
Abstract
본 논문에서는 Tesla Model X (HW 2.5 & HW 3) 와 Mobileye 630 이 두 모델의 ADASs (advance driver-assistance systems) 사이의 "split-second phantom attacks" 이라는 scientific gap 에 대해서 연구한다. 아주 짧은 시간 (a few milliseconds) 동안 진짜 장애물/객체인 것처럼 보이는 깊이가 없는 물체를 다룬다.
원격에 있는 attacker 가 phantom road sign 을 광고로 embedding 해서 split-second phantom attack 을 할 수 있다. 이는 Tesla 의 autopilot 이 갑자기 차량을 road 한 가운데에 멈추도록 하고, Mobileye 630 이 가짜 알림을 발행하도록 한다.
또한, attacker 가 projector 를 사용해서 road 에 phantom (가상의) 보행자를 projection 해서 Tesla 의 autopilot 이 이에 반응하여 brake 를 밟도록 하고, Mobileye 630은 project 된 road sign 에 반응하여 거짓 알림을 발행하도록 한다.
이러한 위협에 대응하기 위해서, 본 논문은 단지 camera sensor 만 사용해서 탐지된 객체가 phantom 인지 아니면 real 인지 판별해주는 countermeasure (GhostBusters) 를 제안한다. 이는 "committee of experts" approach 를 사용하고 4가지의 경량의 deep CNN 으로 부터 산출된 결과를 결합한다. 이 CNN 은 각각 객체의 light, context, surface 그리고 depth 에 기반하여 객체의 진위성을 평가한다.
마지막으로, 연구진들은 본 논문의 countermeasure 의 효과를 입증한다. FPR 이 0 이면서, TPR 이 0.994 이다. 그리고 적대적 machine learning attack 에 대한 robustness (강건성) 을 test 한다.
1. Introduction
advanced driver assistance systems (ADASs) 는 자동화된 기능을 가진 주행을 지원한다. ADASs 는 차량을 조종하고 교통 신호를 인식하고 차량이 차선에 이탈하면 알람을 주는 등등의 기능을 지원하기 위해 실시간으로 다양한 센서들로부터 얻어진 data 를 처리하는 AI 모델을 사용한다. 이 시스템들은 거의 image 입력에 의존하기 때문에, 적대적 machine learning attack 에 대한 robustness 는 이전 연구에서 많이 test 되었다.
본 논문에서는 AI 모델의 limitation 을 식별한다. AI 모델은 split-second phantom attack 이라고 불리는 새로운 공격이 가능하다는 것을 입증한다. 이는 ADASs 의 취약점을 이용한다. ADASs 는 projector 로 road 에 쏜 phantom imagery 를 실제 객체로 인식한다. (1) 그리고 imagery 는 ADAS 가 탐지하기 위해서는 아주 짧은 시간동안 나타나야 한다. (2)
Split-second phantom attack 은 camera 가 capture 하기 위해 요구되는 최소한의 시간동안 매우 짧게 image 를 전달해서 AI 모델을 속인다. 그래서 사람의 눈이 인식하기는 어렵다. 이는 능숙하지 않은 공격자도 잡힐 것에 대한 두려움이 거의 없이 ADASs 에 대한 split-second phantom attack 을 사용할 수 있다. 또한, attack scene 에 물리적으로 접근할 필요가 없다. (drone 이 image 를 project 하거나 billboard 가 display 할 수 있다. 또한, 증거 인멸을 할 필요도 없다. attack 이 아주 빠르게 일어나기 때문에 목격자도 거의 없다. 또한, 운전자도 이상을 감지하지 못하기 때문에 직접 차량을 수동으로 제어하여 attack 을 막으려고 하지 않을 것이다.
Split-second phantom attack 은 optical illusion 이다. 몇몇 상업의 ADASs (e.g., Mobileye 630) 는 온전히 video cameras 가 수집한 depth 가 없는 imagery input 에 의존하기 때문에 탐지된 객체의 진위성은 전혀 입증되지 않는다. 이는 ADASs 가 phantom 을 진짜 객체로 간주하도록 한다.
ADASs 가 phantom 의 진위성을 결정한다. ADASs 는 depth 센서 (e.g., radar, LiDAR, ultrasonic sensor) 가 수집한 data 와 camera 센서와의 cross-correlating 하여 sensor fusion 을 사용한다. 그러나, 가장 진보된 반자율주행 차량으로 알려져 있는 Tesla Model X 에서는 카메라와 깊이 센서 간의 불일치가 발생한다. 이 상황에서 phantom(실제로 깊이 정보는 없지만 카메라에선 객체처럼 보이는 현상)을 안전상의 이유로 실제 객체로 간주하여 처리한다.

이러한 attack 들을 완화하기 위해 본 논문은 탐지된 객체을 검증하는 machine learning 모델의 committee 인 GhostBusters 를 제안한다. 이는 추가적인 센서 없이도 기존 ADASs 에 적용될 수 있고, 기존 도로 기반 시설에 어떠한 변경도 필요 없다.
4가지의 경량 deep CNNs 로 구성되며, 이는 객체에서 반사된 빛, context, 표면, depth 이 4가지를 조사해서 객체의 진위성과 현실주의를 평가한다. 5번째 모델은 phantom 객체를 식별하기 위해 4가지의 모델의 embedding 들을 사용한다. 이 approach 는 기본 방법보다 우수한 성능을 보이며, AUC (Area Under the Curve) 가 0.99 이상이고 FPR(오탐률)을 0으로 설정한 임계값에서 TPR(진짜 양성률)이 0.994 이다.
아래는 모델의 성능 평가를 위해 사용되는 지표인 ROC, AUC, TPR, FPR 에 대한 설명이다.

- TPR (True Positive Rate) : 실제 양성을 양성으로 바르게 예측하는 비율
- FPR (False Positive Rate) : 실제 음성을 양성이라고 틀리게 예측하는 비율
- ROC (Receiver Operating Characteristic) curve : 분류 모델이 다양한 임계값(threshold)에서 보여주는 True Positive Rate (TPR)과 False Positive Rate (FPR) 사이의 관계를 그래프로 나타낸 것이다.
- AUC (Area Under the ROC Curve) : ROC 곡선 아래의 면적을 수치로 나타낸 것이다.
- 0과 1 사이의 값을 가진다.
- 1에 가까울수록: 모델이 양성과 음성을 잘 구분하는 성능이 뛰어나다는 의미
- 0.5의 경우: 무작위로 추측하는 수준임을 나타내며, 성능이 매우 낮음을 의미
이 countermeasure 를 7가지 최신 road sign detector 들에 적용했을 때, 우리 모듈이 없을 때의 공격 성공률이 99.7%에서 81.2% 사이였던 것이, 논문의 모듈을 사용하면 0.01%로 감소하였다.
마지막으로, 본 논문은 ablation study 를 수행하고 모델을 분리하는 방법이 특정 피처에 대한 의존도를 낮추고, 결과적으로 더 탄력적(resilient)이고, 잠재적인 적대적 공격(adversarial attacks)에 대해서도 더 강건(robust)하다는 것을 발견한다.
Ablation의 사전적 정의는 제거이다. 즉, Ablation Study는 제거 연구로, 모델의 성능에 가장 큰 영향을 미치는 요소를 찾기 위해 모델의 구성요소 및 feature들을 단계적으로 제거 하거나 변경해가며 성능의 변화를 관찰하는 방법이다. 이를 통해 모델의 핵심적인 구성요소와 하이퍼파라미터등을 파악할 수 있다.
본 논문의 기여는 아래 3가지로 볼 수 있겠다.
- 어떠한 포렌식 증거도 남기지 않고, 관측하기 어려우며, 원격으로도 가능한 ADASs 에 대한 attack 의 새로운 공격 유형을 발견한다.
- 2가지의 인기있는 상업 ADASs (Mobileye 630, Tesla Model X HW 2.5/3) 을 real-world scenario 에서 split-second phantom attack 을 입증한다.
- robust 하고 efficient 한 software 기반의 countermeasure 을 제안한다. 이는 camera sensor 만 사용해서 attack 을 식별할 수 있다. 학습된 모델, dataset, source code 는 공개되어 있다. (https://github.com/ymirsky/GhostBusters)
GitHub - ymirsky/GhostBusters: Ensemble model of experts for detecting fake projected street signs (phantoms)
Ensemble model of experts for detecting fake projected street signs (phantoms) - ymirsky/GhostBusters
github.com
본 논문은 아래와 같이 구성된다.
Section 3 : 왜 split-second phantom attack 이 scientfic 한 gap 을 나타내는지에 대해 discussion 한다.
Section 4 : threat model (Section 4) 의 중요성에 대해 discussion 한다.
Section 5 : 해당 attack 에 영향을 끼치는 factor 들을 분석한다.
Section 6 : Mobileye 630 과 Tesla Model X HW 2.5/3 에서 이러한 공격들을 입증한다.
Section 7 : 그리고 나서, 본 논문의 countermeasure 를 제안하고, 평가하고, 성능을 분석한다
Section 8 : 마지막으로, 연구진들은 본 논문의 발견에 대해 discussion 하고, future work 를 제안한다.
2. Background, Scope & Related Work
이 섹션에서는 ADAS 에 대한 background 를 제공하고, 이에 대한 attack 를 review 한다.
ADAS 는 vehicle-based intelligent safety system 으로 정의된다. ADAS 는 차량에 탑재되고, 자율주행 Level 0 (no automation) 에서 Level 5 (완전 자율주행) 까지 범위가 다양하다.
- Level 0, 비자동화(No Automation)
- 운전자의 개입을 필수로 하는 자율주행 시스템의 가장 기초적인 단계. 쉽게 말해서 운전자가 모든 것을 통제하고 책임지며, 자율주행 시스템은 전방 충돌방지 보조(FCA), 후측방 충돌 경고(BCW) 등의 긴급상황을 알려주는 단순 보조 기능만 수행.
- 운전자의 개입을 필수로 하는 자율주행 시스템의 가장 기초적인 단계. 쉽게 말해서 운전자가 모든 것을 통제하고 책임지며, 자율주행 시스템은 전방 충돌방지 보조(FCA), 후측방 충돌 경고(BCW) 등의 긴급상황을 알려주는 단순 보조 기능만 수행.
- Level 1, 운전자 보조(Driver Assistance)
- 자율주행 시스템이 운전자를 조금씩 도와주기 시작. 자동차의 속도와 거리를 유지하고 차선 이탈을 방지하는 등의 보조 역할을 한다. 아직은 운전자가 운전대를 반드시 잡고 조종해야 한다는 것을 전제.
- 자율주행 시스템이 운전자를 조금씩 도와주기 시작. 자동차의 속도와 거리를 유지하고 차선 이탈을 방지하는 등의 보조 역할을 한다. 아직은 운전자가 운전대를 반드시 잡고 조종해야 한다는 것을 전제.
- Level 2, 부분 자동화(Partial Automation)
- 운전자가 운전대를 조작하고 상시 모니터링은 필수이다. 자율 주행 시스템이 1단계에서 단순히 운전자를 보조하는 역할을 했다면, 2단계에서는 자연스러운 커브에서 방향을 조종하거나 앞차와의 간격을 유지하는 등의 보조 주행이 가능하다. 현재 새롭게 출시되고 있는 자동차들이 보편적으로 적용하는 단계이다.
- 운전자가 운전대를 조작하고 상시 모니터링은 필수이다. 자율 주행 시스템이 1단계에서 단순히 운전자를 보조하는 역할을 했다면, 2단계에서는 자연스러운 커브에서 방향을 조종하거나 앞차와의 간격을 유지하는 등의 보조 주행이 가능하다. 현재 새롭게 출시되고 있는 자동차들이 보편적으로 적용하는 단계이다.
- Level 3, 조건부 자율주행(Conditional Automation)
- 자율주행 시스템이 주행 제어와 주행 중 변수 감지를 할 수 있다. 고속도로처럼 특별한 방해 없이 운전 가능한 구간에서 자율주행 시스템이 주행을 담당하게 된다. 2단계와 달리 상시 모니터링이 필요한 단계는 아니지만, 위험 요소나 변수가 발생할 시 자율주행 시스템이 운전자의 개입을 요청한다.
- 자율주행 시스템이 주행 제어와 주행 중 변수 감지를 할 수 있다. 고속도로처럼 특별한 방해 없이 운전 가능한 구간에서 자율주행 시스템이 주행을 담당하게 된다. 2단계와 달리 상시 모니터링이 필요한 단계는 아니지만, 위험 요소나 변수가 발생할 시 자율주행 시스템이 운전자의 개입을 요청한다.
- Level 4, 고도 자율주행(High Automation)
- 고속도로 같은 특정 조건의 구간뿐만 아니라 대부분의 도로에서 자율주행이 가능하다. 주행 제어와 주행 책임 등 모두 자율주행 시스템에게 주어진다. 운전자의 개입은 악천후와 같은 상황을 제외하고는 불필요한 단계로 자율주행의 시스템이 점차 고도화되었음을 알려주는 단계이다.
- 고속도로 같은 특정 조건의 구간뿐만 아니라 대부분의 도로에서 자율주행이 가능하다. 주행 제어와 주행 책임 등 모두 자율주행 시스템에게 주어진다. 운전자의 개입은 악천후와 같은 상황을 제외하고는 불필요한 단계로 자율주행의 시스템이 점차 고도화되었음을 알려주는 단계이다.
- Level 5, 완전 자율주행(Full Automation)
- 운전자가 없어도 완전 자율주행이 가능한 단계이다. 운전자가 아닌 탑승자가 목적지를 입력하면, 어떠한 개입도 필요 없이 자율주행 시스템이 전적으로 자동차를 운행한다. 운전석을 비롯해 모든 제어 장치도 필요하지 않는 단계이다.
ADASs 는 센서, actuator, 의사 결정 알고리즘 로 구성되어 있다. actuator 는 센서나 제어 시스템으로부터 전달받은 신호를 실제 기계적 동작으로 전환하는 장치이다. 의사 결정 알고리즘 (e.g., 충돌 회피) 은 AI 모델들에 의존한다. AI 모델은 센서 입력 데이터를 바탕으로 운전자에게 알림이나 경고를 제공하거나, 스티어링 및 브레이크 작동 등의 행동을 수행한다. 최근 연구들은 센서 attack 을 사용해서 AI model 을 어떻게 속일 수 있는지에 대해 다룬다.
Visual Spoofing attack 도 입증되었다.
몇몇 연구들은 traffic sign recognition 알고리즘에 대한 적대적인 machine learning attack 을 physcial world 에서 입증했다. 이를 위해서 2가지 기법을 사용한다.
- 전용 렌즈 배열을 활용한 방법
- 하나의 traffic sign 에 2개의 표지판 정보를 내장하는데, 전용 렌즈 배열을 사용하여 특정 각도에서 볼 때마다 다른 표지판이 나타나도록 만든다. 즉, 보는 각도에 따라 다른 트래픽 사인이 보이게 하는 기법이다.
- 물리적 인공을 추가한 방법
- 인간의 눈에는 아무렇지 않게 보이는 스티커나 그래피티 같은 물리적 요소를 트래픽 사인에 추가함으로써, 이를 인식하는 알고리즘을 오도할 수 있는 방법이다.
- 인간의 눈에는 아무렇지 않게 보이는 스티커나 그래피티 같은 물리적 요소를 트래픽 사인에 추가함으로써, 이를 인식하는 알고리즘을 오도할 수 있는 방법이다.
또한, 아래 2가지 연구는 상업용 ADASs 에 대한 적대적 machine learning attack 을 physical world 에서 입증한다.
- HARMAN의 ADAS 공격
- 아주 미세한 변경을 가한 교통 표지판을 인쇄하여, 시스템의 표지판 감지 메커니즘을 속였다.
- Tesla의 Autopilot 공격
- 도로에 스티커를 부착해 Tesla의 자율 주행 시스템이 반대 차선으로 이탈하도록 하였다.
또 다른 연구에서는 Tesla 의 rada 와 ultrasonic 센서에 대한 spoofing, jamming attack 을 입증했다. 이는 차량이 근처에 있는 장애물에 대한 거리를 잘못 인식하도록 한다. 그리고, GPS spoofing 은 Tesla 의 autopilot 이 잘못된 방향으로 항해하도록 하는 연구도 있다. LiDAR 센서에 대한 Black-box 와 white-box 적대적 attack 은 최근에 다뤄지기도 하였다.
3. The Scientific Gap
이 섹션에서는 Phantom 과 split-second phantom attack 을 정의하고, 왜 scientific gaps 으로 고려되는지 토론한다.
연구진들은 phantom 은 깊이가 없는 시각적 객체로 정의한다. 이는 ADASs 를 속이기 위해 사용되고 ADAS 가 객체를 인식하고 진짜라고 생각하도록 한다. Phandom 객체는 projector 가 생성하거나 digital screen (e.g., billboard) 통해 보여진다. 깊이가 없는 객체는 3D 객체(보행자, 차량, 트럭, 오토바이, 교통 신호 등)의 사진으로부터 만들어진다. Phantom 은 ADAS 로부터 바람직하지 않은 반응을 촉발하기 위해 의도된다. 자율주행 0단계 ADAS 의 경우에, 반응은 event (e.g., 허용된 최대 속도) 에 대한 운전자 알림이나 알람(e.g., 충돌 회피)가 될 수 있고, 자율주행 2단계 ADAS 의 경우에는, phantom 은 차량으로부터 자동의 위험한 반응(e.g., 급제동) 을 촉발할 수 있다. Split-second phantom attack 은 ADAS 가 아주 짧은 시간동안 나타나는 phantom 을 실제 객체/장애물로 오인하도록 하는 attack 이다. 왜 ADAS 가 split-second phantom attack 에 취약한지에 대한 2가지 이유가 있다.
- Perceptual weakness (지각적 약점) : Phantom 은 computer vision 알고리즘의 인지를 어렵게 한다. 왜냐하면, 이러한 알고리즘은 개인적인 경험과 진위성, 인간이 고려하는 다른 요인들에 기반하여 결정을 하기 때문이다. 대부분 알고리즘은 실제 객체로 구성된 dataset 을 사용해 수행되는 training 단계의 output 이다. 결과적으로, computer vision 알고리즘은 phantom 을 식별해서 이들을 무시하도록 train 되지 않는다. 대신에, 이러한 알고리즘들은 객체의 일부분(e.g., 모서리, 윤곽) 이 training example 들과 유사하다면 높은 신뢰도를 가지고 객체를 분류한다. 특히 이러한 알고리즘들은 아래 3가지 측면을 고려하지 않는다.

- Context : 객체의 위치나 프레임 내에서 local context 가 고려되지 않는다. 위의 Figure 2 는 example 을 보여준다. 여기서 나무 위에 project 된 phantom traffic sign 이 상업 ADAS(Mobileye 630) 가 실제 traffic sign 으로 오인하였다.
- Color : 객체의 색깔은 고려되지 않는다. 위의 Figure 2 는 Faster_rcnn_inception_v2 [3]가 Δ=3에서 회색 배경(128, 128, 128)의 녹색 성분만 (128, 125, 128)로 감소시켜 만든, 회색 계열로 구성된 가짜(phantom) 교통 표지판을 어떻게 잘못 분류하는지를 보여준다. 다른 최신 traffic sign recognition 알고리즘에서도 또한 사실이다.
- Texture : 객체의 texture 가 고려되지 않는다. 위의 Figure 2 는 원본 traffic sign 으로부터 픽셀의 25%로 구성된 traffic sign 이 어떻게 실제 traffic sign 으로 인식하는지를 보여준다. 여기서 픽셀은 랜덤하게 그려졌다. 이는 다른 최신 traffic sign recognition 알고리즘(Appendix 1 에서 자세하게)에 대해서도 사실이다. 위의 Figure 2 는 나무 잎으로 구성된 표면에 project 된 traffis sign 을 Mobileye 630 이 어떻게 report 하는 지를 보여준다.
따라서, 사람이 phantom 을 명백히 가짜(결함, 형태가 외곡된 등) 라고 인식할지라도, ADAS는 그 형태(geometry)가 학습된 실제 표지판 예시와 일치한다는 이유만으로 단순히 실제 객체(실제 표지판)로 분류한다.
- Disagreement between sensors (센서 간 불일치) : phantom 은 센서 퓨전을 사용하는 AI 모델에서 발생하는 엣지 케이스로, 비디오 카메라를 통해 탐지된 장애물과 다른 거리(depth) 센서들이 완전히 불일치할 때 나타난다. 이러한 상황에서 Tesla 는 레이더 입력보다 영상(카메라) 입력을 우선 신뢰하며, 깊이 정보가 없는 투영되거나 제시된 객체라도 실제 장애물로 간주한다. 여기에는 몇몇 이유들이 있다.
- radar 를 통한 보행자 탐지는 실제 scene 에서 10-15 미터 거리부터 신뢰도가 떨어지는데, 이는 보행자가 radar 반사 면적(cross-section) 이 작아서 다른 객체로부터 반사에 가려지기 때문이다. 그래서, 차량은 보행자 감지에서 신뢰도가 높은 video camera 에 더 많은 신뢰를 부여해야 한다.
- 차량의 넓은 영역은 오직 video camera 로만 커버되므로(Appendix 에서 Figure 13 참고) 이 영역에서는 depth sensor 를 통해 탐지 결과를 검증할 방법이 없다.
- 자동차 업계의 일반적인 관행으로, 차량은 radar 가 탐지한 정지 객체를 무시하도록 프로그래밍되어 있으며, 대신 이동 객체에 집중하도록 설계되어 있다. 이 사실은 Tesla manual, 다른 vendor 들의 manual 들 그리고 NTSB 보고서에서 언급되었다. 여기서 운전자는 차량의 autopilot 이 정적인 장애물을 탐지하지 못한다고 경고를 받는다. 결과적으로 차량은 정적인 객체를 탐지하는데에 있어서는 다른 sensor 에 더 높은 신뢰도를 준다. (Tesla 가 정적인 phantom 차량을 어떻게 탐지하는지 Figure 2 에서 확인)
센서들 사이에 장애물의 존재에 관한 불일치는 ADAS 가 실시간으로 해결해야 한다. (몇 millisecond 내에) 그리고 정확하지 않은 결정은 보행자, 운전자 그리고 승객을 위험에 처하게 한다. 차량 제조업체는 삶의 손실과 사고를 막고 싶어하기 때문에, "safety first" approach 가 자율주행에서 구현되었다. 그리고 차량이 radar 와 ultrasonic sensor 가 통합된 채로 phantom 을 실제 객체로 간주한다. (Figure 2 참고)
어떤 사람은 ADAS가 감지된 객체를 실제로 인식하기 전에 영상 스트림에 일정 시간 이상 나타나야 한다는 임계값을 늘리면 순식간에 발생하는 팬텀 공격(split‑second phantom attack)을 무시할 수 있다고 생각할 수 있다. 하지만 ADAS는 도로에 갑자기 나타나는 실제 장애물에도 즉각 대응해야 하기 때문에, 이 최소 임계값을 지나치게 높게 설정하면(예: 1초) ADAS가 제때 반응하지 못할 위험이 생긴다. split-second phantom attack 을 bug 로 간주하지 않는다. 왜냐하면 이 attack 들은 잘못 짜여진 코드 구현의 결과가 아니기 때문이다. 연구진들은 phantom 들을 scientific gap 으로 간주한다. 왜냐하면, 이 phantom 들이 safety 수준을 낮춰야 효과적으로 해결할 수 있는 지각적 약점을 악용하기 때문이다.
쉽게 말해서, 이 공격은 자동차의 인식 시스템이 가진 근본적인 약점을 노린다. 이 약점을 고치려면 차의 안전 기능을 약하게 만들어야 하기 때문에, 지금 기술로는 해결할 수 없는 문제라는 뜻이다. 그래서 이를 과학적 격차(scientific gap)라고 부른다.
4. Threat Model
이 섹션에서는, 연구진들은 원격의 threat model 을 보여준다.
Table 1 은 어떠한 phantom 의 type 으로 어디에 출현시켜 ADAS의 반응을 이끌어내면 원하는 결과를 얻을 수 있다는 것을 mapping 해서 보여준다.

예를 들어, “교통 충돌”을 만들고 싶다면 건물 벽이나 광고판에 “정지 표지판”을 아주 짧게 투사해서 ADAS가 갑작스레 제동하도록 유도할 수 있다.
이 Threat Model 에서, 공격자는 인터넷에 연결된 해킹된 디지털 광고판에 디지털 광고처럼 위장된 팬텀을 삽입할 수 있으며, 또는 드론에 장착한 휴대용 프로젝터를 사용해 도로·건물 등 원하는 장소에 팬텀을 투사할 수도 있다. 공격자는 드론 무리(swarm of drones) 또는 여러 대 해킹된 디지털 광고판(hacked digital billboards) 을 사용해 원하는 효과를 더욱 증폭시킬 수 있다.
Split-second phantom attack 은 시각적 스푸핑(visual spoofing)의 한 종류이다. 이 공격이 기존 연구들과 차별화되는 점 4가지이다.
- 휴대 가능한 projector 를 장착한 드론을 사용하거나, 인터넷에 연결된 해킹된 디지털 광고판에 디지털 광고처럼 위장된 팬텀을 삽입하여 원격으로 실행될 수 있다.
- 공격 현장에 남는 물리적 증거가 전혀 없어, 수사관이 공격자를 추적하기 어렵다
- 복잡한 전처리나 전문적인 센서 스푸핑 기술이 필요 없다.
- 공격자는 자동차, 보행자 등 팬텀 객체를 이용해 ADAS의 장애물 인식 시스템을 조작할 수 있다.
5. Attack Analysis
이 섹션에서는 상업용 ADAS 를 대상으로 project 된 거리와 지속시간이 split-second phantom attack 의 성공률에 영향을 끼치는 다양한 factor 들에 대해서 분석한다.
2가지의 상업용 ADASs 에 대해 수행된다.
- Mobileye 630 PRO : 자율주행 0-1 단계 차량에 대해 가장 진보된 외부 ADAS 로 알려져 있다. Mobileye 는 ADAS 기술을 차량 제조업체의 70% 정도를 판매하였다. 이 섹션의 나머지에서 연구진들은 Mobileye 630 PRO 를 Mobileye 로 언급한다. Mobileye 는 computer vision 알고리즘들에만 의존하며, video camera 와 (차량 앞 유리창에 설치됨), 시각적, 청각적 경고를 제공해주는 display 로 구성되어 있다. Mobileye 는 road sign recognition 과 차량 충돌 경고, 다른 feature 들을 제공한다. 연구진들은 공식 현지 대리점을 통해 2017년형 Renault Captur 차량에 Mobileye 를 설치했다.
- The Tesla Model X (HW 2.5 / 3) : 가장 진보된 상업용 반자율주행 차량으로 알려져 있다. 이 섹션의 나머지에서 연구진들은 Tesla Model X (HW 2.5 / 3) 을 Tesla 라고 언급한다. 이 모델은 8개의 주변 video camera 들과 12 개의 ultrasonic sensor 들과 전방 radar (Appendix 의 Figure 13 참고) 에 의존한다. 이 모델들은 autopilot 주행, 크루즈 컨트롤, 충돌 회피, 정지 표지판 인식을 지원한다. 실험이 진행될 당시 가장 최신 펌웨어가 설치되어 있었다.
5.1. Influence of Distance
다음 두 가지 요인이 팬텀 공격을 일정 거리에서 실행할 수 있는지를 결정한다
- 투사의 밝기(intensity) : 밝기가 너무 약하면, 거리가 멀어질수록 빛이 약해져 카메라에 잡히지 않는다.
- 팬텀의 크기(size) : 투사된 객체가 너무 작으면, ADAS는 이를 즉각적인 장애물이나 도로 표지로 인식하지 않고 무시한다.
5.1.1. Experiment Setup
- 투사용 장비: Nebula Capsule 프로젝터 (100 루멘, 854×480)
- 투사 대상: 흰색 스크린
- 변수 ① 밝기(opacity): 10%→100% (10단계)
- 변수 ② 크기(diameter): 0.16, 0.25, 0.42, 0.68, 1.1, 1.25 m
5.1.2. Experiment Protocol (절차)
| 실험 | 방법 | 측정값 |
| ① 밝기 실험 | ADAS(테슬라·Mobileye)를 화면 1m 거리 배치 → 가장 밝은 팬텀부터 순차 투사 → ADAS가 인식 못할 때까지 밝기 낮춤 | 투사 강도(럭스), 거리(m) |
| ② 크기 실험 | 가장 큰 팬텀부터 투사 → ADAS 미인식 시까지 크기 축소 | 팬텀 크기(m), 거리(m) |
| → 반복 | ADAS-스크린 거리 2m 씩 증가 | ----- |
첫 번째 데이터셋은 최소 투사 밝기(럭스)와 ADAS가 팬텀을 탐지할 수 있는 최대 거리(미터) 간의 관계를 기록했다. 투사 밝기 측정값에서 주변광(ambient light) 밝기를 뺀 Δ값을 계산했는데, 이는 주어진 주변광 조건에서 공격자가 추가로 필요한 투사 밝기를 의미한다.
두 번째 데이터셋은 최소 팬텀 크기(지름)와 ADAS가 해당 팬텀을 탐지할 수 있는 최대 거리 간의 관계를 기록했다.
5.1.3. Result & Conclusions
아래 Figure 3 이 결과를 보여준다.

최소 투사 밝기(럭스)와 ADAS가 팬텀을 탐지할 수 있는 최대 거리(미터) 간의 관계 (왼쪽 그래프) 를 그래프로 보여준다. 주요 결과는 다음과 같다:
- 거리 증가 → 더 강한 프로젝터 필요
- 거리가 멀어질수록 빛이 약해지기 때문에, ADAS가 팬텀을 감지하려면 더 높은 투사 밝기가 필요하다.
- 빛이 거리와 반비례하기 때문이다.
- 야간 공격이 주간보다 용이
- 밤에는 주변광이 0 lux인 반면 낮에는 1,000–2,000 lux 수준이므로, 낮보다 밤에 약한 프로젝터로도 팬텀 공격이 가능하다.
- Tesla가 Mobileye보다 먼 거리에서도 탐지 가능
- Tesla는 전방에 3대의 HD 카메라가 설치되어 있는 반면, Mobileye는 단일 카메라만 사용하기 때문에, 동일한 밝기로도 Tesla가 더 먼 거리에서 팬텀을 감지한다. (Appendix Figure 13 참고)
- Tesla 를 attack 하는 데 요구되는 projection 의 강도(lux) 가 더 낮고, 거리가 더 길다.
팬텀의 최소 크기(지름)와 ADAS가 이를 탐지할 수 있는 최대 거리 간의 관계(가운데 그래프)를 Mobileye와 Tesla 각각에 대해 보여준다. 결과는 다음과 같다.
- 거리 증가 → 더 큰 팬텀이 필요
- ADAS는 카메라 영상에서 객체가 차지하는 크기를 보고 “가까운 도로 표지(sign)”인지 판단하기 때문에, 거리가 멀어질수록 화면에 더 크게 보이도록 팬텀 크기를 키워야 탐지된다.
- Mobileye와 Tesla의 탐지 특성 거의 동일
- 두 시스템 모두 영상에 잡힌 표지판의 크기를 기준으로 객체의 위치를 판단하므로, 크기‑거리 관계 그래프가 거의 겹쳐진다.
추가로, Appendix 2에서 본 실험 범위를 벗어난 거리에서도 필요한 팬텀 크기와 투사 밝기를 추정 계산하는 방법을 설명하고 있다.
5.2. Influence of the Duration of the Phantom
여기서는 split-second phantom attack 의 성공률이 지속 시간(duration) 에 어떻게 영향을 받는지 분석한다. 팬텀은 디지털 시각화 장치(광고판, 프로젝터 등)의 출력물이며, ADAS 비디오 카메라의 CMOS 센서에 의해 샘플링된다.
아래 3가지를 가정한다.
- 공격자는 공격 대상 ADAS 비디오 카메라의 FPS(초당 프레임 수) 에 대한 사전 지식이 없다.
- 공격자는 탐지 모델의 동작 방식에 대한 사전 지식이 없다.
- 공격자는 디지털 시각화 장치를 ADAS 카메라에 동기화할 수 없다(공격의 특성상 불가능).
5.2.1. Experiment Setup
24 FPS 디지털 시각화 장치(사용한 프로젝터)를 통해 공격 성공률을 분석하기 위해 24개의 테스트 비디오를 제작했다. 각 비디오는 특정 지속 시간 동안 팬텀이 나타날 때의 성공률을 평가하도록 설계되었다. 실제 상황에서 팬텀이 임의의 프레임에 등장할 수 있음을 시뮬레이션하기 위해, 팬텀이 나타나는 프레임의 위치를 매초마다 한 프레임씩 순차적으로 이동시켰다.
실험에서 프로젝터가 24 FPS(초당 24프레임)로 동작하기 때문에 “팬텀이 몇 프레임 동안 보이느냐”를 기준으로 지속 시간을 정확히 제어하려면 1프레임부터 24프레임(≈1초)까지 모든 경우를 각각 따로 테스트해야 한다.
- 첫 번째 비디오: 팬텀이 1프레임(약 41ms) 동안만 나타나며 총 24초 길이. 매초마다 팬텀은 한 프레임에만 등장한다(첫 초는 1프레임, 두 번째 초는 2프레임,… 마지막 24초는 24프레임).
- 두 번째 비디오: 팬텀이 2연속 프레임(약 82ms) 동안 나타나며 총 23초 길이. 매초마다 팬텀이 두 연속 프레임에 등장하고, 이 위치는 매초 한 프레임씩 이동한다.
- 이 패턴을 반복하여, 24번째 비디오는 팬텀이 24연속 프레임(1초) 동안 나타나며 총 1초 길이로 제작했다.
총 24개의 비디오를 Tesla용 정지 표지판과 Mobileye용 제한 속도 표지판 각각에 대해 제작했다. 프로젝터는 ADAS로부터 2미터 떨어진 흰색 스크린에 설치했다.
5.2.2. Experiment Protocol
제작한 모든 비디오를 Tesla와 Mobileye 시스템에 각각 10회씩 재생했다. 성공률(success rate) 은 팬텀이 등장할 때 ADAS가 이를 탐지한 횟수를 팬텀 등장 횟수로 나누어 계산했다.
5.2.3. Result & Conclusions
그림 3은 이 실험 결과를 보여준다.
분석 결과 4 가지 주요 관찰점이 있다.
- 416밀리초(ms) 이상 지속되는 팬텀은 테스트된 모든 ADAS에서 100% 탐지되었다. 이는 ADAS가 도로 표지에 빠르게 반응해야 하기 때문이다.
- 실험 범위 내 그래프는 시그모이드(sigmoid) 형태를 보인다. 짧은 지속 시간에서는 탐지 성공률이 0%를 유지하다가, 특정 임계값(threshold)에 도달하면 급격히 100%로 상승한다. 이는 ADAS가 연속된 t프레임에 객체가 나타날 때만 실제 객체로 간주해 오탐(false positive)을 줄이도록 구성되었기 때문이다.
- 특정 지속 시간 구간에서는 성공률이 1–99% 사이의 확률적 영역을 형성한다. 이는 카메라 FPS와 프로젝터 간의 동기화 차이로 인해 팬텀이 연속된 t프레임 또는 t−1프레임에 등장할 가능성이 있기 때문이다.
- 카메라가 찍는 타이밍(frame)과 프로젝터가 보여주는 타이밍이 완전히 일치하지 않아서, 같은 길이로 팬텀이 투사돼도 때때로 카메라가 연속 프레임으로 잡을 수도 있고, 때때로 하나 모자랄 수도 있다.
- 동일한 지속 시간에서도 ADAS 종류에 따라 성공률이 달라진다. 예를 들어 333ms 동안 나타난 팬텀은 Mobileye에서 100% 탐지된 반면, Tesla에서는 35.3%만 탐지되었다.
6. Evaluation
이 섹션에서는 주행 중 상용 ADAS에 대한 split‑second phantom attacks 을 시연한다. 공격은 다음 두 가지 방식으로 검증되었다:
- 해킹된 디지털 광고판에 도로 표지판을 삽입
- 드론에 장착된 휴대용 프로젝터를 통해 도로 표지판을 투사
공격 대상 차량은 Renault Captur (Mobileye 630 장착)와 테슬라 모델 X(Tesla Model X, HW 2.5 및 HW 3) 이다.
6.1. Phantom Attack via a Digital Billboard
팬텀 공격을 디지털 광고판을 통해 시연한다. 광고 이미지 속에 팬텀(가짜 도로 표지판)을 잠깐(몇 밀리초) 삽입하여, 사람 눈에는 거의 인지되지 않도록 공격을 수행한다. 이를 위해 연구진은 사람이 인식하지 못할 정도로 팬텀을 광고에 은밀하게 삽입하는 Algorithm 1을 개발하였고, 이 알고리즘의 출력 결과를 이용해 맥도날드 광고에 팬텀 도로 표지를 삽입하여 Mobileye 및 Tesla 시스템을 대상으로 공격을 수행했다.
6.1.1. Algorithm for Disguising Phantoms in Advertisements
Algorithm 1 Rank-Blocks
----------------------------------------------------------
1: procedure Main(height, width, video, nC)
2: grids[][][] = extract-key points(height, width, video)
3: local [][][] = local-score(grids)
4: global [][][] = global-score(local-scores,nC)
5: return global
6: procedure extract-key points(height, width, video)
7: for (i =0; i< len(video);i++) do
8: k-p [][] = SURF(video[i])
9: for (x =0; x< len(key points); x++) do
10: for (y =0; y< len(key points[0]); y++) do
11: grids [i][x % width][y % height] += k-p[x][y]
12: return grids
13: procedure local-score(grids)
14: for (f=0; f<len(grids); f++) do
15: grid = grids[f]
16: for (x1=0; x1<len(grid); x1++) do
17: for (y1=0; y1<len(grid[0]); y1++) do
18: scores[f][x1][y1] = local-score-block(grid,x1,y1)
19: return scores
20: procedure local-score-block(grid,x1,y1)
21: score = 0
22: for (x2=0; x2<len(grid); x2++) do
23: for (y2=0; y2<len(grid[0]); y2++) do
24: score += (1 + sqrt((𝑥1 − 𝑥2)^2 + (𝑦1 − 𝑦2)^2))×grid[x2][y2]
25: score/= (1 + grid[x1][y1])
26: return score
27: procedure global-score(local-scores,nC)
28: for (f=0; f<len(grids)-nC; f++) do
29: for (x=0; x<len(grid); x++) do
30: for (y=0; y<len(grid[0]); y++) do
31: for (i=f; i<f+nC; i++) do
32: global[f][x][y] += local[i][x][y]
33: return global
- Algorithm 1의 입력값
- video: 광고 영상 (3D 매트릭스, 프레임 × 높이 × 너비)
- nC: 공격에 필요한 연속 프레임 수 (ex. 팬텀이 몇 프레임 동안 나올지)
- height, width: 삽입할 팬텀의 높이와 너비
- 출력값 (3D array of scores)
- 각 위치마다 팬텀을 삽입했을 때 얼마나 잘 숨겨지는지(disguising score) 를 나타내는 3차원 배열
아래 Figure 4 는 알고리즘의 process 를 보여준다.

- 각 프레임에서 SURF 알고리즘을 사용하여 관심 영역, 즉 시청자가 주목할 만한 ‘키 포인트’를 추출한다.
- 프레임을 팬텀의 크기(높이×너비)와 같은 셀로 분할한 후, 각 셀에 있는 키 포인트의 개수를 센다. 이렇게 하면 화면 내 어느 부분이 시청자의 관심을 많이 받는지 파악할 수 있다.
- 각 셀(블록)이 얼마나 관심 있는 영역(키 포인트가 많은 영역)과 떨어져 있는지 local score 를 계산한다.
- 핵심 아이디어: 관심 있는 영역과 먼 블록은 시청자가 덜 주목하기 때문에, 그곳에 팬텀을 삽입하면 눈에 띄지 않는다.
- 이를 위해 알고리즘은 두 블록$(b_i, b_j)$간의 유클리드 거리를 계산하고, 두 번째 블록의 키 포인트 수(nKP)와 곱하여, 그 블록이 “은닉하기 좋은지”에 대한 점수 를 산출한다.
- 식
- $$
\begin{equation}
score(b_i, b_j) = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2 * nKP(b_j)}
\end{equation}
\quad b_{i} \text{ located at (x1,y1), } b_{j} \text{ located at (x2,y2)}
$$
- 이 계산 결과는 비교 대상인 두 블록 $b_i$와 $b_j$ 사이의 거리가 멀어지거나,
블록 안에 있는 키 포인트(key points)의 수가 많아질수록 더 커진다.
- 이 계산 결과는 비교 대상인 두 블록 $b_i$와 $b_j$ 사이의 거리가 멀어지거나,
- $$
- 식
- frame $f$ 에서 block $b_i$ 의 local score 는 block $b_i$ 와 다른 블록들 사이의 모든 score 를 더한 값을 $b_i$ 의 key point 개수로 나눈 값이다.
- 식
- $$
local - score_{f}(b_{i}) = \frac{\sum_{\forall b_{j}} score(b_{i}, b_{j})}{1 + nKP(b_{i})}
$$
- $$
- 식
- Figure 4는 점수를 [0,1] 범위로 정규화한 후, 히트맵 형태로 한 프레임에서 이 단계를 보여준다.
- ADAS의 카메라는 광고의 FPS(예: 24 FPS)보다 낮은 FPS(예: 12 FPS)로 동작할 수 있으므로, 공격자가 입력으로 제공할 수 있는 여러 연속 프레임($nC$)에서 팬텀이 나타나야 할 수 있다.
- 예를 들어, Mobileye는 125ms 동안 표시된 팬텀을 감지하기 때문에 24 FPS 비디오에서는 팬텀이 3 프레임에 걸쳐 나타나야 감지된다. 이러한 경우(𝑛𝐶 > 1)에는 시간 개념을 고려하여 블록의 전역 점수를 계산해야 한다. 이는 연속된 두 프레임 사이에 블록의 국부 점수가 변할 수 있기 때문이며, 프레임 𝑓에서 시작해 다음 𝑛𝐶 프레임 동안 블록 𝑏𝑖의 전역 점수는 프레임 𝑓부터 𝑓 + 𝑛𝐶까지 해당 블록의 국부 점수의 합으로 정의된다.
- 식
- $$
global - score(b_i, frame, nC) = \sum_{f=frame}^{frame+nC} local - score_f(b_i)
$$
- $$
- 팬텀을 감추기에 이상적인 블록과 프레임은 가장 높은 점수를 받은 블록이다. Fig. 4는 광고 전체에 대해 다음 3개의 연속 프레임에 대한 각 블록의 전역 점수를 보여준다.
6.1.2. Validation
연구진들은 YouTube 에서 임의의 맥도날드 광고를 선택했다. 알고리즘 1을 해당 광고에 적용하여 팬텀을 감추기에 최적의 블록과 프레임(전역 점수가 최대인 블록)을 찾았다. 팬텀 투사 지속 시간이 공격 성공률에 미치는 영향에 대한 분석(Figure 3) 을 바탕으로, Mobileye 630 을 공격하기 위해 광고의 연속된 3 프레임(125ms) 에 속도 제한 표지판을 삽입하였고, Tesla Model X 를 공격하기 위해 광고의 연속된 9 프레임(500ms) 에 정지 표지판을 삽입하였다. 변조된 광고는 여기서 확인할 수 있다. (https://youtu.be/-E0t_s6bT_4) 각 광고에서 도로 표지판의 크기는 이후 실험에 사용된 디지털 빌보드의 크기에 따라(그림 3의 분석에 따라) 선택되었다.
아래에서는 해당 광고를 사용하여 Mobileye 630과 Tesla에 탑재된 차량을 공격한 방법을 시연한다.
먼저, 지하 주차장에 설치된 디지털 빌보드에서 재생된 디지털 광고를 통해 Mobileye 630이 탑재된 차량에 대한 공격을 시연한다. 이 실험은 보안 부서의 적절한 승인을 받은 후, 대학 캠퍼스의 한 건물 지하 주차장에서 진행되었다. 공격자는 주차장 인도에 배치된 65인치 TV 스크린(디지털 빌보드를 시뮬레이션하기 위해 사용됨)을 사용하였다. 실제 디지털 빌보드를 해킹할 의도가 없었기 때문에 이 구성을 사용하여 공격을 시연하였다.
실험은 다음과 같이 진행되었다.

차량이 주차장을 주행하는 동안, 변조된 맥도날드 광고가 TV 스크린에서 재생되었고, 90km/h 속도 제한 표지판의 팬텀이 125ms 동안 표시되었다. 위의 Figure 5 는 스크린 왼쪽 상단에 팬텀이 125ms 동안 표시된 순간의 스냅샷을 보여준다. Mobileye가 팬텀을 감지하고 운전자에게 90km/h 속도 제한을 알림으로써, 이 공격은 성공적이었다. (참고로, 이 주차장에서는 30km/h 이상의 주행이 금지되어 있다.)
이제, 도로 근처에 위치한 디지털 빌보드에서 재생된 디지털 광고를 통해 Tesla Model X(HW 3)가 탑재된 차량에 대한 공격을 시연한다. 이 실험은 보안 부서의 적절한 승인을 받은 후, 대학 캠퍼스 내의 도로에서 진행되었다. 공격자는 도로 중앙에 배치된 42인치 TV 스크린(디지털 빌보드를 시뮬레이션하기 위해 사용되었으며, 전원 공급을 위해 다른 차량에 연결됨)을 사용하였다. 실제 디지털 빌보드를 해킹할 의도가 없었기 때문에 이 구성을 사용하여 공격을 시연하였다.
실험은 다음과 같이 진행되었다

도로 시작 부분에서 Tesla의 자동 조종 모드를 활성화하였고, Tesla는 도로 중앙으로 접근하였으며, 그곳에서 TV 스크린은 변조된 맥도날드 광고(500ms 동안 정지 표지판이 삽입됨)를 재생하였다. 위의 Figure 6은 스크린의 왼쪽 상단에 팬텀이 500ms 동안 표시된 순간의 스냅샷을 보여준다. Tesla의 자동 조종 모드가 팬텀 정지 표지판을 인식하여 차량을 즉시 도로 중앙에서 정지시킴으로써, 이 공격은 성공적이었다.
6.2. Phantom Attack via a Projector
먼저 Mobileye 630이 탑재된 차량을 대상으로 공격을 시연하였다. 이 실험은 30 km/h 제한 속도가 적용된 도로에서, 지역 당국의 허가를 받아 진행되었다. 공격자는 휴대용 프로젝터가 장착된 드론(DJI Matrice 600)을 사용하였다. 대상 차량은 Mobileye가 탑재된 르노 캡처(Renault Captur)였다.
실험은 다음과 같이 진행되었다.

도시 환경 내에서 차량이 주행하는 동안, 드론은 Mobileye의 시야 내에 있는 한 건물에 125ms 동안 90 km/h 속도 제한 표지판의 팬텀을 투사하였다. 위의 Figure 7은 이 실험에 사용된 팬텀의 스냅샷을 보여준다. Mobileye가 팬텀을 감지하고 운전자에게 90 km/h 속도 제한을 알림으로써 공격은 성공적이었다.
그 후, Tesla Model X(HW 2.5)를 대상으로 팬텀 공격을 검증하였다. Figure 1과 2에서 보였듯이, 이 모델은 깊이 정보가 없는 객체의 팬텀을 실제 장애물로 인식한다(깊이 센서가 탑재되어 있음에도 불구하고; Figure 13 참조).

이 실험에서는 지역 당국의 도로 폐쇄 허가를 받은 후, 도로에 보행자 팬텀을 투사하였다. 이 팬텀은 드론에서 투사되지 않았는데, 이는 도로 및 고속도로 주변에서 드론 사용이 현지 비행 규정에 의해 금지되어 있기 때문이다. 또한, 윤리적 이유로 인해 팬텀은 순간적으로 투사하는 대신 일정 시간 동안 지속적으로 투사되었다. 갑작스런 보행자의 출현으로 인해 차량이 급격하게 핸들을 돌려 운전자와 보행자의 생명이 위험해질 수 있기 때문이다. 본 실험은 이동 중인 차량에 대해 팬텀 공격이 효과적임을 검증하기 위해 수행되었으며, Tesla에 대한 순간적인 공격의 효과는 5절과 6.1.2절에서 이미 보여주었다. 실험은 Tesla가 투사된 보행자를 향해 주행하면서 크루즈 컨트롤을 18 MPH로 설정한 상태에서 수행되었으며(Figure 8 참조), 그 결과 Tesla는 팬텀 보행자와의 충돌을 피하기 위해 자동으로 브레이크를 작동(18 MPH에서 14 MPH로 감속)하였다. 요약하면, 차량은 팬텀을 실제 장애물로 인식하고 이에 맞게 반응하였다.
연구 결과를 Tesla와 Mobileye에 책임감 있게 공개한 내용은 Appendix 3에 제시되어 있다.
7. Detecting Phantoms
자율 주행 시스템은 RADAR와 LIDAR로 차량 주변을 감지하기도 하지만, 보행자를 인식 못해 치명적인 사고를 초래할 수 있는 위험(예: 도로 위 보행자 미검출)을 피하기 위해 카메라 센서에 의존한다는 사실이 밝혀졌다. 제조사 입장에서는 사고를 유발할 위험을 감수하기보다(예: 정지 혹은 회피 동작) 시스템이 과도하게 반응하길 원하기 때문이다. 이러한 상황에서, 본 논문은 카메라 센서로 식별된 물체를 검증할 수 있는 소프트웨어 모듈을 추가로 제안한다.
3장에서 논의한 바와 같이, ADAS와 자율 주행 시스템은 종종 감지된 물체의 문맥(context)과 진짜처럼 보이는 정도(authenticity)를 무시한다. 이는 컴퓨터 비전 모델이 단순히 기하학적 형태 매칭만 수행할 뿐, 가짜 물체(팬텀)가 어떻게 보이는지에 대한 개념이 없기 때문이다. 따라서, 팬텀 검출 모듈은 물체의 문맥과 진짜같은지 여부를 바탕으로 합법성을 검증해야 한다. 일반적으로 팬텀 이미지를 감지하기 위해 분석할 수 있는 여섯 가지 측면은 다음과 같다.
- 크기(Size)
- 감지된 물체의 크기가 실제보다 크거나 작으면 무시해야 한다. 예를 들어, 규정 크기가 아닌 교통 표지판 등. 물체의 크기와 거리는 스테레오 영상 기법[43]을 통해 카메라 센서만으로도 측정할 수 있으나, 동일한 방향을 향한 복수의 카메라가 필요하다.
- 각도(Angle)
- 물체의 기울기가 프레임 내 배치와 일치하지 않으면 팬텀일 가능성이 높다. 카메라를 향하는 2D 물체의 기울기는 프레임 내 위치에 따라 달라지며, 투사된 팬텀은 표면에 각도로 비춰지거나 표면이 카메라를 정면으로 마주하지 않아 비정상적으로 왜곡되어 보일 수 있다.
- 초점(Focus)
- 프로젝터로 투사된 팬텀은 프로젝터의 초점 범위를 벗어난 영역에서 흐릿하게 보인다(Figure 17 참조). 예컨대 표면에 각도를 주어 투사하거나 울퉁불퉁한 표면에 투사할 때 그렇다.

- 프로젝터로 투사된 팬텀은 프로젝터의 초점 범위를 벗어난 영역에서 흐릿하게 보인다(Figure 17 참조). 예컨대 표면에 각도를 주어 투사하거나 울퉁불퉁한 표면에 투사할 때 그렇다.
- 문맥(Context)
- 물체의 위치가 불가능하거나 비정상적이면 팬텀을 의심해야 한다. 예컨대 기둥이 없는 교통 표지판, 땅 위에 ‘떠 있는’ 보행자 등이 해당된다.
- 표면(Surface)
- 물체 표면이 왜곡되거나 울퉁불퉁하거나, 감지된 물체의 일반적 특징과 어울리지 않는 요소가 있으면 팬텀일 가능성이 크다. 예컨대 벽돌 벽이나 고르지 않은 표면에 투사된 경우이다.
- 조명(Lighting)
- 위치(예: 그늘진 곳)나 시간대에 비해 물체가 지나치게 밝으면 팬텀일 가능성이 높다. 영상 분석을 통한 수동 검증이나 플래시 촬영 같은 능동적 조명 기법으로 확인할 수 있다
- 깊이(Depth)
- 물체의 표면 형태가 부적절하거나 3D 장면 내 위치가 비정상적이면 팬텀일 수 있다. 예컨대 울퉁불퉁한 표면(Figure 2의 나무)에 투사된 교통 표지판, 도로 표면에 투사된 3D 사람·차량(Figure 1, 2) 등이 해당된다. 기존 차량용 카메라로 암묵적 깊이 정보를 추출하려면 연속 비디오 프레임 간 옵티컬 플로우를 계산할 것을 제안한다(후술).
이 여섯 가지 측면은 다양한 환경에서 수백 개의 팬텀 이미지를 실제 물체 이미지와 시각적으로 비교해 도출한 것이다. 이 목록이 완전하지 않을 수 있으며, 이미지에서 팬텀을 식별하는 다른 기준이 추가로 있을 수 있음을 유의해야 한다.
다음 하위절에서는 초점, 문맥, 표면, 깊이 측면을 고려한 대응책의 한 가지 구현 예시를 제시한다. 현존 최첨단 교통 표지판 검출기 8종과 함께 평가할 수 있어 투사된 팬텀 교통 표지판 검출에 중점을 둔다. 또한 임시 교통 표지판(공사 구역의 주의·속도 표지판, 스쿨버스 정지 표지판 등)이 매우 흔하므로 교통 표지판 위치 데이터베이스만으로는 팬텀 공격을 완화할 수 없다는 점을 지적한다. 교통 표지판을 예로 들었지만 동일한 접근법을 보행자·차량 등 다른 유형의 팬텀 물체에도 적용할 수 있다.
7.1 The GhostBusters
제안한 대응책은 전반적으로 다음과 같이 작동한다.
차량의 영상 인식 모델이 물체를 감지하면, 감지된 물체를 원본 이미지에서 잘라내어 본 모듈에 전달한다. 모듈은 해당 물체가 팬텀(비현실적인 설정을 가진 객체)인지 예측한다. 객체가 팬텀이라 판단되면, 시스템은 해당 감지 결과를 신뢰할지 여부를 결정할 수 있다. 이 모델은 모든 감지 대상에 적용하거나, 충돌 회피와 같이 긴급하다고 판단된 경우에만 선택적으로 적용할 수 있다.
$x^t$ 를 영상 프레임 $t$ 에서 중앙에 배치되고 전체 이미지의 약 ${1 \over 9}$ 을 차지하도록 잘라낸 RGB 교통 표지판 이미지라고 하자. $x^t$ 가 팬텀인지 실제 객체인지 예측하기 위해, 단순히 $ x^t$ 를 입력받아 가짜/진짜를 분류하는 CNN 분류기를 만들 수도 있다. 그러나 이 방식은 표지판의 밝기나 색상 같은 특정 특징에만 의존하기 때문에, 서로 다른 표면에 투사된 팬텀이나 훈련에 사용되지 않은 프로젝터로 생성된 팬텀에는 일반화되지 않는 한계가 있다.
이러한 편향을 피하기 위해 기계 학습에서 사용하는 위원회(committee of experts) 접근법[26]을 활용한다. 서로 다른 관점 또는 해석 능력을 가진 여러 모델을 앙상블로 구성함으로써, (1) 한 측면이 증거를 포착하지 못할 때에도 대응력을 높이고, (2) 네트워크를 관련 특징에만 집중시켜 오탐(false alarm)을 줄인다.
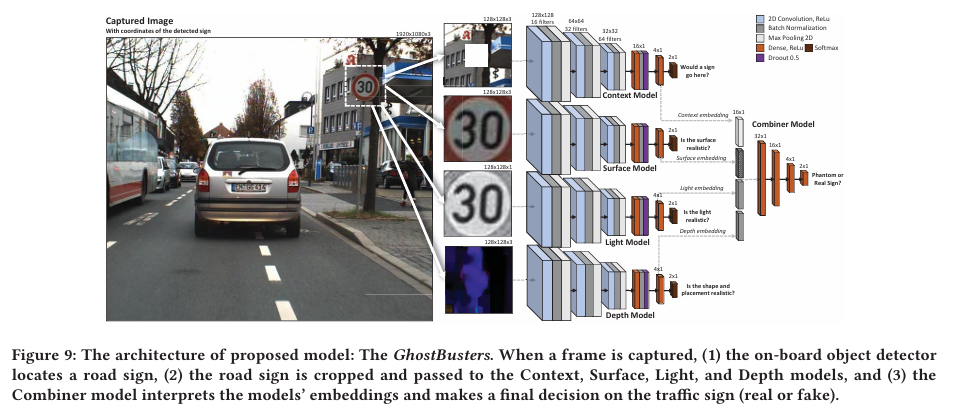
본 논문의 위원회인 GhostBusters는 네 가지 다른 측면에 집중하는 딥 CNN 모델 네 종류로 구성된다(아키텍처 및 파라미터는 Figure 9 참조).
각 모델은 잘라낸 교통 표지판 이미지를 입력받아, 해당 표지판이 문맥상 타당한지 판정한다.
- Context Model
- 표지판 주변 문맥을 분석한다. $x^t$를 $128 \times 128$ 크기로 리스케일한 뒤, 중앙 $45 \times 45$영역을 0으로 마스킹하여 입력으로 사용한다. 이 모델은 해당 위치에 표지판이 적절하게 배치되었는지를 예측하도록 학습된다.
- Surface Model
- 표지판 자체의 표면만 컬러로 분석한다. $x^t$를 $128 \times 128$ 로 리스케일한 이미지를 입력으로 사용하여, 표면이 실제와 같은지(예: 나뭇잎 무늬나 벽돌 패턴이 섞이지 않았는지)를 예측하도록 학습된다.
- Light Model
- 표지판의 조명 강도를 분석한다. $x^t$의 각 픽셀별 RGB 값 중 최대값을 취해 입력으로 사용한다. 이 모델은 조명이 비정상적인지를 판별하여, 실제 표지판과 투사된 표지판을 구분하는 데 도움을 준다.
- $
x[i, j] = \mathop{\arg\max}_{k} x^{t}[i, j, k]
$
- $
- 표지판의 조명 강도를 분석한다. $x^t$의 각 픽셀별 RGB 값 중 최대값을 취해 입력으로 사용한다. 이 모델은 조명이 비정상적인지를 판별하여, 실제 표지판과 투사된 표지판을 구분하는 데 도움을 준다.
- Depth Model
- 이미지에서 보이는 장면의 깊이(거리)를 input 으로 받는다.이를 얻기 위해 $x^t$와 마지막 프레임의 동일한 공간$(x^{t-1})$ 사이의 optical flow를 계산한다. Optical flow는 2D 벡터 필드이며, 각 벡터는 픽셀 변위를 캡처한다.
특히, OpenCV를 사용하여 Gunner Farneback algorithm [18]를 활용하여 2D 필드 $v$를 얻은 다음, 각 벡터의 각도와 크기를 계산하여 HSV 이미지로 변환한다.- $
x[i, j, 0] = \sin^{-1} (v[i, j, 1]/ \sqrt{v[i, j, 0]^2}) \times 180 / 2 \pi \\
x[i, j, 1] = 255 \\
x[i, j, 2] = norm\_minmax (\sqrt{v[i, j, 0]^2 + v[i, j, 1]^2}) * 255
$
- $
- HSV 이미지는 CNN에 전달되기 전에 RGB 이미지로 변환된다. 이 접근 방식의 중요성은 차량이 움직이는 동안 장면의 암묵적인 3D 뷰를 얻을 수 있다는 것이다. 이를 통해 모델은 단 하나의 카메라만을 사용하여 표지판의 배치와 모양을 더 잘 인식할 수 있다. Figure 14는 다양한 샘플링된 $x^t$를 기반으로 한 모델 입력의 몇 가지 예를 보여준다.

- 이미지에서 보이는 장면의 깊이(거리)를 input 으로 받는다.이를 얻기 위해 $x^t$와 마지막 프레임의 동일한 공간$(x^{t-1})$ 사이의 optical flow를 계산한다. Optical flow는 2D 벡터 필드이며, 각 벡터는 픽셀 변위를 캡처한다.
최종 예측은 이 네 모델의 “다섯 번째 레이어” 활성화 값을 각각 임베딩으로 추출하여 연결(concatenate)한 뒤, 다섯 번째 신경망에 입력하여 진짜/가짜를 분류한다. 전체 네트워크의 학습 가능한 파라미터 수는 1,145,654개이다.
7.2 Experiment Setup
제안된 대응책을 검증하기 위해 (1) 시스템의 탐지 성능, (2) 서로 다른 최첨단 교통 표지판 감지기에 대한 공격 성공률, (3) 모델의 효율성(속도/자원)을 분석한다. 또한 ablation study 를 통해 집단 내에 배치된 각 개별 모델의 중요성을 분석하고, 모델의 성능을 baseline (잘린 이미지에 대해 학습된 단일 CNN 분류기)과 비교한다.
- Dataset
- 학습 및 테스트 데이터를 생성하기 위해 운전석 시점에서 dash cam 을 사용하여 비디오를 녹화했다.
- 첫 번째 비디오 세트는 밤에 도시를 운전하는 데 3시간이 걸렸다. 이러한 비디오에서 추출한 프레임을 \(R_d\)로 표시한다.
- 두 번째 비디오 세트는 팬텀 교통 표지판이 투영된 지역을 운전하면서 녹화되었다.이러한 비디오의 프레임은 \(F_d\)로 표시된다. \(F_d\) 데이터 세트에서 40가지 유형의 표지판을 9개의 다른 표면에 loop 로 투영했다.
- 그런 다음 [3]에 설명된 최고 성능의 교통 표지판 감지기(faster rcnn inception resnet v2)를 사용하여 \(R_d\) 및 \(F_d\)의 모든 교통 표지판을 감지하고 잘랐다. 잘린 각 교통 표지판 \(x^t\)를 수집하여 데이터 세트 \(X\)에 넣었다.
컨텍스트 모델을 학습시키려면 표지판의 부적절한 배치를 모델에 학습시키기 위해 표지판이 포함되지 않은 예(\(R_n\)로 표시)가 필요했다. 이 데이터 세트의 경우 잘린 이미지의 중심에 표지판이 포함되지 않도록 \(R_d\)에서 임의 영역을 잘랐습니다. - 데이터 세트 생성 방법과 샘플 수에 대한 요약은 아래 Figure 10에서 확인할 수 있다.

- 제안된 모델은 이와 유사한 데이터로 학습할 때 실제로 작동할 수 있다. 이는 서로 다른 환경을 운전하면서 캡처한 이미지가 학습 중에 보이지 않는 유사한 환경으로 잘 일반화되기 때문이다 [6 , 20 , 58 , 62 ]. 예를 들어, NVIDIA는 최근 유사한 학습 데이터를 사용하여 자율 주행을 위해 단일 카메라로 물체의 크기와 깊이를 정확하게 예측할 수 있는 방법을 보여주었다 [12]. 대부분의 회사에서는 \(R_d\)를 사용할 수 있으므로 과제는 \(F_d\)를 수집하는 것이다.
따라서 \(F_d\)의 수집을 가속화하기 위해 (1) 자동차 상단에 프로젝터를 장착하고, (2) 임의의 팬텀을 표시하면서 도시 지역을 운전하고, (3) 객체 감지기가 객체를 식별하는 모든 프레임을 저장할 수 있다(잠재적으로 ADAS를 속일 수 있기 때문). 이 접근 방식은 다양한 표면과 다양한 컨텍스트 및 환경에서 다양한 성공적인 팬텀 공격을 빠르게 생성한다.
- 학습 및 테스트 데이터를 생성하기 위해 운전석 시점에서 dash cam 을 사용하여 비디오를 녹화했다.
- Training
- Context, Surface, Light, 및 Depth 모델은 개별적으로 학습된 다음 Combiner 모델은 해당 임베딩에 대해 학습되었다. 데이터와 관련하여 \(X\)의 80%는 모델을 학습하는 데 사용되었고 나머지 20%는 테스트 세트로 평가하는 데 사용되었다. 편향을 줄이기 위해 테스트 세트에는 학습 세트에 없는 표면에 대한 비디오 및 팬텀 투영이 포함되었다. 마지막으로 NVIDIA 2080 ti GPU에서 25 epoch 동안 학습이 수행되었다.
7.3 Experiment Results
7.3.1 Model Performance
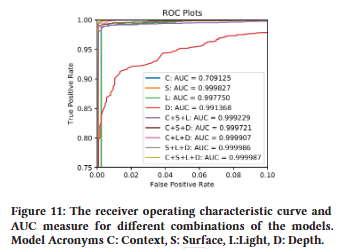
위의 Figure 11에서 Context, Surface, Light, Depth 모델의 조합에 대한 receiver operating characteristic (ROC) 플롯과 ROC 아래 영역 (AUC)을 제시하며, 여기서 네 가지 모두의 조합이 제안된 모델이다. ROC는 모든 가능한 예측 임계값에 대한 true positive rate (TPR) 및 false positive rate (FPR)을 보여주고, AUC는 분류기의 전체 성능 측정값을 제공한다 (AUC=1 : 완벽한 예측, AUC=0.5. : 임의 추측).
임계값을 설정할 때는 절충점이 있다. 임계값이 낮을수록 FPR이 감소하지만 TPR도 감소하는 경우가 많다. 논문의 경우 제안된 모듈이 실제 표지판을 매번 실제 표지판으로 예측하는 것이 중요하다. 왜냐하면 논문의 모듈에 전달되는 표지판의 대다수가 실제이기 때문이다. 따라서 매우 작은 FPR조차도 솔루션을 비현실적으로 만들 것이다.

따라서 위의 Table 2에서 임계값이 0.5(softmax의 기본값)로 설정된 경우와 FPR이 0인 임계값에 대한 모델의 TPR 및 FPR을 제공한다. (softmax의 기본값)인 경우와 FPR이 0인 임계값에 대한 모델의 TPR 및 FPR을 제공한다.
Table 2 에서 볼 수 있듯이 제안된 모델 (C+S+L+D)은 다른 모든 모델의 조합과 baseline 모델($x^t$ $inX$ 에 대해 훈련된 CNN 분류기)보다 성능이 뛰어납니다. 앞서 언급했듯이 결합된 모델은 관련 정보에 집중하고 특정 측면/기능에 덜 의존하기 때문에 기준선 모델보다 성능이 뛰어나다. 또한 차량이 움직이는 동안에만 Depth 모델이 효과적이기 때문에 다른 모델보다 AUC가 낮다.
7.3.2 Ablation Study
네 가지 모델의 조합이 최상의 결과를 제공하므로 각 측면(컨텍스트, 표면, 빛, 깊이)이 실제 교통 표지판과 팬텀 교통 표지판의 차이에 대한 고유하고 중요한 관점을 제공한다는 분명한 징후이다. 몇 가지 경우를 제외하고 각 모델이 고유한 기여를 한다는 추가 증거는 Table 2에서 확인할 수 있다. 여기서 모든 모델 쌍이 단일 모델보다 낫고 모든 세 쌍둥이가 모든 쌍보다 낫다. 전문가 위원회 접근 방식이 효과적이려면 모델 간에 약간의 의견 불일치가 있어야 하므로 이는 중요하다.

Table 3은 각 조합이 테스트 세트에서 갖는 불일치 수를 측정합니다. 흥미롭게도 전체 조합(C+S+L+D)은 불일치 수가 가장 많고 FPR=0에서 가장 높은 TPR을 나타낸다.

Figure 15에서 Combined 모델에 의한 올바른 예측을 초래한 불일치의 몇 가지 시각적 예를 제공한다. 경우에 따라 증거가 있더라도 모델이 단순히 잘못 분류한다. 예를 들어, 때때로 Context 모델은 표지판이 트럭 뒤쪽에 있다는 것을 인식하지 못한다 (Fig. 15의 오른쪽 하단 모서리). 다른 경우에는 모델의 관점에 필요한 증거가 없기 때문에 오분류한다. 예를 들어, 때때로 Context 모델은 표지판이 수평 구조물 위에 떠 있는 것을 비정상적으로 생각한다 (Figure. 15의 왼쪽 상단 모서리). 그럼에도 불구하고, 모든 경우에 다른 모델들이 잘못된 의견과는 반대로 강력한 신뢰 투표를 제공하여 올바른 예측을 이끌어 냈다.

그러나 이 접근 방식이 완벽한 것은 아니다. Figure. 16은 Combiner 모델이 실패한 경우의 예를 제공한다. 여기서 표지판은 진짜이지만 Context 모델만이 그것을 그렇게 식별했다. 그러나 motion blur 때문에 다른 모델들은 강력하게 동의하지 않았다.
7.3.3 Countermeasure Performance
제안된 모듈은 on-board 객체 감지기에 의해 감지된 신뢰할 수 없는 (phantom) 교통 표지판을 필터링한다. 교통 표지판 감지기의 여러 가지 다른 구현이 있기 때문에 특정 phantom에 속는 감지기가 있는 반면 그렇지 않은 감지기도 있을 수 있다. 따라서 시스템 내에서 모듈의 효과를 확인하기 위해 7개의 s.o.t.a 교통 표지판 감지기 [3 ]에 대한 phantom 공격을 평가했다. 감지기에 대한 공격 성공률은 $F_d$의 phantom 표지판 중 표지판으로 식별된 비율로 측정했다.

Table 4에서 countermeasure를 적용하기 전과 후에 각 감지기에 대한 공격 성공률과 다양한 임계값의 영향을 제시한다. 결과는 감지기가 phantom 공격에 매우 취약하며 countermeasure가 테스트 세트에서 거짓 양성이 없는 임계값에서도 효과적인 완화를 제공한다는 것을 보여준다.
따라서 countermeasure는 매일 사용하기에 충분히 안정적이며 (거짓 양성을 거의 만들지 않을 것으로 예상됨) 대부분의 경우 phantom을 감지한다. 그러나 훈련 세트에는 몇 시간 분량의 비디오 영상만 포함되어 있었다. 이 솔루션을 배포하려면 모델을 훨씬 더 큰 데이터 세트에서 훈련하는 것이 좋다. 또한 크기와 각도를 고려하는 추가 모델도 고려하는 것이 좋다.
7.3.4 Adversarial Machine Learning Attacks
countermeasure에 사용된 것과 같은 딥 러닝 모델이 adversarial machine learning 공격에 취약하다는 것은 잘 알려져 있다. 우리 시스템의 한 가지 우려는 공격자가 교통 표지판 감지기를 속이고 모델이 높은 신뢰도로 '진짜'라고 예측하도록 만드는 phantom projection을 만들 것이라는 것이다. 이 공격은 phantom 감지기로 단일 CNN을 사용할 때 비교적 쉽게 달성할 수 있다. 그러나 전문가 위원회는 그러한 공격에 강력하다. 이는 공격자가 투사하는 픽셀만 제어할 수 있고 투사된 이미지의 물리적 속성은 제어할 수 없기 때문이다. 또한 공격자는 비교적 매끄러운 표면에 투사해야 하므로 내용에 관계없이 Context 및 Depth 모델이 공격을 식별하기가 더 쉽기 때문에 제한된다. 따라서 공격자가 Surface Model CNN을 속이더라도 결합된 모델은 여전히 객체를 가짜로 감지하고 공격을 완화한다.
이 개념을 평가하기 위해 [ 46 ]의 프레임워크를 사용하여 각 전문가를 8개의 다른 화이트 박스 adversarial machine learning 회피 공격 [ 5, 8, 9, 21 , 29 , 32, 40 , 48 ]으로 공격했다. 각 전문가 및 공격에 대해 전문가의 정확도와 해당 전문가가 타겟팅될 때 위원회의 정확도를 측정했다.

Figure. 12에서 시각적 예제와 함께 결과를 제시한다. 결과는 위원회가 어떤 한 전문가보다 훨씬 강력하다는 것을 보여준다. 특히 빛과 깊이 전문가를 위해 물리적으로 adversarial sample을 만드는 것이 어렵기 때문에 집단 모델은 표적 공격에 대해 견고하게 유지된다. 다양한 전문가 조합을 공격한 결과는 Appendix의 Table 6을 참조.
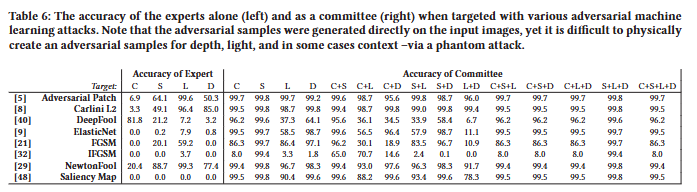
한 가지 예외는 Surface 모델을 타겟팅하는 경우를 제외하고 위원회의 결정에 부정적인 영향을 미치는 IFGSM 방법이다. 그러나 예를 들어 [ 14 , 16, 30 , 37 , 38, 41 , 63 ]과 같이 IFGSM 공격을 구체적으로 완화하는 많은 연구가 있다. 그럼에도 불구하고 adversarial 공격은 고양이와 쥐 게임이며 솔루션이 향후 adversarial 공격에 영향을 받지 않는 것은 아니라는 점에 유의하는 것이 중요하다. 그러나 이러한 결과는 공격자가 (1) 복잡한 물리적 특징(예: 빛과 깊이)을 만들어야 하고, (2) 공격을 수행할 수 있는 위치(context)가 제한되고, (3) 여러 물리적 측면(전문가)을 한 번에 캡처하는 adversarial sample을 생성해야 하기 때문에 위원회 접근 방식이 공격자에게 어려움의 기준을 높인다는 것을 나타낸다.
7.4 Generalization to other Phantom Objects
평가에서 GhostBusters가 phantom 도로 표지판의 context에서 어떻게 작동하는지 보여주었다. 그러나 동일한 접근 방식은 다른 phantom 객체로 일반화된다.
- Light
- phantom 보행자를 고려해보자. 실제 보행자와 비교하여 phantom 보행자는 특히 직사광선에서 다양한 재료(안경, 벨트, 옷 등)의 주저함을 고려할 때 평소보다 더 많은 빛을 방출한다. 또한 phantom이 차 앞 도로에 있는 경우 차량의 헤드라이트가 projection을 포화시키고 많은 세부 사항을 지운다. 이는 헤드라이트가 phantom을 덮고 있기 때문에 4.5m보다 3m에서 더 강렬한 phantom이 필요했던 Figure. 3의 왼쪽에서도 관찰된다.

- Surface
- 도로에 투영될 때(충돌을 유발하기 위해) 이미지는 표면으로 인해 비정상적인 텍스처와 색상 패턴을 받게 된다. 예를 들어 하수구, 균열, 도로 표시 및 아스팔트가 모두 투영된 이미지를 왜곡한다(아래 Figure 17 참조). 도로 표지판과 신호등이 벽 및 기타 수직 표면에 투영될 때도 마찬가지이다.

- 도로에 투영될 때(충돌을 유발하기 위해) 이미지는 표면으로 인해 비정상적인 텍스처와 색상 패턴을 받게 된다. 예를 들어 하수구, 균열, 도로 표시 및 아스팔트가 모두 투영된 이미지를 왜곡한다(아래 Figure 17 참조). 도로 표지판과 신호등이 벽 및 기타 수직 표면에 투영될 때도 마찬가지이다.
- Depth
- 평평한 표면에 투영된 모든 3D object는 깊이 전문가에 의해 3D로 감지되지 않는다. 이는 전경/배경이 없으므로 전체 표면이 프레임 간에 동일한 이동을 하기 때문이다. 예외는 도로 표지판과 같은 2D object가 투영되는 경우이다. 이 경우 의사 결정을 위해 위원회의 다양한 관점의 강점이 활용된다. 반대로 다른 전문가가 실패하면 깊이 전문가는 아래 Figure 15에서 볼 수 있듯이 오탐지를 완화하는 데 도움을 줄 수 있다.

- 평평한 표면에 투영된 모든 3D object는 깊이 전문가에 의해 3D로 감지되지 않는다. 이는 전경/배경이 없으므로 전체 표면이 프레임 간에 동일한 이동을 하기 때문이다. 예외는 도로 표지판과 같은 2D object가 투영되는 경우이다. 이 경우 의사 결정을 위해 위원회의 다양한 관점의 강점이 활용된다. 반대로 다른 전문가가 실패하면 깊이 전문가는 아래 Figure 15에서 볼 수 있듯이 오탐지를 완화하는 데 도움을 줄 수 있다.
- Context
- 도로 표지판의 맥락은 매우 분명하지만 다른 object의 맥락을 포착하기 어려울 수 있다. 일반적으로 디지털 광고판에 표시된 object는 디스플레이 프레임 내에 있으며 불규칙한 표면에 투영된 팬텀(예: 트럭 뒤에 떠 있는 보행자)도 감지된다. 그러나 도로에 투영된 보행자는 길을 건너는 사람처럼 보일 수 있다. 그럼에도 불구하고 위원회는 Table 2에서 입증된 것처럼 이 전문가가 있든 없든 여전히 잘 작동해야 한다. 또한 다양성을 강화하기 위해 이 논문에서 평가되지 않은 새로운 전문가를 추가할 수도 있다. 예를 들어 [12]를 기반으로 한 크기 전문가는 모순되는 크기를 식별하는 데 사용할 수 있다(도로 투영은 Figure 17에서 볼 수 있듯이 수 미터까지 늘어날 수 있음).

8. Conclusions, Discussion & Future Work
본 연구 결과는 컴퓨터 비전 알고리즘에 대한 적대적 머신러닝 공격을 제시한 이전 연구의 결과를 최소화하기 위한 것이 아니다. 아주 짧은 순간의 팬텀 공격은 고려해야 할 추가적인 시각적 스푸핑 class를 나타낸다. 본 연구는 자동차 산업의 오랜 경험에 의문을 제기하거나, 사이버-물리 시스템을 위한 센서 융합의 사용을 할인하거나, 반/완전 자율 주행차를 위한 LiDAR 또는 레이더 사용에 대한 현재 진행 중인 논쟁에서 어떤 편을 들기 위한 것이 아니다[1]. 사실은 레이더 기반의 센서 융합이 반/완전 자율 주행 차량에 가장 안전한 접근 방식이며 Tesla의 최근 보고서에 따르면 Tesla의 오토파일럿이 인간 운전자보다 더 안전하다[59]. 본 연구의 목적은 자율 주행 차량에 대한 이전 공격[65]에서 보여준 것처럼 센서 융합에는 여전히 고려해야 할 edge case가 있음을 입증하는 것이다.
어떤 사람들은 우리가 Tesla가 항상 레이더보다 비디오 카메라를 신뢰하도록 프로그래밍되었다고 주장한다고 생각할 수도 있다. 우리는 Tesla의 엔지니어가 자세한 내용을 제공하지 않았기 때문에 Tesla가 어떻게 프로그래밍되었는지 가설을 세울 수 있을 뿐이다. 그러나 Tesla가 레이더보다 비디오 카메라를 따른 이유는 다른 정책의 결과라고 생각한다. 이전 연구[65]에서는 통합 센서(레이더 또는 초음파 센서)에 스푸핑 및 재밍 공격을 가하여 Tesla가 장애물을 고려하도록 속일 수 있음을 입증했다. 두 경우 모두 자동차는 시각적 검증이 없었음에도 불구하고 단일 센서를 따른다. 이를 염두에 두고 우리는 Tesla가 사전 정의된 수준의 신뢰도를 넘은 경우 단일 센서에서 이루어진 분류를 고려하도록 프로그래밍되어 있다고 믿는다. 이 정책은 Tesla가 추가 검증 없이도 무선 및 초음파 팬텀[65]뿐만 아니라 시각적 팬텀을 고려하는 이유를 설명할 수 있다.
본 연구에서 제기되는 또 다른 질문은 다음과 같다. 아주 짧은 순간의 팬텀 공격을 Tesla에서 사용하는 것과 다른 센서 세트에 의존하는 자동차에 적용할 수 있는가?
시각적 팬텀은 깊이 센서와 비디오 카메라 간의 불일치에 대한 edge case를 나타낸다. 우리는 두 곳의 자율 주행차 제조업체(레벨 4)에 접근하여 아주 짧은 순간의 팬텀 공격에 대한 자동차의 동작을 평가하도록 허용해 달라고 요청했지만 어느 곳도 긍정적으로 응답하지 않았다. 그러나 본 논문의 연구진들은 공격자가 LiDAR 및 비디오 카메라에 의존하는 자율 주행차에 대해 동일한 종류의 과제를 만들 수 있기 때문에 공격을 다른 반/완전 자율 주행차에 적용할 수 있는지 여부에 대한 질문이 관련이 없다고 생각한다. 연구진들의 생각에는 팬텀은 센서 간의 불일치가 있는 경우 자동차가 어떻게 작동해야 하는지에 대한 정책의 결과이다. 이 문제는 최근 표준에서 구체적으로 다루어지지 않아 자동차 제조업체는 자신의 경험을 바탕으로 정책을 구현할 수 있는 공간을 남겨둔다. 연구진들은 이 연구가 이러한 edge case에 대한 지침/표준으로 이어지기를 바란다.
향후 연구로 아주 짧은 순간의 팬텀 공격이 디지털 버스 광고를 통해 원격으로 적용될 수 있는지 여부를 탐구할 것을 제안한다. 또한 일부 CMOS sensor에 의해 근적외선이라는 좁은 주파수 스펙트럼도 캡처된다는 사실을 이용하여 팬텀 공격이 적외선 투영을 사용하여 적용될 수 있는지 여부를 조사할 것을 제안한다(이 사실은 안면 인식 알고리즘[64, 67]을 오도하고, 광학 은폐 채널[22, 45]을 설정하고, 상업용 드론의 FPV 채널의 기밀성을 깨는 데 악용되었다[44]). 완전한 표지판 또는 표지판의 일부가 다른 표지판에 투영되는 특정 종류의 팬텀을 평가하는 것도 흥미로울 것이다. 또한 다른 상업용 ADAS의 팬텀 공격에 대한 견고성을 테스트하고 다른 3D object의 팬텀이 ADAS를 속일 수 있는지 조사할 것을 제안한다(예: 애완 동물, 교통 콘, 신호등).

