Why sequence models
Recurrent Neural Network (RNN) 같은 모델은 음성 인식, 자연어 처리(NLP) 영역에 영향을 끼쳤다. 아래는 Sequence model 이 사용되는 몇 가지 예시들이다.
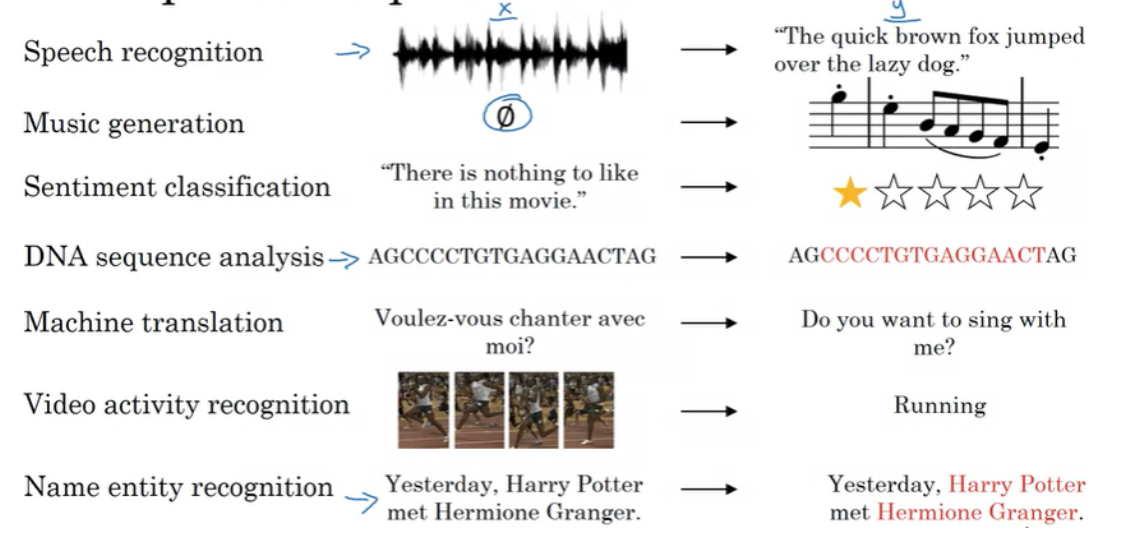
- Speech recognition (음성 인식) : Input X 인 오디오가 Text Output Y 에 mapping 된다. 입력과 출력 모두 sequence data인데, X는 시간에 따라 재생되는 음성이며, Y는 단어 sequence 이다.
- Music generation (음악 생성) : Output Y 만 sequence data 이고, 입력은 빈 집합이거나 단일 정수, 또는 생성하려는 음악의 장르나 원하는 음악의 처음 몇 개의 음일 수 있다.
- Sentiment classification (감정 분류) : Input X는 sequence data이고, 주어진 문장에 대해서 Output 은 별점이 될 수 있다.
- DNA sequence analysis : DNA 염기 서열을 살펴보고 어떤 부분이 일치하는지 label 을 붙이는 일을 할 수 있다.
- Machine translation (기계 번역), Video activity recognition (비디오 동작 인식), Name entity recognition (이름 인식) 등이 있다.
Notation
다음으로 RNN 에서 사용되는 용어들을 정리한다.
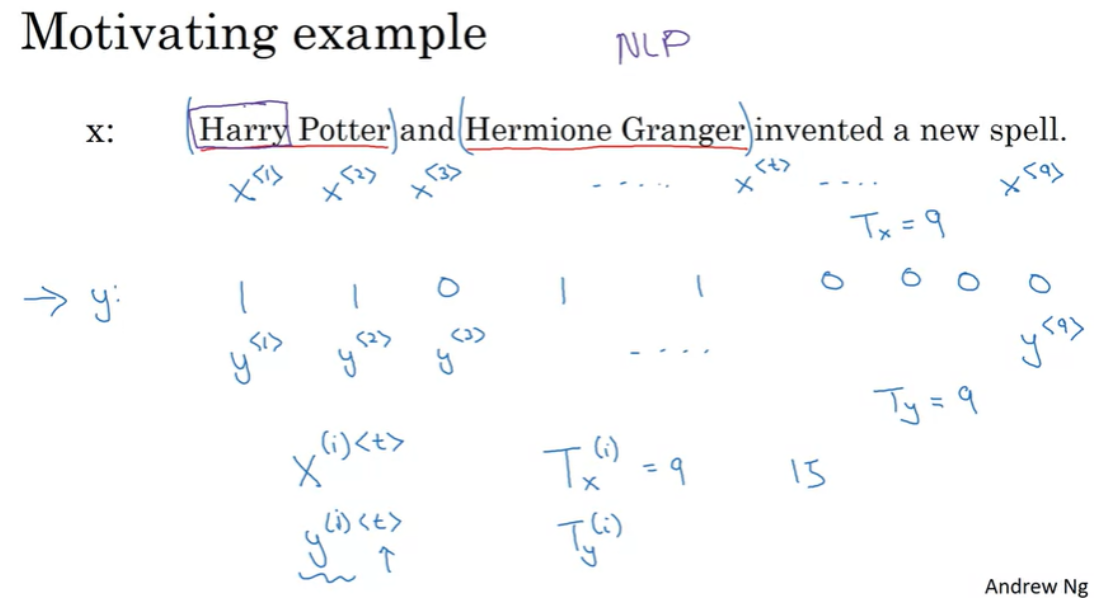
예를 들어서 'Harry Potter and Herimone Granger invented a new spell'이라는 input 가 있고, 이 문장에서 이름을 인식(Name entity recognition) 한다고 했을 때, 각 단어마다 output y를 가지며, output 값은 이름인지 아닌지에 대한 1 / 0의 값을 가진다.
위의 예시에서는 입력 시퀀스 x가 총 9개의 단어로 이루어져 있고, 입력은 총 9개의 feature set을 가지게 된다. 시퀀스의 순서를 나타내기 위해서 위첨자로 $ x^{<1>}, x^{<2>}, \cdots, x^{<t>}, \cdots, x^{<9>} $
로 나타내어서 순서를 나타낸다. 여기서 위첨자 t를 통해서 순서를 나타내며, t는 time sequence에서 유래한다.
유사하게 output y에 대해서도 $ y^{<1>}, y^{<2>}, \cdots, y^{<t>}, \cdots, y^{<9>} $ 로 나타낸다.
시퀀스의 길이는 T에 아래첨자 x를 사용해서 $ T_{x} $ 로 나타내며 여기서는 $ T_{x}=9 $ 이다.
$ T_{y} $ 는 출력 시퀀스의 길이를 의미하며, 여기서는 $ T_{x} $ 와 동일한 값을 가지지만, 다른 값을 가질 수도 있다.
그리고 여러개의 training data가 있을 때, 이전과 동일하게 (i)를 위첨자에 사용해서 i번째 training data를 나타내서, $ x^{(i)<t>} $ 로 나타내며, $ T_{x} $ 가 한 시퀀스의 길이를 뜻하므로, training set의 서로 다른 데이터의 길이는 다를 수 있고, i번째 트레이닝 데이터의 길이는 $ T_{x}^{(i)} $ 로 표기한다.
다음으로 NLP, 자연어 처리를 다루는 방법에 대해서 알아보자.
NLP에서 먼저 결정해야할 것은 시퀀스의 단어 표현 방법이다. 'Harry'라는 단어를 어떻게 표현해야할까?
시퀀스의 단어를 표현하기 위해서는 먼저 Vocabulary(or Dictionary)를 만들어야 한다.
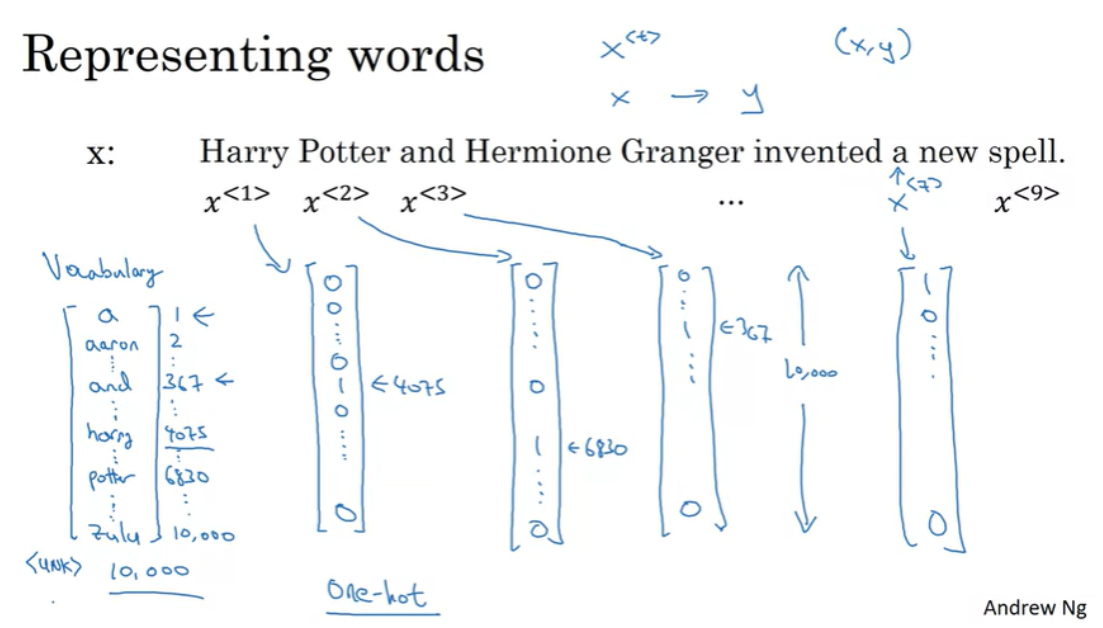
예를 들어 Voca의 첫번째 단어는 'a'이고, 두번째는 'Aaron', 조금 더 지나가면 'and', 또 더 살펴보다보면 'Harry', 'Potter'가 나오고 마지막에는 'Zulu'가 나올 수 있다.
여기서 'harry'는 4075번째, 'potter'는 6830번째에 나왔다. 보통 상용 어플리케이션용의 사전은 대게 3~5만개의 단어를 포함한다. 여기서는 1만개를 사용한다고 가정한다.(단어를 고르는 방법은 자주 사용하는 단어 1만개를 고르거나, 다른 방법을 사용할 수도 있다)
그 다음에 단어를 one hot encoding을 통해서 표현한다.
예를 들어, 'harry'를 나타내는 단어 $ x^{<1>} $ 는 4075번째 위치만 1이고 나머지는 0인 벡터이다.(사전의 4075번째 위치가 'harry'이기 때문)
$ x^{<2>} $ 역시 6830번째만 1이고 나머지는 0인 벡터이다. (one hot은 하나만 1이고 나머지는 0이라는 의미에서 유래)
단어를 표현했으면, 다음 목표는 이렇게 표현된 input x를 output y로 매핑하는 시퀀스 모델을 학습하는 것이다.
Supervised Learning으로 수행되고, x와 y를 포함하는 데이터를 사용한다.
만약에 Voca에 없는 단어가 나오면 어떻게 할까?
그 답은 새로운 Token이나 모르는 단어를 의미하는 가짜 단어를 만들면된다. 즉, <UNK> 와 같이 표시해서 Voca에 없는 단어를 나타낼 수 있다.
Recurrent Neural Network Model (RNN)
RNN 모델에 대해서 살펴보기 전에 기본적인 모델에 대해서 이야기해보자.
이전 예제처럼 9개의 입력 단어가 있을 때, 9개의 단어를 입력으로 받는 모델을 그려보도록 하자. 그렇다면 9개의 one-hot 벡터가 모델에 입력된다. 그리고 몇 개의 hidden layer를 통해서 최종적으로 0 혹은 1의 값을 갖는 9개의 output이 나오게 될 것이다.(1은 사람 이름을 뜻함)
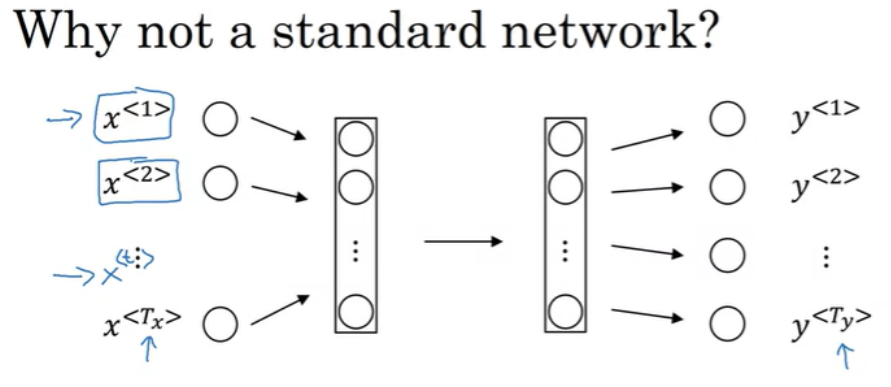
하지만 위와 같은 방법은 잘 동작하지 않는다. 2가지 문제점이 존재한다.
- 입력과 출력 데이터의 길이가 트레이닝 데이터마다 다르다. 모든 트레이닝 데이터가 같은 입력 길이 $ T_{x} $ 를 가지지 않고, 같은 $ T_{y} $ 를 가지지 않는다. 입력에 임의의 값이나 0으로 채워서 최대 길이로 동일하게 맞출 수는 있지만 좋은 방법은 아니다.
- 텍스트의 서로 다른 위치에 있는 동일한 feature(단어)가 공유되지 않는다. 즉, 이름이 첫번째 위치나 t번째 위치에서 나오거나 동일하게 사람 이름이라고 추론하는 것이 올바르다. 이는 CNN에서 학습한 이미지의 특성을 이미지의 다른 부분에 일반화시키는 것과 유사하다.
또한, 이 경우에 각각의 단어가 1만 차원의 one-hot vector이기 때문에 입력 데이터가 매우 크고, 파라미터의 수가 엄청나게 많아 진다.
그렇다면 Recurrent Neural Network(순환신경망)은 무엇일까?

RNN의 기본 구조는 위와 같다.
좌에서 우로 문장을 읽는다면 처음 읽는 단어 $ x^{<1>} $ 를 신경망의 입력으로 사용한다. 그리고 내부 신경망(hidden layer, output layer)를 통해서 사람 이름의 일부인지 예측한다.
그리고, 문장의 두번째 단어 $ x^{<2>} $ 를 읽고, $ y^{<2>} $ 를 예측할 때, $ x^{<2>} $ 만 사용하는 것이 아니라, 첫번째 단어로 연산한 정보의 일부를 사용하게 된다. 구체적으로는 첫번째 시점의 activation이 두번째 시점에 전달된다.
이런 식으로 진행해서 마지막 시점에서 $ x^{<T_{x}>} $ 로 $ y^{<T_{y}>} $를 예측한다.
(해당 예제에서는 $ T_{x} = T_{y} $이다.)
그리고 RNN 신경망 학습을 시작하기 전에 $ a^{<0>} $ 이 사용되는 것을 볼 수 있는데, 이것은 보통 무작위로 초기화하거나, 0으로 초기화한다. 0으로 초기화하는 경우가 가장 일반적이다.
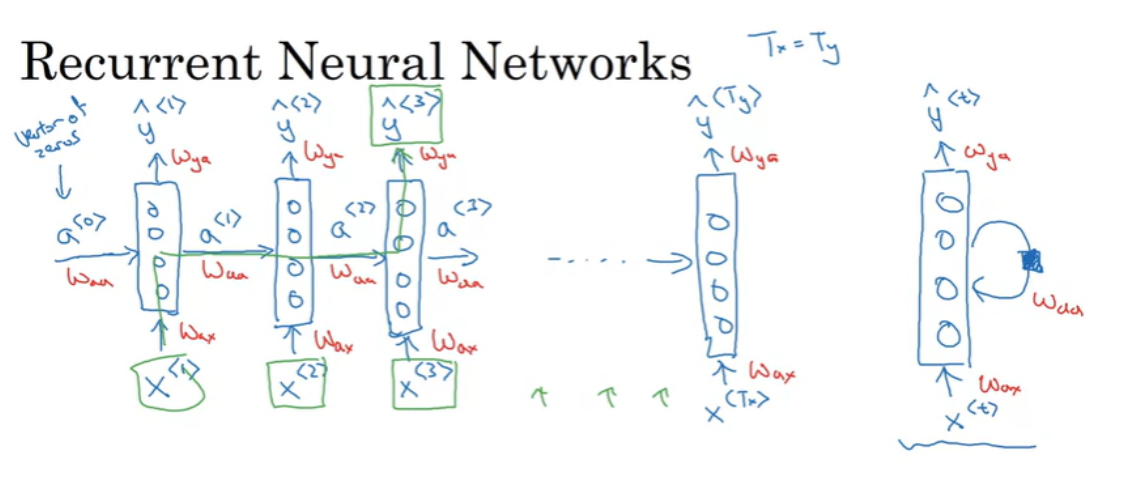
위의 오른쪽 처럼 하나의 NN 만 표현하고 순환하는 표시로 RNN 을 표현하기도 한다. 이는 매 시점에서 parameter 를 공유한다는 것을 의미한다. ( $ W_{aa}, W_{ax}, W_{ya} $ 가 사용됨 )
위 기본 RNN 모델의 단점은, 앞서 나온 정보만을 사용해서 예측을 한다는 것이다. $ y^{<3>} $ 을 예측할 때, $ x^{<4>}, x^{<5>}, x^{<6>} $ 의 정보를 사용하지 않는다. 이는 문제가 될 수 있다.

위와 같은 문장이 있을 때, 첫 두 단어의 정보뿐만 아니라 뒤에 있는 나머지 단어들의 정보를 아는 것도 매우 유용할 것이다. 첫 두세마디만 고려한다면, Teddy 라는 단어가 사람의 이름인지 확실하게 알 수 없다는 것이다. 아래 문장도 마찬가지이다. 첫 두세마디 만으로는 차이를 구별할 수 없다. 이 문제는 양방향으로 반복되는 BRNN 을 통해서 해결할 수 있다.
신경망이 정확하게 어떻게 계산되는지 살펴보자.
우선, forward propagation 이다.

초기에 사용되는 $ a^{<0>} $ 는 일반적으로 0 Vector 로 초기화한다. (단, $ g_{1} = tanh / Relu, g_{2} = sigmoid $)
$ a^{<1>} = g_{1} (W_{aa}*a^{<0>} + W_{ax}*x^{<1>} + b_{a}) $ 이고,
$ \hat{y}^{<1>} = g_{2} (W_{ya}*a^{<1>} + b_{y}) $ 이다.
이를 일반화하면 다음과 같다.
$ a^{<t>} = g (W_{aa}*a^{<t-1>} + W_{ax}*x^{<t>} + b_{a}) $ 이고,
$ \hat{y}^{<t>} = g (W_{ya}*a^{<t>} + b_{y}) $ 이다.
이를 조금 단순화하면 다음과 같이 표현할 수 있다.
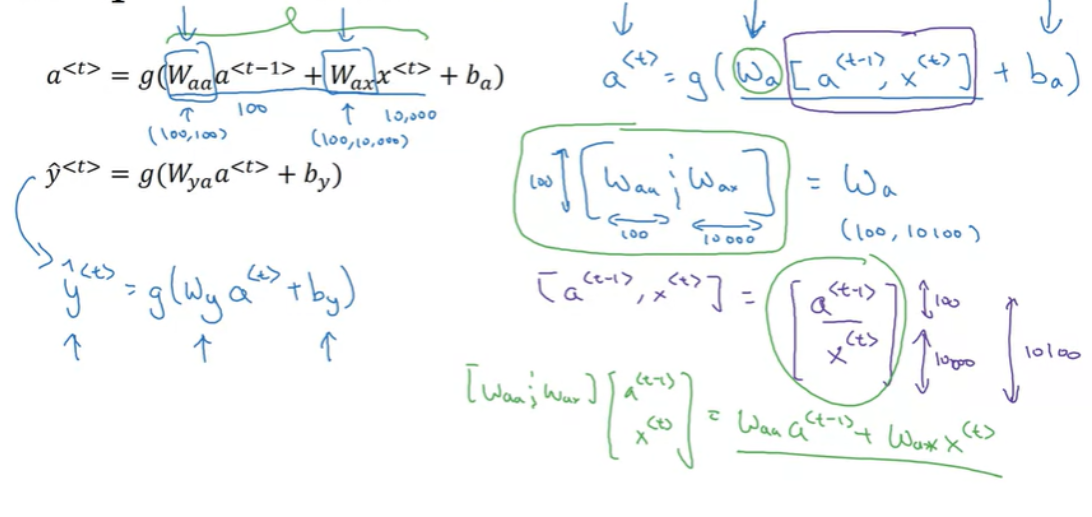
$ a^{<t>} = g (W_{a}[a^{<t-1>}, x^{<t>}] + b_{a}) $
$ W_{a} $ 는 $ [W_{aa} ⋮ W_{ax}] $ 를 의미하는데, 만약 a 가 100차원이고, x가 10000차원의 vector라면, $ W_{aa} $ 는 (100, 100) 의 차원을 갖고, $ W_{ax} $는 (100, 10000)의 차원을 갖게 되고, 두 가중치를 연결하면 $ W_{a} $ 는 (100, 10100) 차원의 가중치가 된다.
$ W_{a} $ 와 연산되는 $ [a^{<t-1>}, x^{<t>}] $ 는 $ \begin{bmatrix} a^{<t-1>} \\ x^{<t>} \end{bmatrix} $ 를 의미하고, 10100 차원의 vector 가 된다.
$ \hat{y}^{<t>} = g(W_{y}*a^{<t>} + b_{y}) $ 으로 표현할 수 있다.
이제, backward propagation 을 살펴보자.

일단, 이전 강의 내용에서 살펴봤드시, $ W_{a}, b_{a} $ 를 통해서 $ a^{<t>} $ 를 구하고, $ W_{y}, b_{y} $ 를 통해서 예측값 $ \hat{y}^{<t>} $ 를 구한다. 그리고 Back propagation 을 계산하기 위해 loss function 을 통해서 실제 결과과 예측값의 Loss(error) 를 계산하고, 총 loss 값을 구한다. Cross Entropy Loss (Logistic regression Loss) 를 사용할 수 있는데, 각 element의 loss 와 총 loss는 다음과 같다.
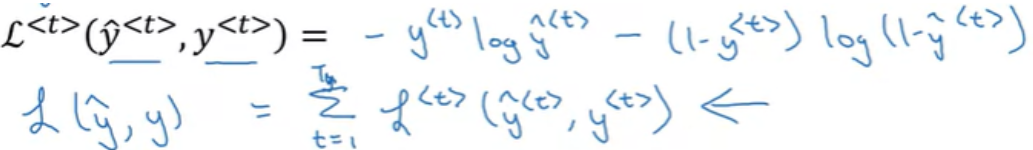
즉, 최종 loss 는 시간별 각각 loss의 합이다.
그리고 Back propagation 을 하는데, 오른쪽에서 왼쪽으로 계산된다.

FP가 시간 순서로 전달하는 것과 반대로 BP는 시간을 거꾸로 가는 것과 같아서 Backpropagation through time(BPTT)라고 부른다.

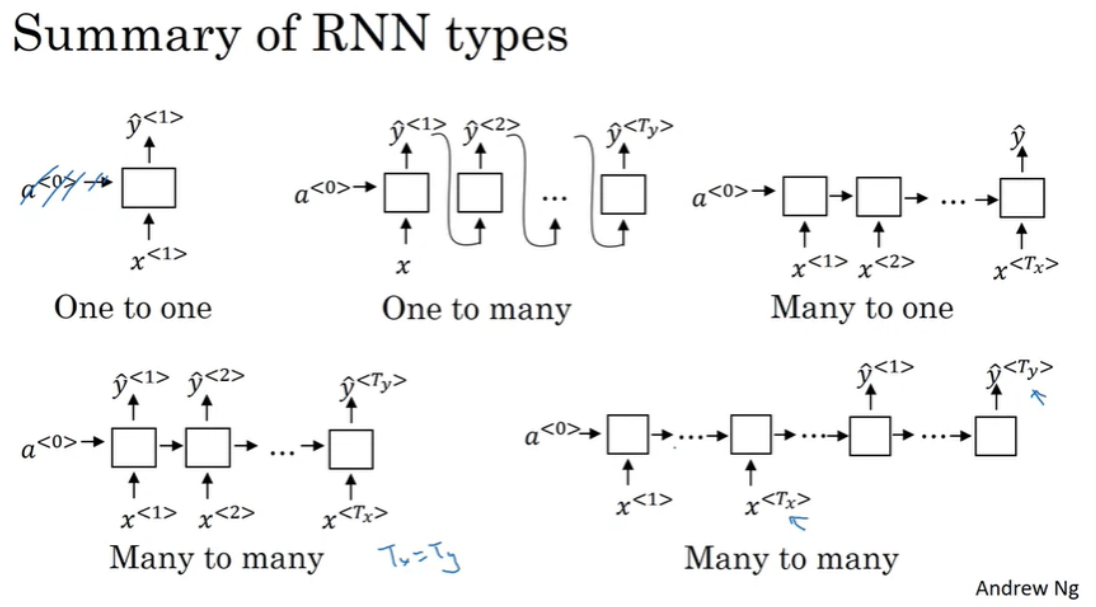
지금까지 RNN 아키텍처에서는 $ T_{x} $ 와 $ T_{y} $ 가 동일한 경우를 살펴보았다. 하지만 항상 같지 않을 수 있으며, 다양한 RNN 아키텍처를 살펴보도록 하자.

위는 초반에 보여준 시퀀스 데이터의 예시들이다. x, y가 모두 시퀀스 데이터거나, x가 빈 집합일 수도 있거나, 하나의 입력일 수 있으며, y가 시퀀스가 아닐 수도 있다.
이전 예제들처럼, $ T_{x} = T_{y} $ 라면 Many-to-many 아키텍처라고 하고, 아래와 같이 모델링할 수 있다.

만약 Sentiment classification처럼 x는 텍스트이지만, y가 0/1의 값을 갖는 output이라면 Many-to-one 아키텍처로 다음과 같이 모델링 할 수 있다.

물론 one-to-one 아키텍처도 있으며, 단순한 신경망과 동일하다.

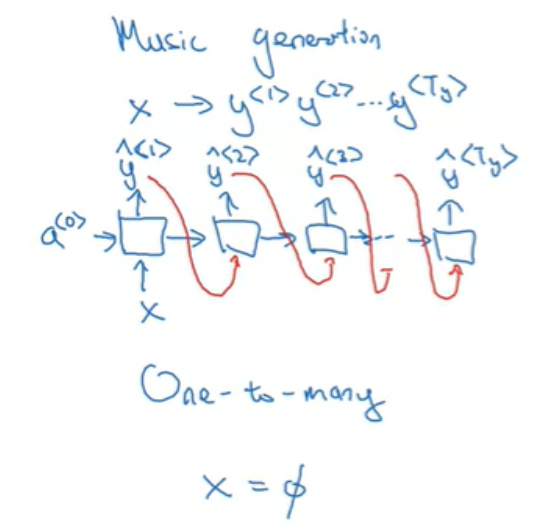
Music generation과 같은 모델은 입력이 정수일 수도 있고, 어떤 음악 장르나 원하는 음악의 첫 음표일 수도 있으며, 어느 것도 입력하고 싶지 않다면 null 입력일 수도 있고, 항상 0일 수도 있다. 이런 모델은 One-to-many 아키텍처이며, 다음과 같이 하나의 input x와 시퀀스 output y를 가질 수 있는 모델이 된다.
아키텍처는 이렇게 Many-to-many, Many-to-one, One-to-one, One-to-many으로 분류할 수 있는데, Many-to-many에서 다른 아키텍처들도 있다.
기계번역(machine translation)는 Many-to-many 아키텍처지만, 입력과 출력의 길이가 다를 수 있다. $ T_{x} = T_{y} $

위와 같은 모델에서 입력을 받는 부분은 encoder, 그리고 출력을 내는 부분을 decoder라고 부른다.
요약하면 아래와 같다.
Language model and sequence generation
Language Modelling은 LNP에서 가장 기본적이고 중요한 작업 중 하나이다. RNN을 사용해서 Language model을 만드는 방법을 배워보도록 할것이다.
language modelling(언어 모델)이란 무엇일까?
우리가 음성 인식(Speech recognition) 시스템을 만들고 있다고 가정해보자.

The apple and pear salad라는 문장을 들었을 때, 위 두 가지 문장이 있다면 두 번째 문장이 더 가능성이 있다고 생각할 것이다. 여기서 두 번째 문장을 선택하는 방법은 두 문장의 확률이 얼마인지 알려주는 언어 모델을 사용하는 것이다.
예를 들어서, 모델이 첫 번째 문장에 대한 확률은 $ 3.2 x 10^{-13} $ 으로 지정하고, 두 번째 문장의 확률은 $ 5.7 x 10^{-10} $ 으로 지정하는 것이다. 따라서 음성 인식 시스템은 두번째 문장을 선택하게 된다.

이러한 언어 모델은 RNN을 사용해서 만들 수 있는데, 이런 모델을 만드려면 large corpus of english text를 포함하는 training set이 필요하다. (corpus라는 단어는 NLP 용어로 큰 영어 문장들을 의미한다.)
언어 모델의 기본 작업은 문장을 입력하는 것인데, 이 문장은 $ y^{<1>}, y^{<2>}, \cdots $로 표현하겠다. 언어 모델에서 문장을 input x가 아닌 output y로 표시하는 것이 유용하다.

위와 같은 'Cats average 15 hours of sleep a day.'라는 문장이 있다고 해보자.
첫 번째로 해야할 일은 이 문장을 토큰화하는 것이다. 토큰화를 통해서 단어들로 분리하고, 단어들을 Voca의 index를 통해 one-hot vector로 매핑한다. 한 가지 추가 작업으로는 문장이 끝난다는 의미인 라는 토큰을 추가한다. (마침표를 토큰으로 사용할 수 있는데, 여기서 마침표는 무시했다.)
만약 아래 문장처럼 Mau라는 단어가 Voca에 없다면 <UCK> 라는 토큰으로 대체할 수 있다.
그리고 RNN architecture 는 다음과 같다.
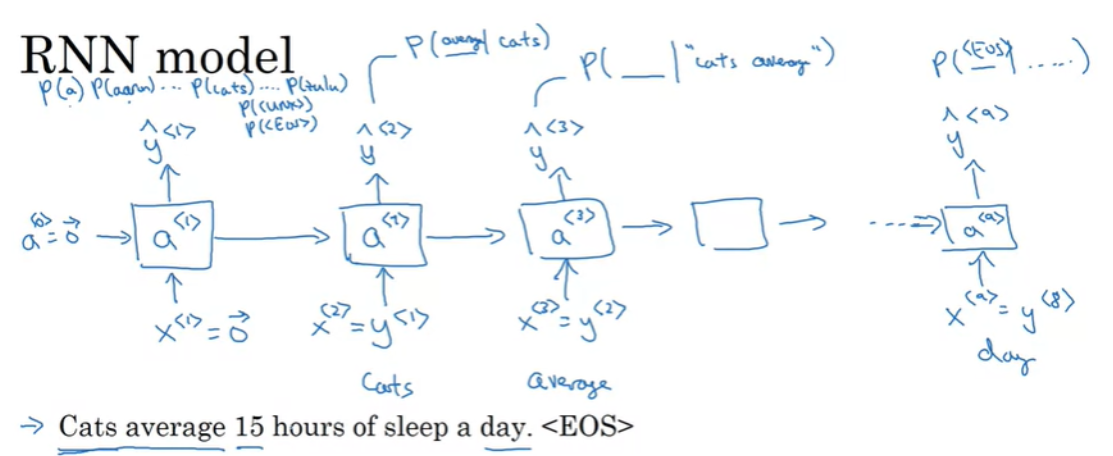
첫 번째 $ x^{<1>} $ 와 $ a^{<0>} $ 은 0 vector로 설정하고, $ a^{<1>} $ 과 $ \hat{y}^{<1>} $를 계산한다.
여기서 $ \hat{y}^{<1>} $ 는 softmax output이며, 첫 번째 단어가 존재할 확률을 의미한다. 이 예제에서는 첫 번째 단어 cats가 될 것이다.
그리고 다음 RNN step이 진행되고 $ a^{<1>} $ 를 가지고 다음 단계를 진행한다. 여기서 $ x^{<2>} $ 는 $ y^{<1>} $ 가 되며, 우리는 이제 모델에 올바른 첫 단어인 cats를 입력하게 된다.
그리고 이 단계에서 softmax output에 의해서 다시 예측되고 그 결과는 첫 번째 단어가 cats일 때의 다른 Voca 단어들의 확률이 될 것이다.
그리고 세번째 단계에서 $ x^{<3>} = y^{<2>} $이고, 이전 단어 'cats average'를 가지고 세 번째 단어의 확률을 예측하게 된다.
그렇게 계속 진행하면 마지막 $ \hat{y}^{<9>} $ 의 output을 내보내고, 이 값은 EOS가 될 것이다.
이렇게 예측한 후에 Loss를 구하는데, 전체 Loss는 각 output의 Loss의 합이 된다.

세 개의 단어를 가지는 문장으로 정리해보자면, 첫 번째 단계에서 softmax output은 $ y^{<1>} $ 의 확률을 알려주고, 두 번째는 이전 단어가 $ y^{<1>} $일 때, $ y^{<2>} $의 확률, 세 번째는 이전 단어가 $ y^{<1>}, y^{<2>} $일 때 $ y^{<3>} $의 확률을 알려주게 된다. 즉, $ P(y^{<1>}, y^{<2>}, y^{<3>}) $ 은 다음과 같다.
$ P(y^{<1>}, y^{<2>}, y^{<3>}) = P(y^{<1>})*P(y^{<2>}|y^{<1>}) * P(y^{<3>}|y^{<1>}, y^{<2>}) $
Sampling novel sequences
Sequence model 을 학습한 후에, 학습한 내용을 비공식적으로 파악할 수 있는 방법 중의 하나는 sample novel sequence 를 갖는 것이다.
아래와 같은 구조를 통해 train 을 진행한다.

그리고 sampling을 진행하는데, 샘플링의 과정은 다음과 같다.

$ a^{<0>}, x^{<1>} $ 는 0 vector이고, 첫 번째로 softmax output $ \hat{y}^{<1>} $ 를 출력한다. 이것은 각 단어의 확률이 얼마나 되는지 알려주는데, 이 벡터를 사용해서(numpy의 np.random.choice를 통해) 무작위로 첫 번째 단어를 샘플링 할 수 있다. 그런 다음 두 번째 단계로 넘어간다. 두 번째 단계에서는 샘플링한 값을 $ x^{<2>} $ 로 사용한다.
이와 같은 과정을 계속 반복하는데, 예측값이 EOS Token이 될 때까지 샘플링을 반복하거나, 또는 정해진 샘플링 횟수를 정하고 그 단계에 도달할 때까지 계속하도록 할 수도 있다. 이것이 RNN 모델에서 무작위로 선택된 문장을 생성하는 방법이다.
지금까지 우리는 단어 수준의 RNN을 만들어 봤지만, 문자 수준의 RNN도 만들 수 있다.

즉, Training set는 개별 문자로 토큰화된다. (a, b, c, ..., A, B, C, ... 등으로)
문자 수준의 언어 모델을 사용하면 알 수 없는 단어에 대해 걱정할 필요가 없다.
하지만, 문자 수준은 입력이 훨씬 더 긴 배열로 이루어지기 때문에 문장의 초기 부분이 문장의 뒷부분에도 영향을 많이 줄 때의 성능이 단어 수준의 언어 모델보다 낮다.
다음은 실제 언어 모델의 사례이다.

뉴스 기사로 학습된 시퀀스 모델은 왼쪽과 같은 텍스트를 생성하고, 셰익스피어의 책에 의해 훈련된 모델은 셰익스피어가 쓴 것과 같은 텍스트를 생성한다.
Vanishing gradients with RNNs
Basic RNN 모델의 문제점 중의 하나는 Vanishing gradient 문제가 발생할 수 있다는 것이다.
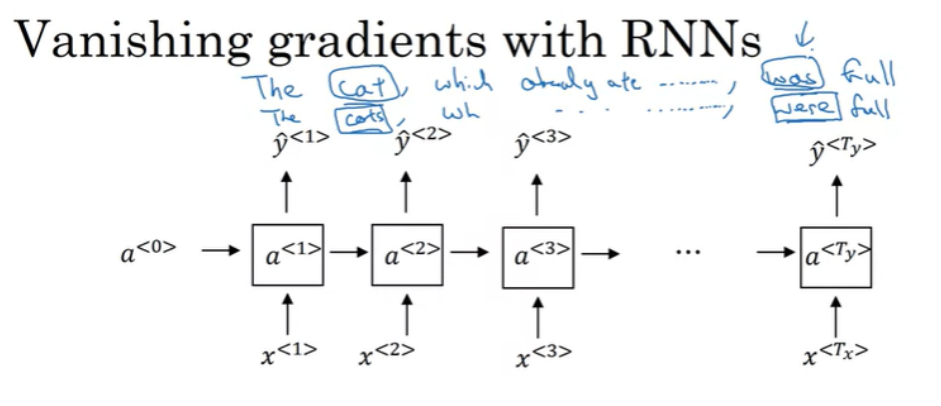
이 예시는 문장의 단어가 긴 시간동안 의존성을 가지는 예시이다. 즉, 문장 초반부의 단어가 문장 후반부에 영향을 끼칠 수 있다는 것인데, RNN은 이와 같은 장기적인 의존성을 확인하는데 효과적이지 않다. (긴 시퀀스를 처리하는데 한계가 존재)
즉, cat나 cats처럼 단수/복수 명사가 문장 초반에 존재했다라는 것을 기억하고 있어야 제대로된 예측을 할 수 있는데, RNN의 경우에는 가까이에 있는 것에 영향을 더 많이 받는다. $ y^{<3>} $ 은 $ y^{<3>} $ 에 가까이 있는 값(입력)에 영향을 받는다. 이것이 Basic RNN 알고리즘의 약점이다.
Deep layer NN에 대해서 언급할 때, gradient가 기하급수적으로 감소해서는 안되고, 또한 기하급수적으로 증가해서도 안된다고 했었다. 여기서는 Vanishing gradient에 대해서 포커스를 맞추고 있지만, Exploding gradient가 최근 더 큰 문제로 대두되고 있는데, gradient가 너무 커져버리면, 네트워크의 매개 변수가 완전히 엉망이 되기 때문이다. 이 경우에는 gradient clipping을 통해서 어느 정도 해결할 수 있다.
Vanishing gradient를 해결하는 효과적인 해결책과 long-range dependency를 유지하는 방법에 대해서 알아보자.
Gated Recurrent Unit (GRU)
앞서 Basic RNN이 어떻게 동작하는지 살펴보았고, 이번에는 GRU라는 조금 더 긴 시퀀스를 잘 캡처(장기의존성 문제)하고, Vanishing Gradient 문제를 해소할 수 있는 GRU에 대해서 살펴보도록 하자.
GRU는 다음에 나오는 LSTM과 유사하지만, 조금 더 간략한 구조를 가지고 있다.

GRU를 간단하게 표현하면 위와 같다. 여기서 새롭게 나타나는 c는 memory cell을 의미하며 이전 정보들이 저장되는 공간이다. 이전 정보가 $ c^{<t-1>} = a^{<t-1>} $ 를 통해 전달되고, 이전 정보와 현재 input $ x^{<t>} $ 와 결합하여 다음 time step으로 전달된다. 즉, 이전 예시처럼 문장 앞쪽의 단수/복수 정보가 뒤쪽까지 전달되어서 'was'를 예측하는데 영향을 끼칠 수 있게 된다.
여기서 크게 두 가지 연산이 존재하는데, 우선 이전 정보와 현재 입력을 통해서 $ \tilde {c}^{<t>} $ 를 연산한다.
$ \tilde {c}^{<t>} = tanh(W_{c} [c^{<t-1>}, x^{<t>}]+b^{c}) $
이 연산은 현재 time step에서 다음 time step으로 전달할 정보들의 후보군을 업데이트하는 것이다.
그리고 Update gate $ Γ_{u} $ 를 통해서 어떤 정보를 업데이트할지 결정하게 되는데, 아래와 같이 계산된다.
$ \Gamma _{u} = \sigma(W_{c} [c^{<t-1>}, x^{<t>}]+b^{u}) $
그리고 최종적으로 다음 time step으로 전달될 $ c^{<t>} $ 는 다음과 같이 계산된다.
$ c^{<t>} = \Gamma_{u} * \tilde{c}^{<t>} + (1-\Gamma_{u}) * c^{<t-1>} $
즉, 현재 time step에서 업데이트할 후보군과 이전 기억 정보들의 가중치합으로 계산된다. 여기서 Gate는 어떤 정보를 더 포함시킬지 결정하는 역할을 하게 되는 것이다. ∗ 는 element-wise 곱을 의미한다.
추후에 LSTM에서 배우겠지만, LSTM의 Forget gate와 Input gate를 합쳐놓은 것과 유사하다.

Full GRU에서는 Update gate 외에도 Reset Gate가 존재하며, 이전의 정보를 적당히 리셋시키는 목적으로 sigmoid 함수를 출력으로 사용해 0 ~ 1사이의 값을 이전 정보에 곱해주게 된다.
Full GRU는 다음과 같은 구조를 갖는다. 여기서 h는 c=a를 의미한다.

Long Short Term Memory (LSTM)
LSTM 은 GRU 보다 일반적으로 더 많이 사용되는 장시간 단기 메모리 unit 이다.

GRU보다 조금 더 복잡한데, 우선 이전 time step에서 전달받는 input이 $ c^{<t-1>} , a^{<t-1>} $로 추가된다.
그리고 Forget gate, Update gate, Output gate을 통해서 각각의 연산을 수행하고, tanh를 통해서 $ \tilde{c}^{<t>} $ 를 연산하는데, 이전 GRU에서 언급했듯이 이것은 현재 time step에서 다음 time step으로 업데이트할 정보들의 후보군을 의미한다.
핵심 아이디어는 현재 time step의 정보를 바탕으로 이전 time step의 정보를 얼마나 잊을지 정해주고(Forget gate), 그 결과에 현재 time step의 정보의 일부(Update gate와 $ \tilde{c}^{<t>} $ 의 연산결과)를 더해서 다음 time step으로 정보를 전달한다.
LSTM은 다음과 같은 과정을 통해서 계산된다.
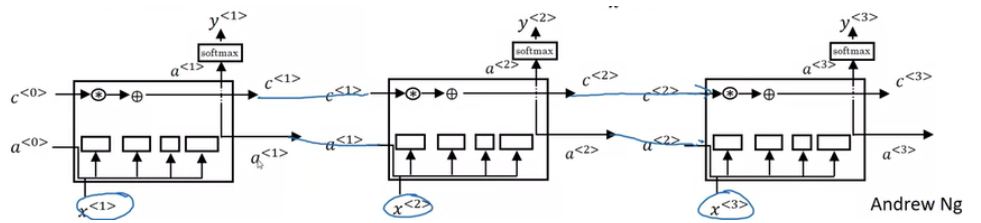
GRU와 LSTM을 비교했을때, 어느 것이 우월하다고 할 수 없고, 강점을 보이는 분야가 조금 다르다. LSTM이 조금 더 먼저 발견되었고, GRU는 비교적 복잡한 LSTM 모델을 단순화한 것이다.
GRU의 장점은 LSTM에 비해서 훨씬 단순하고, 따라서 훨씬 더 큰 네트워크를 만드는 것이 쉽다. (두 개의 gate만 존재하기 때문에 연산량이 적다.) LSTM의 다소 모델이 크지만, 3개의 gate가 존재해서, 보다 성능이 좋고 효과적일 수 있다.
Bidirectional RNN (BRNN)
지금까지 RNN 의 가장 기본적인 building block 들을 살펴보았다.
추가로 훨씬 더 강력한 모델을 만들 수 있는 두 가지 아이디어가 있는데, 하나는 Bidirectional RNN (BRNN) 이다.
BRNN 은 주어진 sequence 에서 이전 시점과 이후 시점의 모든 정보를 참조할 수 있다.
다른 하나는 Deep RNNs 이고 이후에 자세하게 설명할 것이다.

전에 살펴본 사람 이름을 찾는 모델에서의 예시이다. 위의 단방향 RNN 모델이 있을 때, 세번째 단어인 Teddy가 이름인지 아닌지 확인해보기 위해서는 첫번째, 두번째 단어만으로는 충분하지 않다. 즉, 더 많은 정보가 필요하다는 것이다.
이런 경우에 BRNN이 위 문제를 해결할 수 있다.
예를 들어 4개의 입력(4개의 단어로 이루어진 문장)이 있다고 가정해보자.

BRNN은 위와 같은 구성을 가질 수 있는데, 보라색 cell들을 통해서 앞에서부터 정보를 읽어나가고, 초록색 cell들은 역방향으로 입력 정보를 읽어나가게 된다. 그리고 두 cell의 결과를 통해서 예측값을 계산한다.
따라서 과거와 미래 정보를 모두 참조하여 예측하게 된다.
여기서 block cell은 RNN, GRU, LSTM 어느 블록이든 상관없다.
이처럼 BRNN을 통해서 전체 시퀀스의 정보들을 참조해서 예측할 수 있지만, 단점은 예측을 하기 전에 전체 데이터 시퀀스가 필요하다는 것이다. 예를 들어, 음성 인식 시스템을 만들어서 연설을 입력받을 때, 연설이 끝날 때까지 기다렸다가 그 연설 데이터를 처리해서 예측할 수 있을 것이다. (실제 음성 인식 시스템은 표준의 BRNN보다 조금 더 복잡한 모듈이다.)
Deep RNNs
지금까지 본 RNN 은 꽤 잘 동작할 것이다. 그러나 조금 더 복잡한 기능을 학습하는 경우에는 RNN 을 여러 Layer로 쌓아서 더 깊은 모델을 구현할 수 있다.
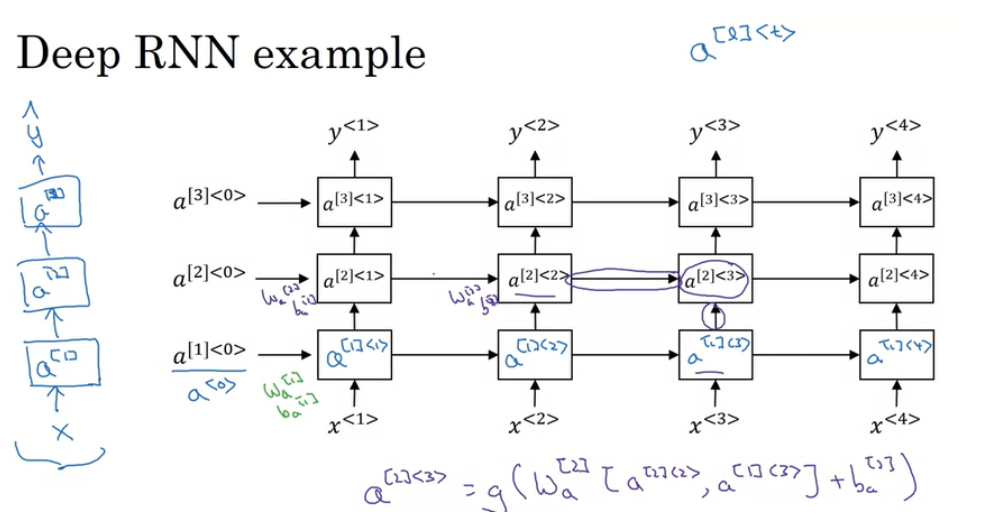
위의 예시에서는 3개의 layer로 쌓았지만, 더 많이 쌓을 수 있다.
'연구실 > 인공지능(Coursera)' 카테고리의 다른 글
| [AI 14주차] Sequence models & Attention Mechanism (0) | 2024.08.19 |
|---|---|
| [AI 13주차] Natural Language Processing & Word Embeddings (0) | 2024.08.18 |
| [AI 11주차] Face Recognition (얼굴 인식) & Neural Style Transfer(신경 스타일 전송) (1) | 2024.08.10 |
| [AI 10주차] Object Detection (1) | 2024.08.09 |
| [AI 9주차] 심층 컨볼루션 모델(Deep convolution model) (0) | 2024.08.07 |



