region Features) 등을 통해 얻은 이미지 임베딩을 Transformer로 처리.
- Cross-Modal Transformer Modules
- 텍스트 스트림과 이미지 스트림이 서로를 어텐션으로 참조하여, 양쪽 정보를 통합하고 정렬.
- 결과적으로 텍스트와 이미지가 양방향으로 서로의 정보를 반영해 최종 임베딩을 만듦.
- Unimodal Transformer
- 핵심 아이디어
- 단순히 텍스트를 이미지에 매핑하거나, 이미지를 텍스트에 매핑하는 ‘일방향’이 아니라, 양쪽 스트림이 독립적으로 학습된 뒤 서로 교차로 결합(two-way alignment)함으로써, 보다 풍부한 멀티모달 표현을 얻는다.
Example of Two-Way Directional Alignment - Lxmert

LXMERT (Tan et al., 2019) 역시, Language Encoder와 Object-Relationship Encoder(이미지 객체 관계를 처리하는 인코더)를 각각 사용한 뒤, Cross-Modality Encoder에서 두 모달리티를 합친다.
- 구성
- Language Encoder
- 텍스트를 Transformer로 처리해 언어 임베딩을 생성.
- Object-Relationship Encoder
- 이미지 속 객체들을 인식하고, 객체들 간 관계(위치·속성 등)를 Transformer로 학습.
- Cross-Modality Encoder
- “Cross” 블록(교차 어텐션)과 “Self” 블록(자기 어텐션)을 번갈아 적용해, 언어와 이미지를 서로 정렬.
- 최종적으로 멀티모달 표현(vision output, language output)을 산출.
- Language Encoder
- 핵심 아이디어
- ViLBERT와 마찬가지로, 각 모달리티를 먼저 별도로 학습한 후, 중간 단계에서 크로스 어텐션을 통해 상호 정보를 교환함으로써 양방향 정렬을 수행한다.
Aligned Representation with Graph Networks
멀티모달 데이터를 그래프로 나타내고, 그래프 신경망(GNN, Graph Neural Network) 을 활용해 정렬된 표현을 얻는 방법을 소개한다.

- 장점
- 모든 요소가 꼭 서로 직접 연결(edge)되어 있을 필요가 없음.
- 필요에 따라 중요한 요소들만 연결할 수 있어 유연함.
- 모달리티별 혹은 시간적 의존성별로 다양한 종류의 간선(edge function)을 정의할 수 있음.
- 예: 이미지 객체 간 위치 관계, 텍스트 토큰 간 문법 관계, 시계열 데이터 간 시간 관계 등.
- 모든 요소가 꼭 서로 직접 연결(edge)되어 있을 필요가 없음.
- 핵심 아이디어
- 이미지, 텍스트, 오디오 등 다양한 모달리티 요소들을 노드로 두고, 이들 사이의 관계(공간적, 의미적, 시간적 등)를 간선으로 표현한 뒤, GNN을 통해 노드 임베딩을 학습함으로써 멀티모달 정렬을 달성한다.
Graph Nerual Nets (GNN)

- Key idea
- 주변 노드(이웃) 정보를 반복적으로(재귀적으로) 받아들여 각 노드의 임베딩을 갱신.
- Multiple Layers

- Layer 0: 초기 입력(노드별 임베딩, 예: 이미지 객체 특징, 텍스트 토큰 임베딩 등).
- Layer 1: 이웃 노드 임베딩을 합성(aggregate)해 새로운 임베딩을 생성.
- Layer 2, 3, …: 계속해서 더 넓은 범위의 이웃 정보를 통합하여, 점차 풍부한 노드 표현을 얻음.
- 각 레이어는 동일한 파라미터(공유)나 유사한 구조를 사용해 계층적으로 노드 표현을 업데이트함.
GNN 을 활용했을 때에는 모든 요소를 일렬로 펼치거나(시퀀스), 전체를 Fully-Connected로 묶지 않고도, 의미 있는 연결만 골라 그래프로 구성할 수 있다는 장점이 있겠다.
그렇다면, GNN 에서 노드가 이웃 노드의 embedding 을 어떻게 모아서(Aggregate) 자신의 embedding 으로 업데이트하는지를 살펴보자.
Key Technical Challenge : Neighborhood Aggregation

- Average Pooling (Scarselli et al., 2005)
- 노드 $v$의 새 임베딩 $h_{v}^{(k)}$를 만들 때, 이웃 노드 $h_{u}^{(k-1)}$ 들의 임베딩을 단순 평균하여 결합하는 방식.
- 이웃 노드와 자기 자신에게 각각 다른 가중치를 줄 수도 있음(“Different weights for neighbors and self”).
- 구현이 매우 간단하지만, 모든 이웃을 동일하게 취급하므로 구분 없이 평균내는 한계가 있음.
- Graph Convolution Network (Kipf et al., 2017)
- GCN에서 제안된 스펙트럼 그래프 합성곱 개념을 사용해, $\mathcal{A}$ (인접 행렬)를 기반으로 노드 임베딩을 업데이트.
- “Same weights for neighbors and self”라 적혀 있는데, 이는 간단한 GCN 공식에서 모든 이웃 노드에 동일 가중치를 적용(단, 정규화 계수(노드 차수)에 의해 조정)한다는 의미.
- $h_{v}^{(k)}$ 를 계산할 때, 이웃 임베딩들의 평균 또는 정규화된 합을 구한 뒤, 가중치 $\mathcal{W}$를 곱하고 활성화 함수를 취함.
- Graph Attention Network (Veličković et al., 2018)
- GAT에서는 이웃 노드마다 다른 중요도(attention weight)를 부여해, 더 중요한 이웃의 임베딩을 더 많이 반영.
- $\alpha_{v, u}$라는 어텐션 계수가 각 이웃 $u$와의 연결에 대해 계산되며, $\alpha_{v, u}$가 클수록 노드 $가 노드 $의 업데이트에 더 크게 기여.
- 이는 셀프 어텐션(self-attention) 방식과 유사해, Transformer 아이디어를 그래프에 적용한 형태.
- 정리
- GNN의 핵심인 “노드 업데이트” 과정에서, 이웃 임베딩들을 어떻게 집계(Aggregate)하고 가중치(Weight)를 주느냐에 따라 여러 변형 기법이 탄생.
- Average Pooling → GCN → GAT 순으로 점점 더 정교한 가중치 부여 방식을 취한다고 볼 수 있음.
아래는 멀티모달 시계열(예: 텍스트, 오디오, 비디오)이 있을 때, 각 모달리티에서 나온 요소들을 그래프로 구성하고, 시점(시간축) 상의 연결까지 고려해 학습하는 예시를 보여준다.
Modal-Temporal Attention Graph

- 구성
- Node Construction (노드 구성)
- 비디오(Video): 프레임 단위, 혹은 샷(clip) 단위로 특징(임베딩)을 추출해 노드로 만듦.
- 오디오(Audio): 음성 신호를 일정 단위(프레임, 발화 등)로 나누어 중립(neutral), 강조(emphasis) 같은 음성 특징을 FFN(Feed-Forward Network)으로 처리한 뒤, 노드로 만듦.
- 텍스트(Text): 단어 단위(“It”, “was”, “a”, “very”, …) 임베딩을 FFN이나 Transformer로 처리한 뒤, 노드로 만듦.
- 각 모달리티별 노드들이 시간 순서에 따라 배치될 수 있음(시계열 데이터).
- Edge Construction (간선 구성)
- Modal edges: 같은 모달리티 내에서, 시간적으로 인접한 노드들을 연결(예: 텍스트 단어 간 연결, 비디오 프레임 간 연결, 오디오 프레임 간 연결).
- Cross-modal edges: 서로 다른 모달리티 간 대응 가능성이 있는 노드들을 연결(예: 특정 텍스트 단어와 그 시점의 오디오 특징, 비디오 프레임과 텍스트 등).
- 이렇게 모달리티 + 시간 축을 모두 고려해 그래프를 만들면, GNN을 통해 멀티모달·시계열 정보를 통합하여 학습할 수 있음.
- Node Construction (노드 구성)
- 핵심 아이디어
- 모달리티별로 시점에 따라 노드를 만들고, 시간축을 따라 간선을 연결(Temporal)하며, 필요하면 모달리티 간에도 간선을 추가.
- GNN(혹은 Graph Attention Network)을 적용해, 각 노드(특정 시점의 텍스트, 오디오, 비디오 특징)가 이웃 노드들로부터 정보를 받아 업데이트하게 됨.
- 결과적으로, 텍스트, 오디오, 비디오가 시간적으로 어떻게 상호작용하는지(“누가, 언제, 무엇을 말했는지”)를 그래프 구조로 명시적으로 표현하여 학습 가능.
Challenge 2c : Segmentation

- 정의
- 정렬(alignment) 과정에서 발생하는 세분화(분할) 문제를 다루며, 각 요소가 어느 정도의 크기(Granularity) 로 나뉘어야 하는지 결정하고, 모호성을 처리하는 것을 목표로 한다.
- 예시

- Medical imaging: 뇌의 특정 부위(예: 활성화 영역)를 어떻게 나눌 것인가?
- Signals: 음성 신호나 센서 신호를 어떤 단위로 분할할 것인가? (음소, 단어, 프레임 등)
- Images: 이미지 내 객체(object) 단위로 나누거나, 픽셀 단위로 세분화할 수도 있음.
Alignment and Segmentation - A Simple Approach

- Dynamic Time Warping(DTW): 시계열 데이터를 서로 맞추는(align) 대표적 방법 중 하나.
- 정의
- 두 시퀀스$(x^{T}, y^{T})$가 길이가 다를 때, 최소 비용(distance) 를 갖는 mapping 을 찾아내어 정렬(워핑)하는 알고리즘
- 예시
- 음성 신호(Phonemes)와 스펙트로그램(Spectrogram) 간 정렬
- 여러 프레임의 동작(제스처) 시퀀스를 다른 길이의 시퀀스와 맞추기
- 원리
- 동적 프로그래밍(DP) 를 통해 두 시퀀스 간 누적 거리(cost) 를 최소화하는 경로를 찾음.
- 결과적으로 "many-many mapping" 이 가능해짐
- 예: 음성 프레임이 't' 음소에 해당하는 구간, 'a' 음소에 해당하는 구간 등을 자동으로 찾아냄.
- 핵심 아이디어
- 사전 라벨 없이도, 두 시계열 간 시간축 왜곡(속도 차이 등)을 허용하면서 정렬할 수 있다는 장점이 있음
- 다만, 큰 규모 데이터나 복잡한 멀티모달 상황에서는 계산량이 많아질 수 있어, 다른 기법들과 병행, 보완하는 경우가 많음.
- 정의
Alignment and Segmentation - A Classification Approach

- Connectionist Temporal Classification(CTC)
- 정의
- RNN (또는 다른 시퀀스 모델) 출력 시퀀스를 레이블 시퀀스(음소, 단어 등)와 맞추기 위해 사용하는 손실 함수/알고리즘
- 과정
- Output activations : 모델이 매 시점마다 각 음소(또는 클래스)에 대한 확률분포를 출력
- Path $\pi$ : 각 시점별 어떤 클래스가 활성화됐는지가 결정됨
- Predicted labels $\mathcal{l}$ : $\pi$ 경로를 압축(연속된 같은 레이블을 하나로)하여 최종 예측 시퀀스를 얻음
- Most probable sequence labels : 전체 시퀀스 중 최대 가능도를 갖는 레이블 시퀀스가 최종 결과
- 핵심 아이디어
- 레이블이 없는 연속 신호(예: 스펙트로그램)에 대해, “이 구간은 음소 ‘t’, 이 구간은 ‘a’”처럼 정확한 구분선을 제공하지 않아도, CTC가 가장 그럴듯한 분할(세그멘테이션) + 레이블링을 찾아냄.
- 음성 인식, 제스처 인식 등 시계열 데이터의 자동 정렬·분할·레이블링에 널리 사용되는 기법.
- 정의
Representation and Segmentation - Cluster-based Approaches
HuBERT (Hidden-Unit BERT)는 음성 신호를 자기지도학습(self-supervised learning) 방식으로 학습하는 대표적 모델 중 하나이다.

- 동작 방식
- Speech → Transformer(Self-Attention)로 인코딩
- K-means Clustering: 모델 출력을 여러 클러스터(C1, C2, C3 등)로 나누어, 각 프레임(또는 단위)마다 어떤 클러스터에 속하는지 “가짜 레이블”로 사용
- Masking & Prediction: 마치 BERT가 단어를 마스킹하고 예측하듯, 음성 프레임 일부를 마스킹하고, 모델이 해당 클러스터 레이블을 예측하도록 학습
- 결과
- 음성 신호가 자동으로 의미 있는 단위(유사한 발음·음소 등)로 분할되고, 각 단위가 클러스터로 정렬됨.
- 이렇게 학습된 표현(Representation) 은 음성 인식, 화자 분류, 감정 분석 등 여러 음성 관련 태스크에서 뛰어난 성능을 보임.
'연구실 > 멀티모달' 카테고리의 다른 글
| [Multimodal] 02. Representation (0) | 2025.02.06 |
|---|---|
| [Multimodal] 01. Introduction (0) | 2025.01.20 |

