Deep Neural Network(DNN)
: hidden layer가 2개 이상인 Neural network를 의미한다.
아래 그림은 4 Layer NN에서 3개의 hidden layer가 있는 경우이다.

layer 0 layer1 layer2 layer3 layer4
- Forward Propagation
아래는 layer0에서 layer1로가는 forward propagation이다.
w11 w12 w13 w14 w15
w21 w22 w23 w24 w25 = w`^[1] //3 x 5 가중치 행렬
w31 w32 w33 w34 w35
5 x 3 가중치 행렬로 만들어주기 위해 전치행렬을 가중치 행렬로 설정한다.
=> W^[1] 은 w`^[1]의 전치행렬이며 size는 5 x 3
size: 5x1 = 5x3 3x1 5x1
z^[1] = w^[1]*x + b^[1]
A^[1] = g(z^[1]) //g는 activation function
이전 layer에서 output이 다음 layer의 input이 된다는 것을 제외하고는 과정이 동일하다.
Z^[2] = W^[2] * A^[1] + b^[2]
A^[2] = g(Z^[2])
...
따라서, l을 layer의 index라고 할 때, forward propagation 은 다음과 같다.
Z^[l] = W^[l] * a^[l-1] + b^[l]
A^[l] = g^[l] ( Z^[l] ) // g는 activation function
- Backward Propagation
이전에 봤었던 얕은 신경망에서의 m training examples 의 backward propagation과 과정은 동일하다.
Back propagation :
dz^[2] = A^[2] - y
dw^[2] = 1/m * A^[1]T * dz^[2]
db^[2] = 1/m * np.sum(dz^[2], axis=1, keepdims = True)
dz^[1] = w^[2]T * dz^[2] * g[1]`(z^[1])
dw^[1] = 1/m * dz^[1] * X^T
db^[1] = 1/m * np.sum(dz^[1])
따라서, l을 layer의 index라고 할 때, m training examples의 backward propagation 은 다음과 같다.
dz^[l] = dA^[l] * g^[l]`(z^[l])
dw^[l] = 1/m * dz^[l] * A^[l-1]T
db^[l] = 1/m * np.sum(dz^[l], axis=1, keepdims=True)
dA^[l-1] = W^[l]T * dz^[l] <=> dA^[l] = w^[l+1]T * dz^[l+1]
dz^[l] = W^[l+1]T * dz^[l+1] * g^[l]`(z^[l])
위의 과정을 통해 parameter인 W, b를 업데이트하여 loss를 줄인다.
하지만, DNN를 효과적으로 개발하는데에 있어서 parameter뿐만 아니라 hyper parameter도 중요하다.
Parameters vs Hyper parameters
- parameters : W, b를 의미한다
- hyper parameters: W, b를 control하는 모든 parameters를 의미한다.
learning rate , iteration 횟수, hidden layer 개수, hidden layer node 수, activation function 등등
Deep learning은 매우 경험적인 과정이다.
idea를 가지고 code로 구현을 하고, 실험을 거친다.
아래 예시를 보자. learning rate가 0.05일 때의 반복문 횟수에 따른 cost function 결과이다.
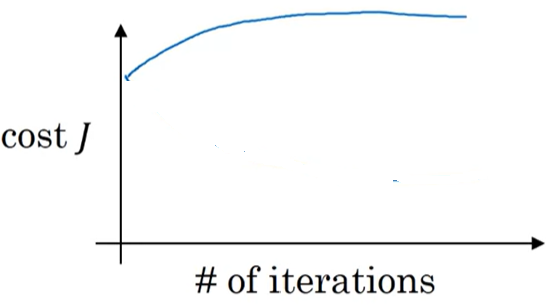
반복을 거침에 따라 cost function value가 증가한다. 즉 수렴하지 않는다. 최종적인 목표는 cost function이 작은 값으로 수렴하기를 기대하기 때문에 learning rate를 더 낮게 바꿔서 실험해보자.
learning rate를 0.01로 설정한 상태로 실험을 거친뒤 아래 결과를 살펴보자.
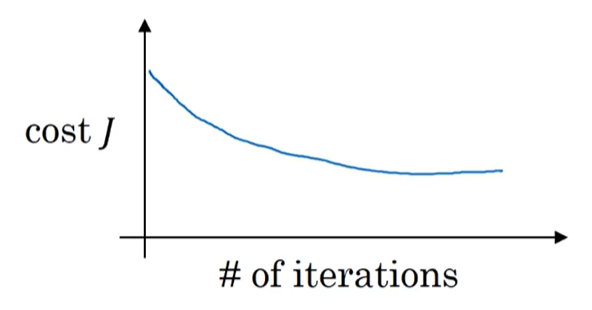
cost function이 낮은 값으로 잘 수렴하는 것을 볼 수 있다.
이처럼 값을 바꿔보면서 실험을 하고 더 좋은 결과가 나오는 hyper parameter를 설정할 수 있다.
'연구실 > 인공지능(Coursera)' 카테고리의 다른 글
| [AI 6주차] Optimization Algorithm (0) | 2024.07.15 |
|---|---|
| [AI 5주차] Deep learning의 실용적인 측면 (0) | 2024.07.02 |
| [AI 3주차] Swallow Neural Network(얕은 신경망) (1) | 2024.06.27 |
| [AI 2주차] 신경망 기초 (0) | 2024.06.25 |
| [AI 1주차] Deep Learning 소개 (0) | 2024.06.25 |



