Word Representation
이전 내용에서 RNN, GRU, LSTM에 대해서 배웠고, 이번주에서는 NLP에 어떤 아이디어들을 적용할 수 있는지 살펴보도록 할 것이다. NLP에서 중요한 아이디어 중의 하나는 Word Embedding(단어 임베딩)이다.

이전에 사용했던 1만개의 단어에 대해서 우리는 one-hot encoding을 통해서 단어를 표시했다. 즉, Man은 5391의 index를 갖고 있으며, 10000 dimension의 벡터에서 5391번째 요소만 1이고 나머지는 다 0으로 표시되는 벡터로 나타낼 수 있다. $ O _{5391} $ 로 나타내며, O는 one-hot vector를 의미한다.
one-hot encoding의 약점 중의 하나는 각 단어를 하나의 object로 여기기 때문에 단어 간의 관계를 추론할 수 없다는 것이다. 예를 들어, I want a glass of orange _______ 를 통해서 빈칸에 juice가 들어가도록 학습했다고 하더라도, I want a glass of apple _______ 이라는 입력이 들어왔을 때, apple을 orange와 비교해서 비슷하다고 여겨서 juice를 추론할 수가 없다는 것이다.
두 개의 서로 다른 one-hot vector 사이에서의 곱셈 결과는 0이기 때문에, king/queen, man/woman 같은 관계를 학습할 수 없다.
따라서, 위와 같은 문제를 해결하기 위해서 Word Embedding을 통해서 각각의 단어들에 대해 features와 values를 학습하는 것이 필요하다.

단어 임베딩은 위와 같은 matrix를 갖는다. row는 feature들을 의미하고, Gender/Royal/Age/... 등이 될 수 있다. 각 col은 Voca 에 존재하는 단어들이다. 그래서 Man이라는 단어를 보면 Gender에 해당하는 값이 -1에 가깝고, Woman은 1에 가까운 것을 볼 수 있다. 서로 반대되는 개념이기 때문에 두 합이 0에 가깝게 되는 것이다. Apple이나 Orange의 경우에는 성별과 거의 연관이 없기 때문에 Gender에 해당되는 값이 0에 가까운 것을 확인할 수 있다.
이처럼 워드 임베딩을 통해서 각 특징에 대한 값들을 갖는 임베딩 행렬(Embedding Matrix)를 얻을 수 있다.
Man의 임베딩 벡터는 $ e_{5391} $ 로 표현할 수 있고, e는 embedding을 의미한다.
- I want a glass of orange juice.
- I want a glass of apple _______.
워드 임베딩을 통해서 juice 앞의 apple과 orange과 유사하다는 것을 추론할 수 있기 때문에 apple 다음에 juice가 온다는 것을 더 쉽게 예측할 수 있다.
다만, 워드 임베딩에서 각 row가 어떤 특징을 의미하는지 해석하기는 어렵지만, one-hot encoding보다 단어간의 유사점과 차이점을 더 쉽게 알아낼 수 있는 장점을 갖고 있다. 보통 feature의 개수로는 300 dimension을 많이 사용한다.
word embedding matrix 를 조금 더 쉽게 이해하기 위해서 시각화를 할 수 있다.
이를 위해 사용되는 알고리즘은 t-SNE 알고리즘이다.

t-SNE 알고리즘은 embedding matrix 를 더 낮은 차원으로 (여기서는 2D) mapping 해서 word 들을 시각화하며, 유사한 단어들은 서로 가까이에 있는 것을 확인할 수 있다.
Using word embeddings
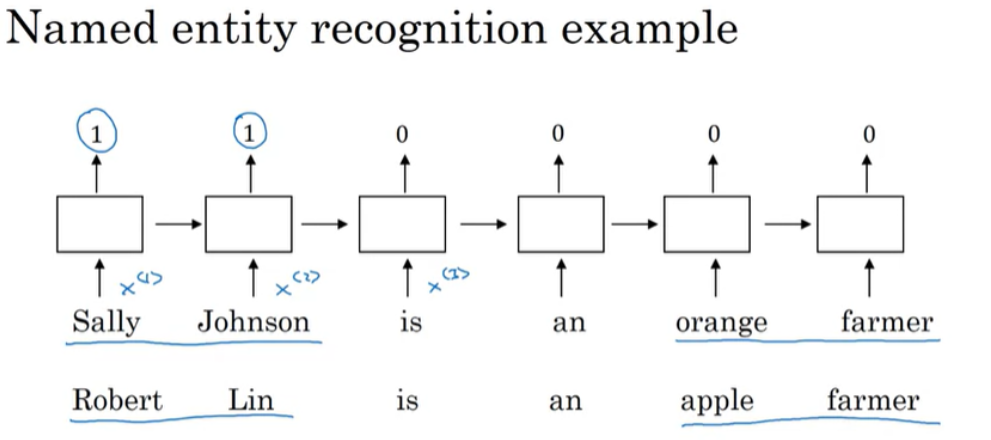
기존의 이름을 인식하는 예제를 가지고 살펴보자.
'Sally Johnson is an orange farmer'라는 example에서 Sally Johnson이 이름이라는 것을 확실히 하기 위한 방법 중의 하나는 orange farmer가 사람임을 알아내는 것이다. one-hot encoding이 아닌 word embedding을 사용해서 학습한 후에, 새로운 example 인 'Robert Lin is an apple farmer'에 대해서 apple이 orange와 유사하다는 것을 알기 때문에 Robert Lin이 사람 이름이라는 것을 더 쉽게 예측할 수 있다.
만약 apple farmer가 아닌 많이 사용되지 않는 과일인 'durian cultivator'라면 어떻게 될까?
training set의 수가 적고, training set에 durian과 cultivator가 포함되지 않을 수 있다. 하지만, durian이 과일이라는 것을 학습하고, cultivator가 사람을 나타낸다는 것을 학습한다면 training set에서 학습한 orange farmer에서 학습한 것을 durian cultivator에도 일반화하게 될 것이다.
단어 임베딩이 이렇게 일반화할 수 있는 이유 중의 하나는 단어 임베딩을 학습하는 알고리즘이 매우 큰 단어 뭉치들을 통해서 학습하기 때문이다.(10억~1000억개의 단어)
또한, 우리가 적은 수의 training set을 가지고 있다고 하더라도, Transfer Learning을 통해서 미리 학습된 단어 임베딩을 가지고 학습할 수 있다. (꽤 좋은 성능을 보여준다)

일반적인 NLP 작업에서 word embedding 은 위와 같은 과정으로 진행된다. 하지만, Language model이나 Machine Translation에는 유용하지 않다. 앞서 배운 Transfer Learning처럼, A의 data는 많고 B의 data는 적을 때 더욱 효과적이다.
단어 임베딩은 Face encoding과 유사하다고 볼 수 있다.

이전 CNN 에서 봤던 face encoding 인데, 이미지를 128D vector로 변환해서 이미지들을 비교하게 된다.
한가지 차이점은 사진의 경우에는 처음보는 이미지더라도 encoding이 되지만, 단어 임베딩의 경우에는 입력으로 사용되는 단어가 정해져있기 때문에 UNK과 같은 알 수 없는 단어(voca에 존재하지 않는)가 포함된다. 즉, 정해진 단어만 학습한다는 의미이다.
Properties of word embeddings

word embedding 의 중요한 부분은 이것이 유추하는 문제에 큰 도움을 준다는 것이다. 이에 대한 예제를 통해서 특징을 살펴보자.
'남자(man)와 여자(woman)는 왕(king)과 ____과 같다'라는 유추 문제가 있을 때, 어떻게 예측할 수 있을까?
위 표와 같이 Man은 4차원 벡터로 표현되며, $ e_{5391} = e_{man} $으로 나타낼 수 있다. 그리고 woman의 embedding은 $ e_{woman} $으로 표현하며, king/queen도 동일하게 표현된다. (실제로는 50~1000 차원을 사용한다)
그리고 $ e_{man} - e_{woman} $ 과 $ e_{king} - e_{queen} $ 을 시행해보면 다음과 같은 흥미로운 결과를 얻을 수 있다.
$ e_{man} - e_{woman} = \begin{bmatrix} -2 \\ 0 \\ 0 \\ 0 \end{bmatrix} , e_{king} - e_{queen} = \begin{bmatrix} -2 \\ 0 \\ 0 \\ 0 \end{bmatrix} $
이 결과에 의해서 우리는 man과 woman의 관계가 king과 queen의 관계와 유사하다고 추론할 수 있다.
직관적으로 이해하기 위해서 아래 사진을 보자.

word embedding 은 약 300차원의 공간에서 표현될 것이고, 그 공간 안에서 각 단어들은 점으로 표현될 것이다.
그리고, man과 woman의 차이와 king과 queen의 차이 벡터는 매우 유사할 것이다. 위에서 나타난 벡터(화살표)는 성별의 차이를 나타내는 벡터를 의미한다. 주의해야할 점은 300차원 안에서 그려진 벡터이다.(2차원이 아님)
여기서 우리가 해야할 것은 'man -> woman as king -> _____' 에서 우리는 빈칸의 단어 w를 찾는 것이고, 아래 방정식으로 찾을 수 있다.
Find word $ w : arg \max\limits_{w} sim(e_{w}, e_{king} - e_{man} + e_{woman}) $
여기서 sim은 similarity function을 의미하며, 두 단어 사이의 유사성을 계산한다. 위 식에서 유사성을 최대화하는 단어를 찾게 되고, 따라서 queen이라는 단어라고 예측할 수 있을 것이다.(적절한 similarity function이 필요하다)
실제 논문에서는 30~75%의 정확성을 보여주고 있는데, 유추 문제에서 완전히 정확한 단어를 추론했을 경우에만 정답으로 인정하기 때문이다.

그리고 t-SNE 알고리즘에 대해서 언급하자면, 이 알고리즘은 300D 를 2D 로 mapping 하는데, 매우 복잡하고 비선형적인 mapping 이다. 따라서, embedding 을 통해서 단어 간의 관계를 추론할 때, t-SNE 를 통해 mapping 된 embedding 값으로 비교하면 안되고, 300D 의 vector를 통해서 비교 연산을 수행해야 한다.

일반적으로 Similarity function으로는 Cosing similarity를 가장 많이 사용한다.
또한 아래와 같이 유클리디안 거리를 사용하기도 한다.
$ sim(u,v) = || u-v || ^{2}$
Embedding matrix

word embedding 을 통해서 학습되는 것은 Embedding Matrix이다. 만약 1만개의 단어를 사용하고 특징으로 300 차원을 사용한다면 위와 같은 (300, 10k)의 차원의 matrix E를 가지게 된다. 그리고 voca에 담겨있는 10000개의 단어들을 각각 다르게 임베딩한다. 예를 들어, orange는 6257 column에 있으며, 이 열은 orange에 해당하는 임베딩 vector가 된다. 그리고 one-hot encoding을 통한 $ O_{6257}$을 matrix E와 dot product를 수행하면 우리가 원하는 6257 column의 orange의 임베딩 vector를 얻을 수 있다. => $ E \cdot O_{6257} = e_{6257}$
일반화하면 다음과 같다.
Embedding for word j =$ E \cdot O_{j} = e_{j} $
우리가 학습해야되는 것이 Embedding Matrix E라는 것이 가장 중요하며, 이 Matrix E는 초기에 무작위로 초기화된다.
하지만 위 공식에서 Matrix E를 one-hot vector o와 함께 곱하는 것으로 표현되어있는데, 이것은 꽤 비효율적이다. one-hot vector는 꽤 높은 차원인데, 대부분 0으로 채워져있기 때문에 메모리 낭비가 심하고, 연산량도 많다.
실제로는 one-hot vector를 곱하는 것이 아닌 특화된 함수를 사용한다.
Leaning word embeddings
word embedding 의 deep learning 연구에서 초반에는 비교적 복잡한 알고리즘으로 시작했다. 그리고 시간이 지나면서, 훨씬 더 간단하고 단순한 알고리즘도 가능하고, 특히 큰 dataset 에서 매우 좋은 결과를 얻을 수 있다는 것을 발견하게 되었다. 최근 가장 인기있는 몇몇 알고리즘들은 너무 단순해서 마치 마법처럼 보일 수 있을 정도이다.
word embedding 이 어떻게 동작하는지 직관적으로 이해하기 위해서 더 복잡한 알고리즘의 일부를 살펴보자.
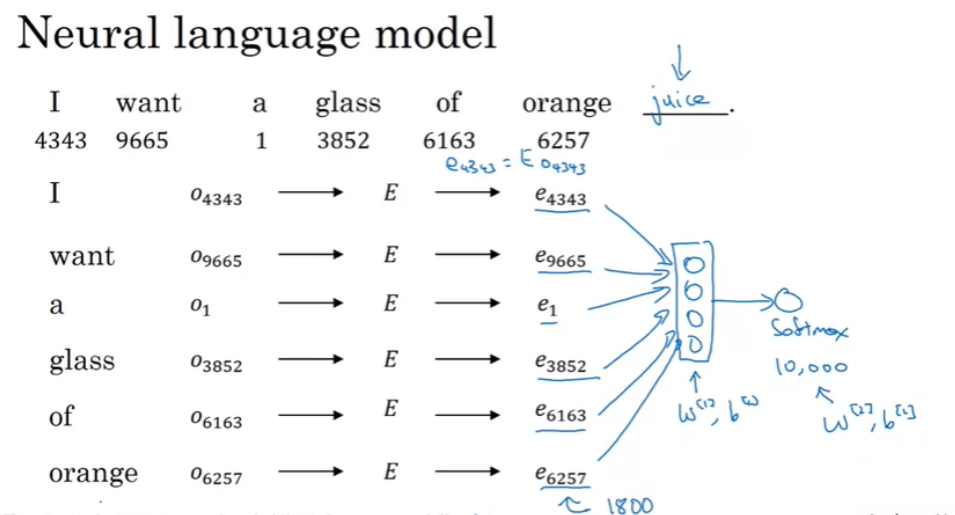
Language model을 만들고, I want a glass of orange _______. 에서 orange 다음의 단어를 예측하려고 한다.
주어진 단어들은 위와 같은 index를 가지도록 했다.
Neural language model은 embedding을 학습할 수 있는 방법이라고 밝혀졌다. 그리고 신경망 모델을 만들어서 연속적인 단어들을 통해서 다음 단어를 예측할 수 있는데, 첫번째 단어부터 시작해보자.
첫번째 단어 I의 one-hot vector $ O_{4343} $이 있고, Matrix E를 통해서 vector $ e_{4343} $ 을 얻을 수 있다. 다른 모든 단어도 동일하게 Matrix E를 통해서 vector를 얻을 수 있다. Matrix E를 통해서 얻은 vector들은 모두 300차원 vector이고, 이것을 신경망의 입력으로 사용하고 그 output은 softmax를 통해서 voca의 확률들로 변환된다.
신경망과 softmax layer는 각각의 weight와 bias 파라미터가 있고, 각 단어들은 300차원의 vector이므로 입력은 총 1800차원의 벡터가 된다.
일반적으로 fixed historical window를 사용하는데, 예를 들어, 다음 단어를 예측하는데 그 단어 앞의 4개의 단어만 사용하는 것이다. 따라서, 긴 문장이나 짧은 문장이나 항상 바로 앞의 4개의 단어만 살펴보는 것이다. 이것은 입력으로 1200차원의 vector를 사용해서 softmax output으로 예측하는 것을 의미한다.
여기서 4개의 단어 사용은 하이퍼 파라미터로 설정할 수 있고, 이렇게 고정된 범위의 단어를 사용한다는 것은 입력의 크기가 항상 고정되어 있기 때문에 임의의 긴 문장들을 다룰 수 있다.
따라서, 이 모델의 파라미터는 Matrix E와 $ W^{[1]}, b^{[1]}, W^{[2]}, b^{[2]} $가 되며, Matrix E는 모든 단어에 동일하게 사용된다. 이 알고리즘은 꽤 괜찮은 word embedding 을 학습하게 되고, 만약 orange가 아닌 apple이나 durian이 오더라도 유사한 단어라면 juice를 예측할 수 있게 되는 것이다.
중요한 것은 Matrix E를 학습한다는 것이고, 이제 이 알고리즘을 일반화해서 어떻게 더 단순한 알고리즘을 도출할 수 있는지 살펴보자.

좀 더 복잡한 문장 I want a glass of orange juice to go along with my cereal 이 있고, juice를 예측한다고 할 때, target은 juice가 된다. 그리고 앞서 살펴봤듯이 language model을 구성할 때, 입력으로 바로 앞의 4개의 단어를 선택했는데, 왼쪽과 오른쪽 4개의 단어를 선택할 수도 있고, 다른 Context를 선택할 수도 있다.
조금 더 단순하게 사용한다면 마지막 한 단어만 선택할 수도 있고, 가장 가까운 단어 하나를 사용할 수도 있다.
다음 영상에서 더 간단한 Context와 더 간단한 알고리즘을 통해서 어떻게 target word를 예측하게 되는지, 어떻게 좋은 단어 임베딩을 학습할 수 있는지 살펴보자.
Word2Vec
Word2Vec는 단어를 벡터로 바꾸어주는 알고리즘이고, 그 방법중의 하나인 Skip gram에 대해 알아보자.

Skip gram은 중심이 되는 단어를 무작위로 선택하고 주변 단어를 예측하는 방법으로, 중심 단어가 Context(입력) 되고 주변 단어를 선택해서 Target(prediction)이 되도록 하는 superivsed learning이다. (주변 단어는 여러개를 선택할 수 있다)
다음으로 Skip gram의 모델이다.

1만개의 voca가 있고, 이 단어들을 통해서 Context c에서 Target t를 매핑하는 모델을 학습해야 한다.
입력과 결과의 예를 들면, orange와 juice가 될 수 있다.
이전 강의에서 본 것처럼, 단어들의 one-hot vector와 Embedding Matrix E를 통해서 Embedding vector를 구할 수 있다. 그리고 이렇게 구한 Embedding vector를 입력으로 softmax layer를 통과해서 output $ \hat{y} $를 구할 수 있다.
softmax output을 자세하게 나타내면 아래와 같이 나타낼 수 있다.
여기서 $ \theta_{t} $는 output과 관련된 weight parameter고, bias는 생략했다.
Loss는 negative log likelihood를 사용해서 아래와 같이 구할 수 있다.
$ L(\hat{y}, y) = -\Sigma_{i=1}^{10,000}y_{i}log\hat{y_{i}}$
output $\hat{y} $는 1만 차원을 가지고, 가능한 1만개의 단어의 확률들을 포함한다.

하지만, 이 skip gram model 에는 몇 가지 문제가 있는데, 주된 문제는 바로 계산 속도이다. 특히 softmax model의 경우에 확률을 계산할 때 1만개의 단어를 계산해야한다. ( $ p(t|c) $의 분모항) 만약 10만개, 또는 100만개의 단어를 사용한다면 매번 분모를 합산하는 것은 매우 느리다. 이에 대한 몇 가지 해결 방법이 존재하는데, 그 중 한가지가 hierarchical softmax를 사용하는 것이다.
이 방법은 Tree를 사용하는 것인데, 자주 사용되는 단어일수록 Tree의 Top에 위치하고, 그렇지 않다면 Bottom에 위치하게 된다. 따라서 어느 한 단어를 찾을 때, Tree를 찾아 내려가기 때문에 선형 크기가 아닌 voca 사이즈의 log 사이즈로 탐색하게 되어 softmax보다 빠르다. 자세한 내용은 논문을 참조하면 된다.
Word2Vec의 또 다른 방법은 Negative Sampling인데, 이것에 대해 설명하기 전에 어떻게 Context c를 샘플링하는 지에 대해서 이야기를 해보자. Context c를 샘플링하면, Target t를 context의 앞뒤 10단어 내에서 샘플링할 수 있다. 여기서 context c를 선택하는 한가지 방법은 무작위로 균일하게 샘플링하는 것이다. 하지만, 이렇게 무작위로 하게 된다면 the, of, a, to 등이 아주 빈번하게 샘플링된다. 따라서 샘플링할 때에는 빈번한 단어들과 그렇지 않은 단어들간의 균형을 맞추기 위해서 다른 방법을 사용해야 한다.
Negative Sampling
지금까지 Skip gram 모델을 살펴보았는데, skip gram 모델은 softmax 연산이 너무 느린 문제점이 있었다.
다음으로 skip gram과 유사한 Negative Sampling이라는 알고리즘에 대해서 살펴볼 것인데, 이것이 skip gram보다 조금 더 효율적이다.
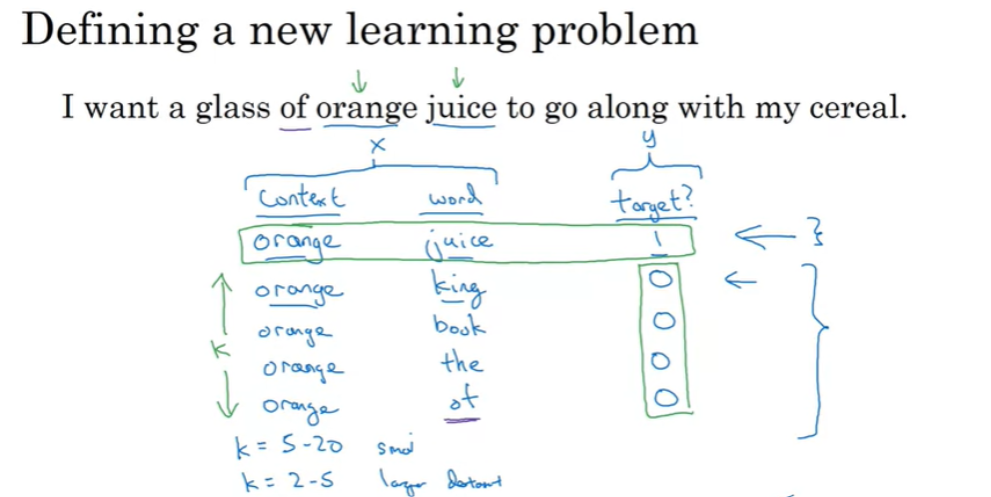
Negative sampling은 새로운 학습 문제를 정의한다. 예를 들어서 문제로 orange-juice와 같은 positive training set이 있다면, 무작위로 negative training set을 K개를 샘플링한다. 이때, 무작위로 negative 단어를 선택할 때에는 voca에 존재하는 단어 중에서 무작위로 선택하면 된다.
하지만, 우연히 'of' 라는 단어를 선택할 수도 있는데, 이는 context에 존재하는 단어이므로 실제로는 positive이지만, 일단 negative라고 취급한다.
negative sampling은 이렇게 training set을 생성하게 된다.
이 방법을 사용할 때에 작은 data set 의 경우에는 K를 5~20 의 값으로 추천하고, 큰 데이터 셋을 가지고 있다면 K를 더 작은 값인 2~5의 값으로 추천한다. 위에서는 K=4로 설정했다.
다음은 x->y mappling model이다.

앞서 본 softmax model 이 있고, 이전에 선택한 training set 가 있다. 즉 context와 word 가 input x가 되고, positive와 negative는 output y가 된다. 그래서 우리는 logistic regression model로 정의할 수 있게 된다.
이렇게 하면 1만 차원의 softmax가 아닌 1만 차원의 이진분류 문제가 되어서 계산량이 훨씬 줄어들게 된다.
그리고 모든 iteration 과정에서 한개의 positive와 K개의 negative 샘플만 학습하고 있다.
이 알고리즘에서 가장 중요한 점은 어떻게 negative sample을 선택하느냐인데, 한 가지 할 수 있는 방법은 corpus 에서의 empirical frequency 에 따라서 샘플링하는 것이다. 그래서 얼마나 자주 다른 단어들이 나타나는 지에 따라서 샘플링할 수 있다. 문제는 the, a, of, to와 같은 단어들이 자주 나타날 수 있다는 것이다.
또 다른 극단적인 방법은 $ 1 \over voca size $ 를 사용해서 무작위로 샘플링하는 것이다. 이 방법은 영어 단어의 분포를 생각하지 않는다. 논문의 저자는 경험적으로 가장 좋은 방법을 직접 찾아서 사용하는 것이 좋다고 한다. 논문에서는 단어 빈도의 3/4제곱에 비례하는 샘플링을 진행했다.
$ P(w_{i}) = {f(w_{i})^{3/4} \over \Sigma_{j=1}^{10,000} f(w_{j})^{3/4}} $
GloVe word vectors
word embedding 의 또 다른 알고리즘은 GloVe 알고리즘이다. Word2Vec or skip gram model 만큼 사용되지는 않지만, 꽤 단순하기 때문에 사용된다.
GloVe는 gloval vectors for word representation 을 의미한다.

GloVe 알고리즘은 corpus 에서 context 와 target 단어들에 대해서 i의 context에서 j가 몇 번 나타내는지($ X_{ij} $) 구하는 작업을 한다. 즉, 서로 가까운 단어를 캡처하며, context와 target의 범위를 어떻게 지정하느냐에 따라서 $ X_{ij} == X_{ji} $ 가 될 수도 있고, 아닐 수도 있다.

GloVe 모델이 하는 것은 아래 식을 최적화하는 것이다.
$ minimize \Sigma_{i=1}^{10,000}\Sigma_{j=1}^{10,000} f(X_{ij})(\Theta_{i}^{T}e_{j} + b_{i} + b'_{j} - logX_{ij})^{2} $
위 식에서 $ f(X_{ij}) $ 를 설정하는데, 이는 weighting term 이고, 이것이 하는 일은 한번도 등장하지 않은 경우에는 0으로 설정해서 더하지 않게 해주고, 지나치게 빈도가 높거나 낮은 단어로 인해서 $ X_{ij} $ 값이 특정값 이상으로 튀는 것을 방지하는 역할을 한다.
마지막으로 이 알고리즘에서 흥미로운 점은 $ \theta_{i} $ 와 $ e_{j} $ 가 완전히 대칭적이라는 것이다.
Sentiment classification
Sentiment classification(감성 분류)는 NLP에서 중요한 구성요소 중의 하나이다. 감성 분류에서 중요한 점은 많은 dataset이 아니더라도 word embedding 을 사용해서 좋은 성능의 분류기를 만들 수 있다는 것이다.

Sentiment classification problem은 위와 같은 매핑 문제이다.
간단한 모델은 아래와 같이 구성할 수 있다.

' The dessert is excellent ' 라는 입력이 있을 때, 각 단어들을 임베딩 vector (300D) 로 변환하고 각 단어의 벡터의 값들의 평균을 구해서 softmax output으로 결과를 예측하는 모델을 만들 수 있다.
여기서 word embedding 을 사용했기 때문에, 작은 dataset이나 자주 사용되지 않는 단어(심지어 학습에 사용되지 않는 단어)가 입력으로 들어오더라도 해당 모델에 적용이 가능하다.
하지만 위 모델은 단어의 순서를 무시하고 단순 나열된 형태로 입력하기 때문에 별로 좋은 모델은 아니다.
예를 들어 'Completely lacking in good taste, good service, and good ambience'라는 리뷰가 있다면, good이라는 단어가 많이 나왔기 때문에 positive로 예측할 수도 있다는 것이다.
그래서 해당 문제점을 해결하기 위해서 RNN을 사용할 수 있다.
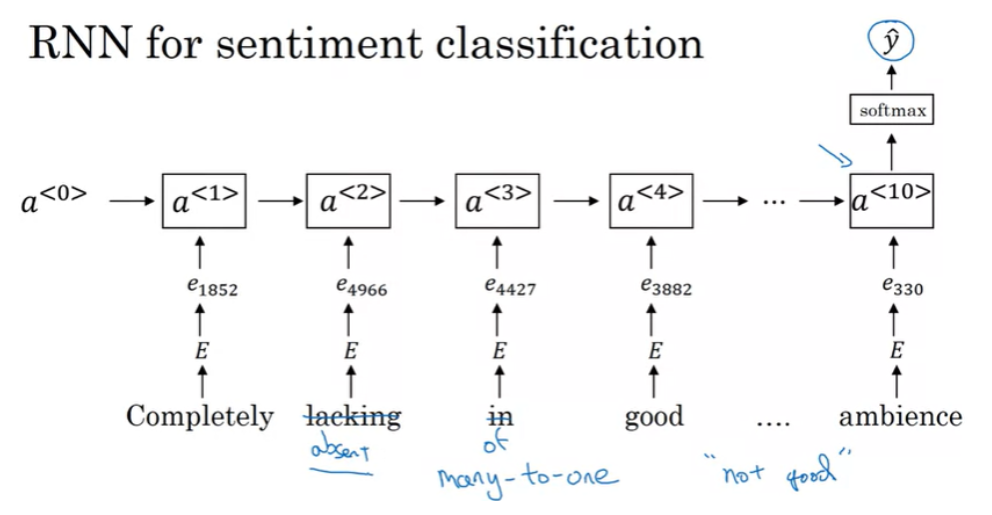
방금 예시처럼 부정의 리뷰를 입력으로 사용하더라도 시퀀스의 순서를 고려하기 때문에 해당 리뷰가 부정적이라는 것을 알 수 있게 된다. 따라서 이 모델로 학습하면 상당히 괜찮은 분류기가 된다. 또한 absent 라는 단어가 training set 에 존재하지 않았더라도 word embedding 에 포함이 된다면, 일반화되어서 제대로 된 결과를 얻을 수 있다.
Debiasing word embeddings
Machine Learning과 AI 알고리즘은 매우 중요한 결정을 하는데 도움이 되거나, 많은 도움을 줄 수 있다고 신뢰받고 있다. 그래서 우리는 bias(편견)에서 자유롭다는 것을 확인하고 싶어한다.(예를 들어, 성이나 인종에 대한 편견을 가지지 않는 알고리즘이기를 원한다.)
word embedding 에서 이러한 편견들이 있을때, 어떻게 이런 편견들을 제거하거나 감소시키는 방법에 대해서 알아보도록 하자.

word embedding 에서 성별이나 나이, 인종 등의 편견을 반영하기 때문에 이것을 없애는 것은 매우 중요하다. (많은 결정에서 AI가 사용되므로)
word embedding 에서 편견은 다음과 같은 과정을 거쳐서 제거할 수 있다.
1. 먼저 bias의 direction을 구한다.

만약 성별의 direction을 구한다면, $ e_{he} - e_{she}, e_{male} - e_{female} $등의 성별을 나타낼 수 있는 단어들의 차이를 구해서 구할 수 있는데, 남성성의 단어와 여성성의 단어의 차이를 구해서 평균으로 그 방향을 결정할 수 있다.
(실제로는 더 복잡한 SVD-특이값분해라는 알고리즘을 통해서 bias direction을 구한다)
그리고 이것은 1D의 bias direction과 나머지 299D의 non-bias direction으로 나눌 수 있다.
2. 다음으로는 Neutralize(중성화) 작업을 수행한다.

bias가 없어야 하는 단어들에 대해서 bias 요소를 제거해야하는데, project를 통해서 각 단어 벡터의 bias direction 요소를 제거한다. doctor나 babysitter등의 단어의 성별 bias를 제거하는 것이다.
3. 마지막으로 Equalize pairs 작업을 수행한다.
즉, boy-girl / grandfather-grandmother과 같은 단어는 각 단어가 성별 요소가 있기 때문에, 이러한 단어들이 bias direction을 기준으로 같은 거리에 있도록 한다. 즉, 각 성별 요소가 있는 단어들은 bias direction과의 거리의 차이가 동일하도록 만들어주는 것이다.
전체 알고리즘은 조금 더 복잡한데, 논문에서 자세하게 설명하고 있으니 궁금하면 찾아보기를 권한다.
'연구실 > 인공지능(Coursera)' 카테고리의 다른 글
| [AI 15주차] Transformer Network (0) | 2024.08.19 |
|---|---|
| [AI 14주차] Sequence models & Attention Mechanism (0) | 2024.08.19 |
| [AI 12주차] Sequence Model : 순환 신경망(RNN) (1) | 2024.08.16 |
| [AI 11주차] Face Recognition (얼굴 인식) & Neural Style Transfer(신경 스타일 전송) (1) | 2024.08.10 |
| [AI 10주차] Object Detection (1) | 2024.08.09 |



