목차
- Process Management
- Memory Management
- File Management
- I/O System Management
- Networking
- Security
프로그램이 만들어지는 과정은 아래와 같다.

Compiler
: 사람이 이해할 수 있는 프로그래밍 언어로 작성된 Source Code 를 컴퓨터(CPU) 가 이해할 수 있는 기계어로 표현된 Object 파일로 변환
- Source Code (c file) : 프로그램이 수행하고자 하는 작업이 프로그래밍 언어로 표현되어 있음
- Object file (o file) : 컴퓨터 (CPU) 가 이해할 수 있는 기계어로 구성된 파일
- 자체로는 수행이 안됨
- 프로세스로 변환되기 위한 정보가 삽입되어야 함
- Relocatable Addresses (Relative Address) 로 표현 : symbol 주소가 상대적인 값으로 표현됨
ex) 시작 주소로부터 26 byte 지점
- Cross Compiler : 한 platform 에서 다른 platform 용 실행 파일을 생성하는 compiler
ex) x86 기반 컴퓨터에서 ARM 기반 기기의 실행 파일을 생성

Source Code -> Cross Compiler -> Target Platform executable file (예 : a.out)
Compilation vs. Translation

컴파일러와 인터프리터 모두 high-level language를 machine language로 번역한다. 컴파일러는 소스 코드(high-level language로 작성) 전체를 링커 등을 통해 한번에 번역하여 목적 파일(기계어로 작성)로 만들어 메모리상에 적재한다.
인터프리터는 소스 코드를 한 행씩 중간 코드로 번역 후 실행한다.
- 컴파일러는 소스코드 전체를 컴퓨터 프로세서가 실행할 수 있도록 바로 기계어로 변환한다. 인터프리터는 고레벨 언어를 중간 코드(intermediate code)로 변환하고 이를 각 행마다 실행한다.
- 일반적으로 컴파일러가 각 행마다 실행하는 특성을 가진 인터프리터보다는 실행시간이 빠르다.
- 컴파일러는 전체 소스코드를 변환 한 뒤 에러를 보고하지만 인터프리터는 각 행마다 실행하는 도중 에러가 보고되면 이후 작성된 코드를 살펴보지 않는다. 이는 보안적인 관점에서 도움이 된다.
ex) 파이썬은 인터프리트 언어이고 C, C++는 컴파일 언어이다. 자바는 컴파일러와 인터프리터 모두 사용
- Rosetta 의 번역 한계
- 대부분의 intel 기반 앱과 JIT 컴파일러를 포함하는 앱을 번역할 수 있지만, kernel extension 과 x86_64 컴퓨터 platform 을 virtualize 하는 가상 머신 앱을 번역하지는 못한다.
Linker
: Object file 들과 library 들을 연결하여, memory 로 load 될 수 있는 하나의 executable file 로 변환한다.
- Executable (exe file)
- 특정한 환경(OS) 에서 수행될 수 있음
- process 로의 변환을 위한 Header, 작업 내용인 Text, 필요한 데이터인 Data 를 포함
- Absolute Addresses 로 표현
Loader
: Executable file 을 실제 memory 에 올려주는 역할
- Executable 의 Header 를 읽어, Text 와 Data 의 크기를 결정
- 프로그램을 위한 Address Space 를 생성
- 실행 명령어와 Data 들을 Executable 로부터 생성한 Address Space 로 복사
- 프로그램의 argument 들을 stack 으로 복사
- CPU 내 Register 를 초기화하고, Start-up Routine (프로그램 시작 지점) 으로 Jump 하여 실행 시작
Program 이 process 가 되어 memory 에 load 되기 위해서 process 는 input queue 에서 대기한다. input queue 에서 대기하던 process 중 선택된 process 는 main memory 에 load 되고, process 가 execute 할 때, 해당 main memory 에서 명령어와 데이터를 사용한다.
Process 의 address 를 어느 시점에 어떻게 할당해줄 것인지에 (Symbolic address -> Logical Address -> Physical Address) 에 대해 결정해주는 것이 Address Binding 이다. 이에 대한 자세한 설명은 이후에 다시 다루기로 한다.
Runtime System
: 프로그램의 실행을 지원하고, 효율성을 보장하기 위해, 프로그램과 운영 체제 간의 연결을 담당한다.

- C Runtime System Program Execution
- GCC 컴파일러는 Start-up Code Object file 을 추가하여 program 을 comfile 하며, 이 때 기본 library 들도 동적으로 링킹된다.
- process 를 시작하기 위해 kernel 은 program counter (다음에 실행될 명령어의 주소를 가지고 있는 register)를 _start 함수의 주소로 지정한다. // queue 구조를 사용
- _start 함수는 동적으로 링킹된 C library 및 thread 환경을 초기화하기 위해 _libc_start_main 함수를 호출한다.
- library 초기화를 진행한 이후, 프로그램의 main 함수가 호출된다.
Process
- Execution Unit : 스케줄링의 단위
- Protection Domain : 서로 침범하지 못함
- Program Counter, Stack, Data section 을 통해 구현된다.
- disk 에 저장된 program 으로부터 변환되어 memory 로 loading 된다.

- Text Segment
- 실행 명령어가 저장된 공간
- PC 와 Process 의 레지스터 내용을 포함
- 읽기 전용으로 설정되어 변경을 방지
- Data Segment
- 초기화된 전역 변수와 상수가 저장
- 읽기-쓰기 권한을 가짐
- BSS (Block Started by Symbol)
- 정적으로 할당된 초기화되지 않은 변수를 포함
- Heap
- 동적 메모리 할당(malloc, new)에 사용
- Stack
- 함수 호출 및 지역 변수 저장
각 process 는 protection domain 을 통해 memory 접근이 제한된다.

Process Execution in xv6
- Xv6 code exec.c
exec() 시스템 호출은 사용자의 주소 공간을 초기화하고, 파일 시스템에 저장된 실행 파일을 읽어와 메모리에 로드하는 작업을 수행한다. 아래 코드를 살펴보자.
#include "types.h"
#include "param.h"
#include "memlayout.h"
#include "mmu.h"
#include "proc.h"
#include "defs.h"
#include "x86.h"
#include "elf.h"
int
exec(char *path, char **argv)
{
char *s, *last;
int i, off;
uint argc, sz, sp, ustack[3+MAXARG+1];
struct elfhdr elf;
struct inode *ip;
struct proghdr ph;
pde_t *pgdir, *oldpgdir;
struct proc *curproc = myproc();
begin_op();
if((ip = namei(path)) == 0){
end_op();
cprintf("exec: fail\n");
return -1;
}
ilock(ip);
pgdir = 0;
// Check ELF header
if(readi(ip, (char*)&elf, 0, sizeof(elf)) != sizeof(elf))
goto bad;
if(elf.magic != ELF_MAGIC)
goto bad;
if((pgdir = setupkvm()) == 0)
goto bad;
// Load program into memory.
sz = 0;
for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){
if(readi(ip, (char*)&ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if(ph.type != ELF_PROG_LOAD)
continue;
if(ph.memsz < ph.filesz)
goto bad;
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
if((sz = allocuvm(pgdir, sz, ph.vaddr + ph.memsz)) == 0)
goto bad;
if(ph.vaddr % PGSIZE != 0)
goto bad;
if(loaduvm(pgdir, (char*)ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}
iunlockput(ip);
end_op();
ip = 0;
// Allocate two pages at the next page boundary.
// Make the first inaccessible. Use the second as the user stack.
sz = PGROUNDUP(sz);
if((sz = allocuvm(pgdir, sz, sz + 2*PGSIZE)) == 0)
goto bad;
clearpteu(pgdir, (char*)(sz - 2*PGSIZE));
sp = sz;
// Push argument strings, prepare rest of stack in ustack.
for(argc = 0; argv[argc]; argc++) {
if(argc >= MAXARG)
goto bad;
sp = (sp - (strlen(argv[argc]) + 1)) & ~3;
if(copyout(pgdir, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[3+argc] = sp;
}
ustack[3+argc] = 0;
ustack[0] = 0xffffffff; // fake return PC
ustack[1] = argc;
ustack[2] = sp - (argc+1)*4; // argv pointer
sp -= (3+argc+1) * 4;
if(copyout(pgdir, sp, ustack, (3+argc+1)*4) < 0)
goto bad;
// Save program name for debugging.
for(last=s=path; *s; s++)
if(*s == '/')
last = s+1;
safestrcpy(curproc->name, last, sizeof(curproc->name));
// Commit to the user image.
oldpgdir = curproc->pgdir;
curproc->pgdir = pgdir;
curproc->sz = sz;
curproc->tf->eip = elf.entry; // main
curproc->tf->esp = sp;
switchuvm(curproc);
freevm(oldpgdir);
return 0;
bad:
if(pgdir)
freevm(pgdir);
if(ip){
iunlockput(ip);
end_op();
}
return -1;
}
- 주요 변수
- path : 실행할 binary 파일 경로
- argv : 실행 시 전달할 명령어 인자
- elf : ELF 파일의 헤더를 저장하는 구조체
- elfhdr : 실행 파일의 ELF 헤더를 저장
- progphr : ELF 프로그램의 헤더를 저장
- ustack : 사용자 스택 초기화에 사용되는 임시 배열
- ph : 프로그램 헤더(program header) 를 저장하는 구조체
- pgdir : 페이지 디렉터리
- curproc : 현재 실행 중인 프로세스를 나타내는 구조
- phoff : 프로그램 헤더 테이블의 시작 위치(오프셋)
- phnum : 프로그램 헤더 개수
- 코드 흐름 분석
- 파일 검색 및 잠금
begin_op();
if((ip = namei(path)) == 0) {
end_op();
cprintf("exec: fail\n");
return -1;
}
ilock(ip);
pgdir = 0;- namei(path) : 주어진 경로를 통해 해당 파일의 inode 를 가져온다. 파일이 존재하지 않을 경우 NULL 반환
- ilock(ip) : 파일 시스템에서 해당 파일을 잠근다. 다른 process 가 이 파일을 수정하거나 삭제하지 못하게 한다.
- ELF 헤더 검증
if(readi(ip, (char*)&elf, 0, sizeof(elf)) != sizeof(elf))
goto bad;
if(elf.magic != ELF_MAGIC)
goto bad;- readi (ip, (char*)&elf, 0, sizeof(elf)) : 실행 파일에서 ELF 헤더를 읽어 elf 구조체에 저장
- elf.magic != ELF_MAGIC : ELF 헤더의 매직 넘버를 확인하여 올바른 ELF 파일인지 검증
- 새로운 페이지 디렉터리 생성
if((pgdir = setupkvm()) == 0)
goto bad;- setupkvm() : 새로운 커널 가상 메모리 페이지 디렉터리를 생성해서 사용자 주소 공간의 초기화에 사용한다.
- 프로그램 메모리 로드
for(i = 0, off = elf.phoff; i < elf.phnum; i++, off += sizeof(ph)) {
if(readi(ip, (char*)&ph, off, sizeof(ph)) != sizeof(ph))
goto bad;
if(ph.type != ELF_PROG_LOAD)
continue;
if(ph.memsz < ph.filesz)
goto bad;
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
if((sz = allocuvm(pgdir, sz, ph.vaddr + ph.memsz)) == 0)
goto bad;
if(ph.vaddr % PGSIZE != 0)
goto bad;
if(loaduvm(pgdir, (char*)ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad;
}- 작업
- 반복문에서 ELF 파일에 포함된 여러 프로그램 헤더를 순회하며 각 세그먼트를 메모리에 적재하는 데 사용한다.
- ELF 프로그램 헤더를 읽어 프로그램의 각 segment 를 메모리에 적재
- allocuvm() : 사용자 메모리 공간을 할당
- loaduvm() : 파일 내용을 사용자 메모리에 복사
- 조건 검사
- ph.type != ELF_PROG_LOAD: 실행 가능한 세그먼트만 메모리에 로드
- segment 크기 (memsz >= filesz), 정렬 조건(vaddr % PGSIZE == 0) 등을 검증
- 사용자 스택 설정
sz = PGROUNDUP(sz);
if((sz = allocuvm(pgdir, sz, sz + 2*PGSIZE)) == 0)
goto bad;
clearpteu(pgdir, (char*)(sz - 2*PGSIZE));
sp = sz;- clearpteu() : 페이지 테이블 엔트리에서 사용자 접근 권한을 제거
- sp = sz : 스택 포인터를 두 번째 페이지의 최상단으로 설정
- 명령줄 인자 복사
for(argc = 0; argv[argc]; argc++) {
if(argc >= MAXARG)
goto bad;
sp = (sp - (strlen(argv[argc]) + 1)) & ~3;
if(copyout(pgdir, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[3+argc] = sp;
}
ustack[3+argc] = 0;
ustack[0] = 0xffffffff; // fake return PC
ustack[1] = argc; // 인자 개수
ustack[2] = sp - (argc+1)*4; // argv 배열 포인터
- sp - (strlen(argv[argc]) + 1):
- 문자열의 길이만큼 스택 포인터를 아래로 이동.
- 추가로 +1을 사용해 문자열 종료 문자(\0) 포함.
- & ~3:
- 스택을 4바이트 정렬(Alignment)합니다. 메모리 정렬을 통해 성능을 최적화.
- copyout():
- 커널에서 사용자 공간으로 데이터를 복사.
- 명령줄 인자 문자열을 사용자 스택에 복사.
- 스택에 추가로 다음 데이터를 초기화
- ustack[0]: 가짜 반환 주소 (return PC). 함수 호출에서 돌아오지 않도록 설정.
- ustack[1]: 명령줄 인자 개수 (argc).
- ustack[2]: 명령줄 인자 배열의 포인터 (argv).
- ustack[3+argc] : argv 배열의 끝을 나타내는 NULL 포인터 (0으로 무한 루프 방지)
- 스택 복사
sp -= (3+argc+1) * 4;
if(copyout(pgdir, sp, ustack, (3+argc+1)*4) < 0)
goto bad;
- sp -= (3 + argc + 1) * 4
- 스택 포인터(sp)를 현재 위치에서 데이터 크기만큼 감소시켜, 새로운 데이터가 저장될 공간을 확보.
- 데이터는 스택의 최상단에 저장되므로, 스택 포인터를 아래로 이동시킴(스택은 위에서 아래로 성장).
- (3 + argc + 1) * 4: 스택에 저장할 데이터의 전체 크기를 계산
- 예제
./program arg1 arg2- ustack[0] : 0xffffffff
- ustack[1] : 3 (argc)
- ustack[2] : argv 배열의 시작 주소.
- ustack[3] : "./program"의 주소
- ustack[4] : "arg1"의 주소
- ustack[5] : "arg2"의 주소
- ustack[6] : NULL (배열 끝)
(3 + argc + 1) * 4
= (3 + 3 + 1) * 4
= 7 * 4
= 28 바이트+---------------------+ <- 스택 최상단 (sp 초기값)
| NULL | <- `ustack[6]`
+---------------------+
| "arg2" 주소 | <- `ustack[5]`
+---------------------+
| "arg1" 주소 | <- `ustack[4]`
+---------------------+
| "./program" 주소 | <- `ustack[3]`
+---------------------+
| argv 시작 주소 | <- `ustack[2]`
+---------------------+
| argc 값 | <- `ustack[1]`
+---------------------+
| Fake Return PC | <- `ustack[0]`
+---------------------+
- 프로그램 이름 저장
// Save program name for debugging.
for(last=s=path; *s; s++)
if(*s == '/')
last = s+1;
safestrcpy(curproc->name, last, sizeof(curproc->name));- 작업
- 문자열 path를 순회하며 가장 마지막에 등장하는 / 문자를 찾는다. 마지막 / 이후의 문자열이 프로그램의 이름이 된다. 루프가 끝나면 last 는 프로그램 이름의 시작 위치를 가리킨다.
- sfaestrcpy (curproc->name, last, sizeof(curproc->name)) : 복사할 문자열의 크기를 초과하지 않도록 안전하게 복사한다.
- 사용자 이미지 커밋
// Commit to the user image.
oldpgdir = curproc->pgdir;
curproc->pgdir = pgdir;
curproc->sz = sz;
curproc->tf->eip = elf.entry; // main
curproc->tf->esp = sp;
switchuvm(curproc);
freevm(oldpgdir);
return 0;- 오류 처리 블록
bad:
if(pgdir)
freevm(pgdir);
if(ip){
iunlockput(ip);
end_op();
}
return -1;
Process State
- New : Process 생성 중
- Running : CPU 에서 실행 중
- Waiting : 특정 이벤트(I/O 완료 등)를 대기 중
- Ready : 실행 준비 완료
- Terminated : 실행 종료
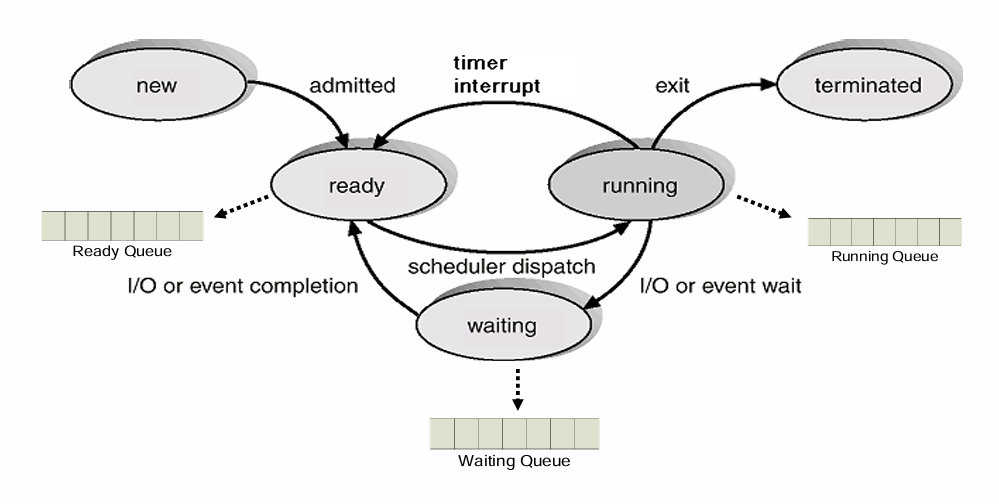
위의 그림과 같이 kernel 내에 Ready Queue, Waiting Queue, Running Queue 를 두고 Process 들을 상태에 따라 관리.
- 기본 흐름 : new -> ready -> ready queue -> scheduler dispatch -> running
Process State in xv6
- xv6 proc.h
enumprocstate { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// Per-process state
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table
char *kstack; // Bottom of kernel stack for this process
enumprocstate state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall
struct context *context; // swtch() here to run process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};- enum procstate
- UNUSED : 사용되지 않은 상태
- EMBRYO : 프로세스가 생성 중인 상태
- SLEEPING : 실행을 멈추고 이벤트를 기다리는 상태
- RUNNABLE : 실행 가능하지만 CPU 가 아직 할당되지 않은 상태
- RUNNING : 현재 CPU 에서 실행 중인 상태
- ZOMBIE : 종료되었지만 부모 프로세스가 아직 리소스를 회수하지 않은 상태
- proc 구조체
- sz : 프로세스 메모리 크기
- pgdir : 페이지 디렉토리
- kstack : kernel 스택
- state : 현재 프로세스 상태
- pid : 프로세스 id
- parent : 부모 프로세스
- tf : CPU 레지스터 상태 저장
- context : kernel thread 에서의 실행 상태 저장
- chan : 프로세스가 대기하는 채널(이벤트)
- name : 디버깅용으로 프로세스 이름 저장
Process Control Block (PCB)
- OS 가 각 프로세스를 관리하기 위해 사용하는 데이터 구조
- xv6 에서는 struct proc 가 PCB 역할을 한다
- PCB 에 저장되는 정보
- 프로세스 상태
- 프로그램 카운터 : 다음에 실행될 명령어의 주소를 가지고 있는 register
- CPU 레지스터 값
- CPU 스케줄링 정보
- 메모리 관리 정보
- 입출력 상태 정보
- 열린 파일 목록
Context Switch
- CPU 가 한 프로세스에서 다른 프로세스로 전환될 때 발생
- 현재 프로세스의 실행 상태를 저장(기존 프로세스 상태 저장)하고, 새 프로세스의 저장된 상태를 복구 (새로운 프로세스 로드)
- context switching 오버헤드
- CPU 가 유용한 작업을 수행하지 못하는 시간
- 하드웨어 지원 여부에 따라 속도가 결정됨
프로세서 구조에 따른 Context Switching 차이
- CISC
- 복잡한 명령어 지원
- 실행 속도가 느릴 수 있음
ex) Intel Pentium Processor
- RISC
- 간단한 명령어 집합
- 실행 속도가 빠름
- 레지스터 윈도우를 사용하여 context switching 속도를 높임
ex) ARM Processor

위의 2가지 개념은 CPU(중앙처리장치) 를 설계하는 방식이다. CPU가 작동하려면 프로그램이 있어야 하고 명령어를 주입해서 설계를 한다.
- 일반적인 레지스터 교체 방식 (CISC):
- 기존 CISC 프로세서에서는 함수 호출 시 레지스터 값을 스택에 저장하고, 복구할 때 다시 로드해야 한다.
- 이 과정은 시간이 많이 소요되고, 문맥 전환 오버헤드의 주요 원인이 된다.
- 레지스터 윈도우 방식 (RISC):
- 레지스터 윈도우를 사용하면 스택에 데이터를 저장하지 않고, 물리적 레지스터에서 윈도우 포인터만 변경하여 새로운 레지스터 세트를 활성화한다.
- 그림에서 보이는 슬라이딩 윈도우 방식으로, 함수 호출 시 새로운 레지스터 세트를 활성화하고, 이전 세트와 중첩 영역을 통해 데이터를 전달한다.
Context Switch 도식

- 동작 흐름
- 프로세스 $P_{0}$ 실행 중 시스템 콜 또는 인터럽트 발생
- 프로세스 $P_{0}$ 의 상태 저장 (PCB 에 저장)
- 프로세스 $P_{1}$ 의 상태 복구 (PCB 에서 복구)
- 프로세스 $P_{1}$ 실행
- 반복 . . .
Quantifying Context Switch Overhead
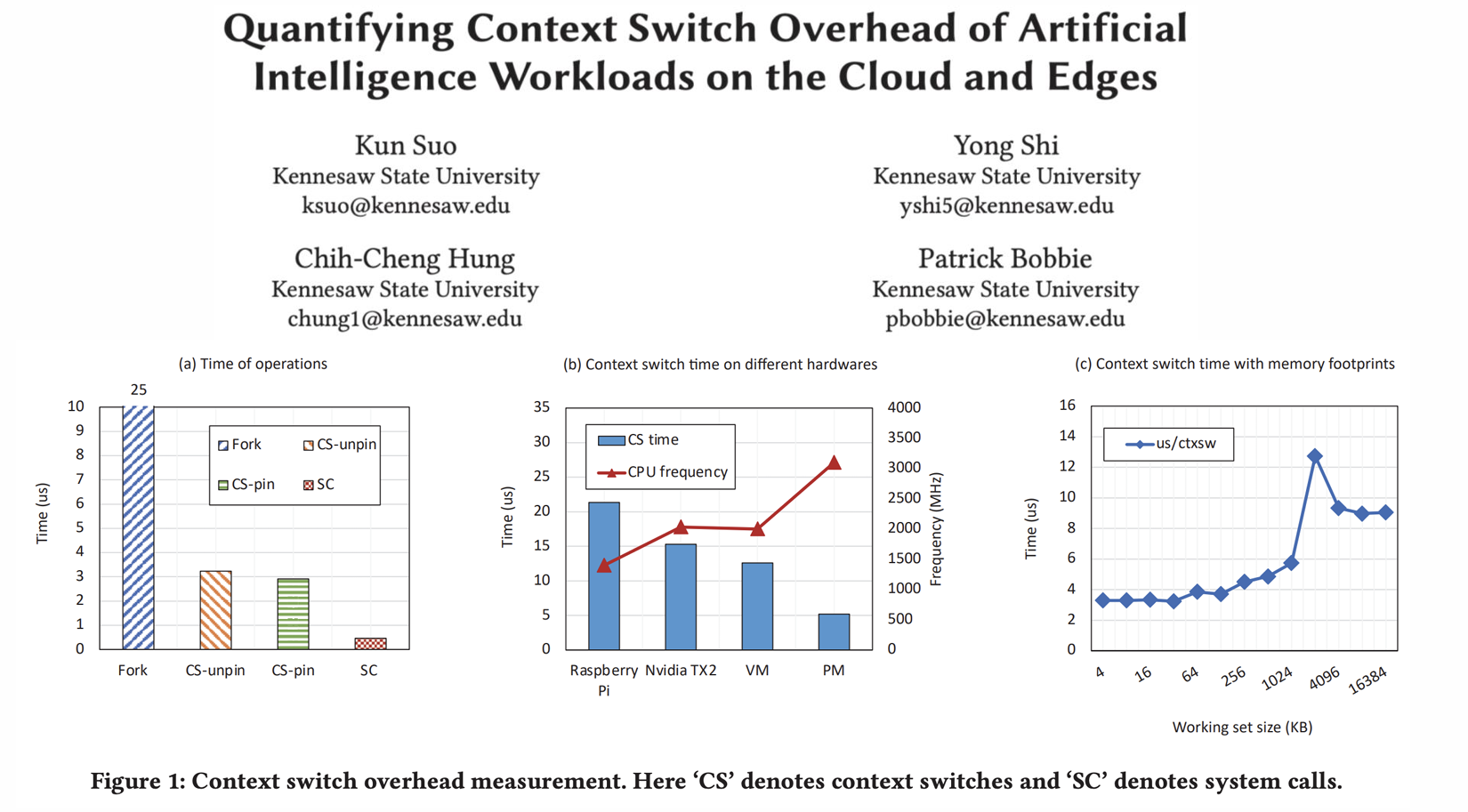
- 인공지능 워크로드(클라우드와 엣지 환경)에서 문맥 전환의 성능 영향을 분석.
- 클라우드와 엣지 환경에서 문맥 전환 비용이 다르게 나타남.
- Cloud vs. Edge
- 클라우드에서는 context switching 비용이 낮은 반면, 엣지 디바이스에서는 비용이 높음
=> 워크로드 특성에 따라 오버헤드가 달라짐
- 클라우드에서는 context switching 비용이 낮은 반면, 엣지 디바이스에서는 비용이 높음

위 그래프는 lmbench라는 벤치마크 도구를 사용하여 문맥 전환(Context Switch) 및 비문맥 전환(Non-Context Switch)의 오버헤드를 평가한 결과를 나타낸다. 그래프는 데이터 크기와 쓰레드 수에 따라 오버헤드를 분석하며, 문맥 전환과 관련된 성능 영향을 비교한다.
- Non-Context Switch의 경우 데이터 크기가 크면 일정한 오버헤드가 발생하며, 쓰레드 수 증가에 따른 영향은 미미
- Context Switch의 오버헤드는 데이터 크기와 쓰레드 수가 증가함에 따라 선형적으로 증가한다.
- 데이터 크기가 클수록 쓰레드 수 증가에 따른 오버헤드가 더 명확하게 나타난다.

(a) Image Recognition Applications
- Process switch (파란 선):
- 문맥 전환 빈도가 시간에 따라 크게 변화하며, 특정 시간 구간에서 18,000/s 이상의 높은 빈도를 기록.
- AI 워크로드가 다양한 프로세스 간 전환을 자주 요구하는 경우, 문맥 전환 횟수가 급증.
- 예를 들어, MobileNet v2와 같은 워크로드에서는 문맥 전환 빈도가 낮고, VGG16과 같은 더 복잡한 네트워크에서는 문맥 전환 빈도가 크게 증가.
- CPU utilization (주황 선):
- CPU 사용률은 문맥 전환과 상관없이 일정하게 유지되며, 약 30% ~ 50% 사이.
- 복잡한 네트워크가 실행될 때도 CPU 사용률이 상대적으로 낮게 유지됨. 이는 AI 워크로드가 GPU 중심적이고, CPU는 주로 제어 및 관리 작업을 수행하기 때문.
(b) Image Processing and Object Segmentation Applications
- Process switch (파란 선):
- 문맥 전환 빈도가 구간별로 큰 변화를 보이며, 특정 시간대에는 0/s에 가까운 빈도로 감소.
- SRCNN과 같은 가벼운 네트워크는 문맥 전환 빈도가 낮고, PSPNet과 같은 복잡한 네트워크에서는 빈도가 크게 증가.
- 특히, DeepLab과 같은 고급 객체 분할 네트워크에서는 문맥 전환 빈도가 약 18,000/s로 치솟음.
- CPU utilization (주황 선):
- 문맥 전환 빈도와 다르게 CPU 사용률은 상대적으로 일정하게 유지.
- 객체 분할 워크로드는 GPU에서 실행되는 연산량이 크기 때문에, CPU 사용률은 여전히 낮음 (20% ~ 40% 사이).
(C) Process Number and Interrupt on Nvidia Jetson TX2
- Process number (녹색 선):
- 실행 중인 프로세스 수는 약 530 ~ 570 사이에서 일정하게 유지됨.
- AI 워크로드의 종류에 상관없이 Jetson TX2에서 기본적으로 실행되는 프로세스 수가 크게 변하지 않음을 시사.
- Interrupt (빨간 선):
- 초당 발생하는 인터럽트 수는 2000 ~ 10000 IRQ/s 사이에서 변동.
- 특정 시간 구간에서는 인터럽트가 급격히 증가하며, 이는 하드웨어 자원 관리 또는 입출력 작업(I/O)과 관련.
전반적인 결론
- 문맥 전환(Process Switch):
- AI 워크로드가 복잡할수록 문맥 전환 빈도가 크게 증가.
- 특히, 대형 네트워크(VGG16, PSPNet, DeepLab)에서 초당 문맥 전환 횟수가 약 18,000/s로 최고치를 기록.
- CPU 사용률(CPU Utilization):
- 문맥 전환과 큰 상관없이 약 30% ~ 50%로 일정하게 유지.
- 이는 AI 연산이 주로 GPU에서 수행되고, CPU는 보조 작업을 수행하기 때문.
- 프로세스 수와 인터럽트:
- 실행 중인 프로세스 수는 워크로드에 상관없이 일정.
- 인터럽트 빈도는 특정 작업(I/O, 메모리 관리)에 따라 급격히 변동하며, 최대 10000 IRQ/s까지 상승.
- 최적화 방향:
- 복잡한 워크로드에서 문맥 전환 오버헤드를 줄이기 위해 스케줄링 최적화가 필요.
- I/O 작업과 인터럽트 빈도를 줄이기 위해 워크로드와 시스템 간의 데이터 전송 경로를 최적화해야 함.
Process Creation
- OS 는 프로세스를 생성하고 종료하며, 여러 프로세스가 Concurrently 하게 실행될 수 있으며, 동적으로 생성/종료
- OS 는 process creation 과 process termination 메커니즘을 제공한다.
- 생성은 fork() 시스템 호출을 통해 이루어진다.
- 부모와 자식 프로세스는 모든 리소스를 공유한다.
- 자식 프로세스는 부모 프로세스의 리소스의 부분집합을 공유한다.
- 부모와 자식은 병렬적으로 실행되며 부모는 자식 프로세스가 종료될 때까지 기다린다.
Process Creation in Memory View
- 자식 프로세스는 부모 프로세스의 복사본으로 생성된다.
- 자식 프로세스는 독립적인 프로그램을 실행하거나 부모의 메모리를 그대로 사용할 수 있음.

- 부모 프로세스 (Parent Process):
- 텍스트 섹션, 데이터 섹션, 힙, 스택을 가지고 있음.
- 자식 프로세스 (Child Process):
- fork() 호출 후 부모의 메모리를 복사.
- exec() 호출 시 기존 메모리를 새로운 프로그램 메모리로 대체.
Process Creation in UNIX
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <unistd.h>
int main(int argc, char* argv[]){
int counter = 0;
pid_t pid;
printf("Creating Child Process\n");
pid = fork();
if(pid < 0){ // Error in fork
fprintf(stderr, "fork faild, errno: %d\n", errno);
exit(EXIT_FAILURE);
}
else if(pid > 0){ // This is Parents Process
int i;
printf("Parents(%d) made Child(%d)\n", getpid(), pid);
for(i=0; i<10; i++){
printf("Counter: %d\n", counter++);
}
else if(pid == 0){ // This is Child Process
int i;
printf("I am Child Process %d!\n", getpid());
execl("/bin/ls", "ls", "-l", NULL); // Run 'ls -l' at /bin/ls
for(i=0; i<10; i++){ // Cannot be run
printf("Counter: %d\n", counter++);
}
}
wait(NULL);
return EXIT_SUCCESS;
}
}
- pid = fork():
- 새로운 프로세스를 생성
- 이후부터 부모와 자식은 다른 실행 흐름을 따른다
- 부모 프로세스 (pid > 0):
- 부모 프로세스는 자식 프로세스의 PID를 출력하고, counter 값을 10번 출력
- wait() 호출로 자식 프로세스가 종료될 때까지 대기
- 자식 프로세스 (pid == 0):
- 자식 프로세스는 자신의 PID를 출력하고, /bin/ls 명령어를 실행
- execl() 호출 이후의 코드는 실행되지 않음
- execl()은 현재 실행 중인 프로세스의 메모리 공간 전체를 새로운 프로그램으로 교체한다.
- 현재 프로세스가 실행 중이던 프로그램의 코드, 데이터, 스택 섹션은 삭제된다.
- 대신, 지정된 새로운 프로그램(/bin/ls 등)이 프로세스 메모리 공간에 로드된다.
- 기존 프로세스의 PID는 유지되지만, 메모리와 코드 상태는 완전히 변경된다.
- execl()은 현재 실행 중인 프로세스의 메모리 공간 전체를 새로운 프로그램으로 교체한다.
- 종료:
- 자식 프로세스가 종료되면, 부모 프로세스가 wait()에서 깨어나 정상적으로 종료
Process Creation in XV6
// Create a new process copying p as the parent.
// Sets up stack to return as if from system call.
// Caller must set state of returned proc to RUNNABLE.
int
fork(void)
{
int i, pid;
struct proc *np;
struct proc *curproc = myproc();
...
// Copy process state from proc.
if((np->pgdir = copyuvm(curproc->pgdir, curproc->sz)) ==
0){
kfree(np->kstack);
np->kstack = 0;
np->state = UNUSED;
return-1;
}
np->sz = curproc->sz;
np->parent = curproc;
*np->tf = *curproc->tf;
// Clear %eax so that fork returns 0 in the child.
np->tf->eax = 0;
for(i = 0; i < NOFILE; i++)
if(curproc->ofile[i])
np->ofile[i] = filedup(curproc->ofile[i]);
np->cwd = idup(curproc->cwd);
safestrcpy(np->name, curproc->name, sizeof(curproc->name));
pid = np->pid;
acquire(&ptable.lock);
np->state = RUNNABLE;
release(&ptable.lock);
return pid;
}
Process Creation Hierarchy in UNIX

- UNIX에서 프로세스는 트리 구조로 관리된다.
- 모든 프로세스는 최상위 부모 프로세스인 root 프로세스에서 시작된다.
- root 프로세스:
- 최상위 프로세스.
- 모든 프로세스는 root 프로세스에서 직접 또는 간접적으로 파생
- init 프로세스:
- 시스템 부팅 시 생성되는 첫 번째 프로세스.
- 모든 사용자 프로세스의 부모 프로세스로 동작.
- 사용자 로그인 및 세션 관리.
- 시스템 프로세스 (pagedaemon, swapper):
- 시스템 자원 관리에 사용.
- 예:
- pagedaemon: 메모리 페이지 관리를 담당.
- swapper: 메모리 스와핑(교체)을 담당.
- 사용자 프로세스 (user 1, user 2, user 3):
- 사용자가 직접 실행하는 애플리케이션 또는 명령어.
- init 프로세스에서 생성.
Process Termination
- 프로세스가 실행을 완료하거나 강제 종료될 때 운영 체제는 해당 프로세스를 제거
- 정상 종료
- exit 시스템 호출:
- 프로세스가 마지막 명령을 실행한 후 스스로 종료를 요청.
- 부모 프로세스는 **wait()**를 통해 자식 프로세스의 종료 상태를 수집.
- 종료 시, 운영 체제는 프로세스가 점유한 자원을 회수(메모리, 파일 디스크립터 등).
- exit 시스템 호출:
- 비정상 종료
- abort() 함수:
- 프로세스를 비정상적으로 종료.
- SIGABRT 시그널을 해당 프로세스에 전달.
- 종료 시 코어 덤프(메모리 상태 저장)를 생성하여 디버깅 가능.
- abort() 함수:
Cooperating Processes
- 독립 프로세스:
- 다른 프로세스의 실행에 영향을 받지 않음.
- 협력 프로세스:
- 프로세스 간 상호작용이 존재하며, 다른 프로세스의 실행에 의존적.
- 장점
- 정보 공유:
- 여러 프로세스가 데이터를 공유하여 효율적으로 작업.
- 계산 속도 향상:
- 여러 프로세스가 동시에 작업을 수행하여 처리 속도 증가.
- 모듈성:
- 큰 작업을 여러 프로세스가 나누어 처리.
- 편리성:
- 프로세스 간 작업 분담으로 복잡한 작업을 쉽게 처리.
- 예:
- DBMS
- 공유 메모리를 통해 협력하는 세 개의 프로세스(P1, P2, P3) 가 나타남
- 모든 프로세스는 읽기 / 쓰기 작업을 통해 데이터베이스 작업을 병렬적으로 수행
- DBMS
- 정보 공유:
- 프로세스 간 상호작용이 존재하며, 다른 프로세스의 실행에 의존적.

'3학년 2학기 학사 > 운영체제' 카테고리의 다른 글
| [운영체제] #9. 동기화 (1) (0) | 2024.11.27 |
|---|---|
| [운영체제] #7. InterProcess Communication (IPC) (0) | 2024.11.26 |
| [운영체제] #5. Computer Architecture (0) | 2024.11.24 |
| [운영체제] #3. 운영체제 구조 (2) (0) | 2024.11.19 |
| [운영체제] #2. 운영체제 구조 (1) (0) | 2024.11.19 |



