Face Recognition

얼굴 인식 분야에서 세부적으로 얼굴 검증(Verification)과 인식(Recognition)으로 분류된다.
Face Verification의 경우에는 사람의 이름이나 ID, 이미지가 주어졌을 때, 이 사람이 맞는가에 대한 여부를 확인한다. 1:1 문제라고도 부르고, 요청한 그 사람이 맞는지 여부를 알게 한다.
예를 들어 사용자가 자신의 스마트폰을 잠금 해제하려고 할 때, 스마트폰은 카메라를 통해 현재 촬영된 얼굴 이미지를 이전에 등록된 얼굴 이미지와 비교한다. 만약 두 이미지가 동일한 인물이라고 시스템이 판단하면, 잠금이 해제된다. 이 경우, 시스템은 두 개의 얼굴 이미지가 같은 사람인지를 검증(verification)하는 것이다. 이 기능은 일반적으로 1:1 비교를 수행하며, 등록된 한 사람의 얼굴과 현재 인식된 얼굴이 동일한지 여부를 확인한다.
반면에 Face Recognition의 경우에는 1:K 문제라고도 하는데, K 명의 database가 있으면 주어진 이미지를 통해서 K명의 database에 속하는 사람인 지를 판단해야 한다. 공항에서 자동 출입국 심사대를 이용할 때, 시스템은 사용자의 얼굴을 촬영하고, 이를 데이터베이스에 저장된 수많은 사람들의 얼굴 중 하나와 비교하여 사용자를 식별한다. 이 경우, 시스템은 현재 인식된 얼굴을 데이터베이스에 있는 여러 얼굴들 중 하나와 매칭하여 해당 인물이 누구인지를 확인하는 작업을 수행한다. 이는 1비교로, 한 사람의 얼굴을 여러 사람의 얼굴 데이터와 비교하여 일치하는 사람을 찾는 것이 목표이다.
얼굴 인식은 얼굴 검증 문제보다 훨씬 어려운데, 99%의 정확성을 갖춘 인식 시스템일지라도 데이터베이스에 100명이 있다면 오차가 생길 확률은 100명 중에 한명꼴로 발생한다. 따라서 허용 가능한 오류를 원한다면 실제로 99.9%이상의 정확성을 갖추어야 할 수 있다.
One Shot Learning
얼굴 인식에서의 도전 중에 하나는 One Shot Learning 문제를 해결해야 한다는 것이다. 대부분 얼굴인식 application에서 한 사람을 인식하는데, 하나의 이미지만 주어진다는 것이다. 전통적으로, 딥러닝 알고리즘은 one training example을 가지고 있다면 성능이 좋지 않았다.
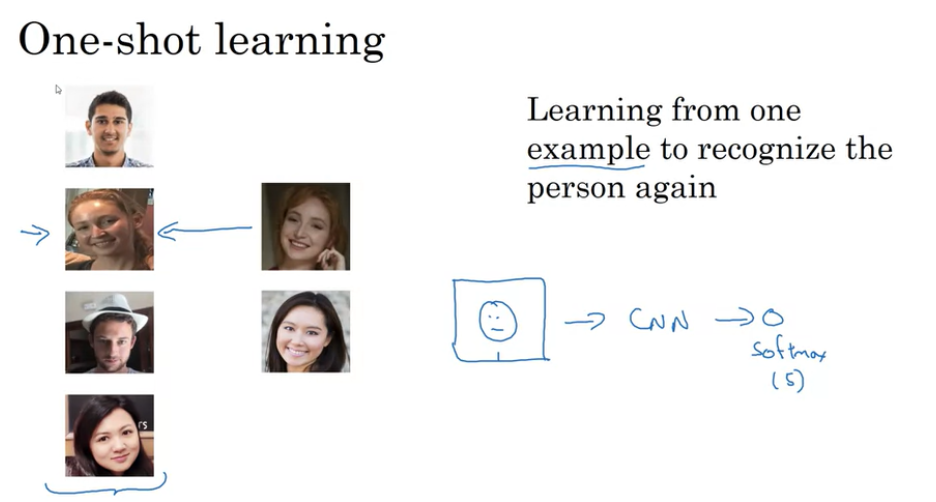
위의 예시를 살펴보자. 4명의 등록된 직원이 있고, 사무실 누군가가 게이트를 지난다고 가정해보자. 게이트의 시스템은 각 직원의 사진 하나씩만을 가지고, 게이트를 지나는 사람이 직원인지 아닌지 인식해야 한다. 따라서 One Shot Learning 문제에서는 한 가지 example만을 통해서 그 사람을 다시 인식해야한다. (대부분의 얼굴 인식 시스템에 필요한 성능이다)
그래서 시도해볼 수 있는 방법 중의 하나는 직원 데이터베이스의 이미지를 ConvNet의 입력으로 사용해서 Output Y 레이블을 출력하게 한다. 직원이 4명이기 때문에 인식하지 못하는 경우까지 총 5개의 label의 가진 softmax unit output이 된다.
하지만, 이 방법은 실제로는 잘 동작하지 않는다. 이렇게 작은 training set으로는 deep neural network를 훈련시키기에 충분하지 않기 때문이다.
그리고 새로운 직원이 추가된다면 어떻게 될까? 5개의 output에서 6개의 output으로 바뀌어야하고, ConvNet을 다시 학습시켜야 할까? 이 방법은 좋은 방법이 아니다.
따라서, 얼굴 인식에서 one shot learning을 수행하기 위해서 할 수 있는 방법은 similarity funcion을 학습하는 것이다.

즉, 두 이미지의 차이 정도를 output으로 출력하는 similarity function를 학습하는데, 이미지가 많이 다르면 값이 크고, 유사하다면 값이 작다. 그래서 어느 정도 이상 크다면 같은 사람으로 인식하고, 작다면 다른 사람으로 인식한다. 따라서 새로운 이미지가 주어진다면, similarity 함수를 사용해서 두 이미지를 비교한다. 여기서 기준이 되는 임계값(threshold)은 Tau 이며, 이는 hyperparameter 이다.
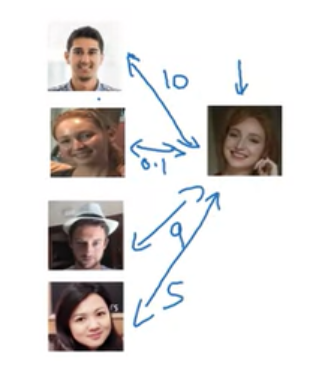
위의 경우에는 왼쪽 두번째 이미지와의 similarity 함수 값이 가장 작기 때문에 같다라고 판단한다. 이렇게 similarity 함수를 통해서 새로운 사람이 추가되어도 재학습할 필요없이 잘 동작할 수 있게 된다.
Siamese network
위에서 배웠던 d함수는 두 얼굴 이미지를 입력하고, 두 이미지가 얼마나 유사한지, 얼마나 다른지 알려준다. 이것을 수행하기 좋은 방법은 Siamese network를 사용하는 것이다.

위의 ConvNet에서 x^(1라는 이미지를 입력하면 일련의 convolution, pooling, fc를 통해서 feature vector로 마무리되고, softmax unit으로 분류를 하는 것에 익숙한데, 여기서는 출력단은 제거하고 feature vector에 초점을 맞출 것이다. 이 feature vector는 fc에 의해서 계산된 값이다. 이 feature vector의 이름을 f(x(1))이라고 부르고, 이 함수는 x^(1) 의 input 이미지를 encoding하는 것이라고 생각하면 된다. 즉, input 이미지를 취해서 128개의 feature vector로 encoding하는 것이다.
이를 이용해서 얼굴 인식 시스템으로 구축할 수 있는 방법은 두 장의 사진을 동일한 파라미터를 가진 신경망을 통해서 이 128개의 feature vector를 각각 얻어서 비교한다.

따라서 두 이미지 x^(1),x^(2) 를 신경망을 통해서 인코딩된 f^(1),f^(2)를 얻을 수 있다. 이렇게 인코딩된 값이 두 이미지를 잘 나타낸다고 생각한다면, x^(1) 과 x^(2) 사이의 거리 d를 구할 수 있는데, 거리 d는 두 이미지의 인코딩된 값 차이의 norm으로 정의할 수 있다.

이렇게 두 개의 서로 다른 인풋을 동일한 ConvNet을 통해서 인코딩된 값을 얻어서 비교하는 개념을 Siamese Neural Network Architecture라고 부르기도 한다. 이 아이디어는 DeepFace 논문에서 비롯되었다.
정리하자면
- 신경망의 파라미터를 f(x^(i))의 인코딩으로 정의한다.
- 같은 두 사람의 이미지 x^(i), x^(j) 가 있다면, 이 인코딩 사이의 norm 을 최소화하는 것이다. 만약, 두 이미지가 다르다면, 인코딩 사이의 norm 이 커야 한다.
다음으로 d 함수를 학습하기 위해서 loss function 을 어떻게 정의해야 되는지 살펴보자.
Triplet loss
신경망의 파라미터를 학습해서 얼굴 인식을 위한 좋은 인코딩을 학습하는 방법은 triplet loss function을 적용한 GD를 정의하는 것이다.

Triplet Loss를 적용하려면, 이미지 쌍을 서로 비교해야한다. 위의 예시처럼 동시에 여러 이미지를 살펴봐야하는데, 왼쪽의 이미지 쌍은 같은 사람이기 때문에 인코딩이 유사해야되고, 오른쪽 이미지 쌍은 다른 사람이기 때문에 인코딩이 꽤 차이가 나야한다. 여기서 Triplet Loss는 하나의 Anchor 이미지를 두고, Positive와 Negative와의 사이의 거리를 동시에 살펴본다.
즉 Anchor-Positive의 인코딩과 Anchor-Negative의 인코딩 차이를 같이 살펴본다는 것이다. (Anchor는 A, Positive는 P, Negative는 N으로 축약한다.)
위 내용을 공식으로 나타내면 다음과 같다.

A와 P는 같은 사람이기 때문에 d(A, P)가 작고, A와 N은 다른 사람이기 때문에 d(A, N)이 크다. 따라서 d(A, P)가 d(A, N)보다 작도록 하는 것이 목표이다. 하지만 주의해야할 점이 있는데 모든 이미지의 인코딩이 같아지면 안된다. 모든 이미지의 인코딩이 같아진다면, d(A, P)와 d(A, N)이 모두 0이 되어서 위 공식을 항상 만족하게 된다.
위와 같은 상황을 방지하기 위해서 라는 하이퍼 파라미터를 추가하는데, margin이라고 부르기도 한다.

margin의 역할은 다음과 같다.

d(A, P) = 0.5 이고 d(A, N) = 0.51 이라면, margin이 없을 때에는 공식이 만족하게 된다(다른 사람임에도 불구하고 d(A,N)이 더크다). 하지만, α=0.2가 존재한다면, d(A, N)이 0.7이 되거나 d(A, P)가 0.31이 되는 식으로 학습을 가능하도록 만들어 준다. 즉, A-P와 A-N이 서로 더 멀어질 수 있도록 하는 역할을 한다.
Triplet Loss Function을 정의하면 다음과 같다.

0보다 작다면, 같은 사람이라고 판단하고 0으로 설정한다.
Cost는 아래와 같이 정의된다.
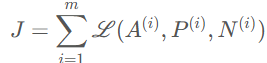
training set으로는 1,000명의 사람들의 사진 10,000장으로 위와 같이 triplet을 생성하고 GD를 사용해서 학습시키면 된다. 한 사람당 평균 10장의 사진을 가지고 데이터를 구성하는데, 각 사람의 사진이 하나뿐이라면 이 시스템을 실제로 훈련할 수는 없다.
물론, 학습이 완료된 후에는 얼굴 인식 시스템을 위한 One Shot Learning에 적용할 수는 있다. 하지만, 학습할 때 training set에서는 Anchor / Positive의 쌍을 이룰 수 있도록 몇몇 사람들만이라도 동일한 사람의 이미지가 여러 개가 있는지 확인하는 것이 필요하다.
그리고, A-P는 같은 사람이고 A-N은 다른 사람이기 때문에 무작위로 고를 때, A-N의 데이터가 매우 많이 뽑힐 확률이 높다. 따라서 training set를 구성할 때는 훈련하기 어려운 A,P,N 중의 하나를 선택하는 것이 중요하다.

같은 사람이지만 d(A,P) 값은 낮고, 다른 사람이지만 d(A,N)의 값이 높은 set로 구성을 한다면 학습에 더욱 도움이 될 것이다.
정리하면,
- Triplet Loss 를 가지고 학습을 하기 위해서는 training set에서 A-P와 A-N 의 쌍을 mapping 해야 한다
- 이 training set을 가지고 Cost J를 minimize 하기 위해 GD를 사용한다.
- 학습은 같은 사람일 경우에는 d가 최소가 되고, 다른 사람일 경우에 d 가 최대가 되도록 최적화된다.
Face Verification and Binary Classification
Triplet Loss는 얼굴 인식을 위한 ConvNet의 파라미터 학습에 좋은 방법 중의 하나이다. 또 다른 방법으로는 얼굴 인식을 Binary Classification 문제로 변형해서 사용할 수 있는데, 한 번 살펴보도록 하자.
이미지를 128개의 feature vector로 나타내기 위해서 ConvNet을 통과시켜 embeding(encoding)시키고, 128개의 feature vector를 Logistic Regression을 통해서 예측하도록 한다. 목표 output은 두 이미지가 같다면 1을 출력하고, 다른 사람이라면 0이 된다. 즉, 얼굴 인식을 Binary Classification 문제로 취급하는 것이다.
output y^는 sigmoid 함수이고, 인코딩된 값들 사이에서 차이점을 알아내서 예측한다.
공식으로 나타낸다면 다음과 같이 나타낼 수 있다.
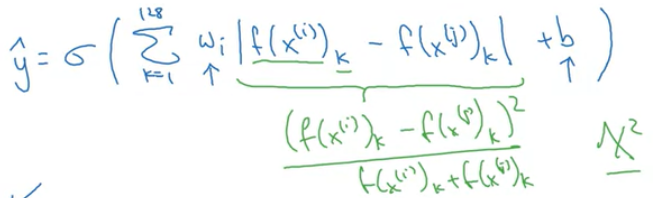
인코딩된 값의 차이를 구하는 수식에는 다양한 방법이 있으며, 초록색으로 표시한 것으로도 사용할 수 있다. 이는 카이 제곱 유사도라고 불린다.
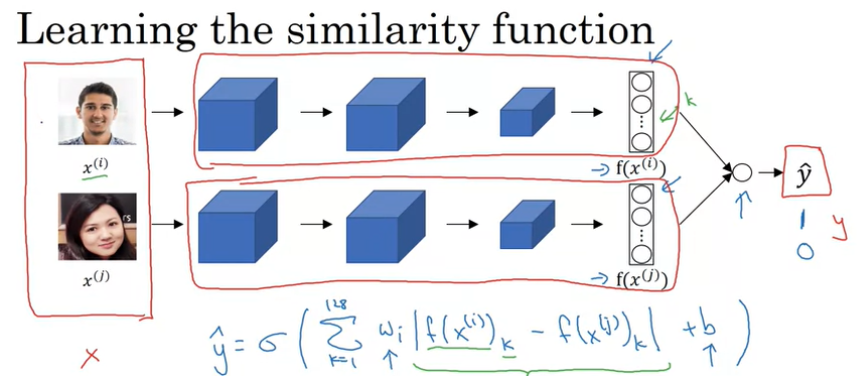
그리고, 이 방법을 사용할 경우에 유용한 방법이 하나 있는데, database에서 이미지가 입력으로 사용된다고 한다면, 매번 embeding을 다시 할 필요없이, embeding된 값을 저장해서 ConvNet을 통과시킬 필요없이 바로 예측에 사용할 수 있다.이 방법을 사용하면 이미지를 저장할 필요가 없고, 데이터베이스가 매우 큰 경우에도 매번 모든 사람의 인코딩을 계산할 필요가 없기 때문에 효율이 높아진다.
Neural Style Transfer
: Convnet으로 구현할 수 있는 흥미로운 어플리케이션 중의 하나이다. 이 네트워크를 통해서 자신만의 예술 작품을 만들 수 있다.

이미지를 새로운 Style로 변형하는 것인데, 원본 이미지(Content)와 변형할 스타일(Style)을 가지고 새로운 Style의 이미지(Generated Image)를 합성하는 것이다.
Neural Style Transfer를 구현하려면 ConvNet의 다양한 layer들을 살펴보고 그 layer들에 의해서 추출된 feature들을 살펴보아야 한다.
Neural Style Transfer에 대해서 알아보기 전에, Deep ConvNet이 무엇을 학습하는지에 대해서 이야기해보자.
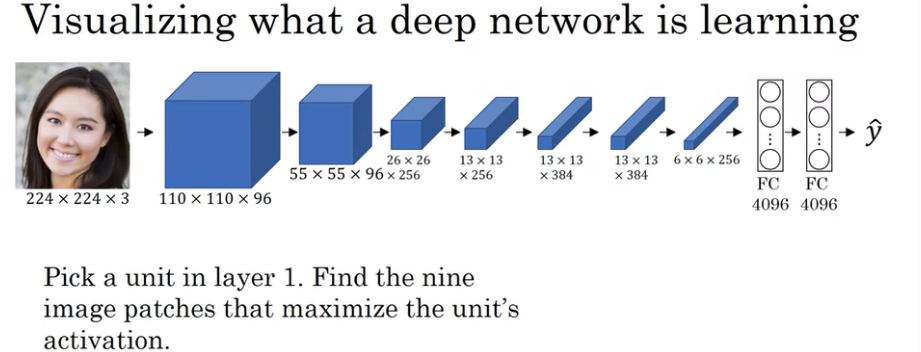
우리가 위와 같은 ConvNet을 학습할 때, 각 layer에서 추출하는 feature들의 시각화를 통해서 각 layer의 unit들을 최대로 활성화하는 특징이 무엇인지 파악할 수 있다. 그리고, shallow layer에서는 명암과 같은 단순한 feature를 출력하고, deep layer로 갈수록 더욱 복잡한 패턴을 감지하기 시작한다.

'Visualizing and understanding convolutional networks' 논문에 ConvNet layer를 시각화하는 정교한 방법에 대해서 설명하고 있다.
Cost function
Neural Style Transfer를 구현하기 위해서 생성된 이미지(Generated Image)에 대한 Cost Function을 정의해보자. 이 Cost Function을 최소화함으로써 우리는 원하는 이미지를 생성할 수 있게 된다.

cost function 은 아래와 같이 정의할 수 있다.
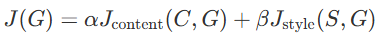
여기서 Jcontent(C,G)는 Content Cost라고 하며, Jstyle(S,G) 는 Style Cost라고 하며, 두 이미지가 얼마나 비슷한지에 대한 Cost이다. α,β 는 content cost와 style cost의 상대적인 가중치를 의미하고, 이것 또한 선택해야하는 hyperparameter 이다.(하나의 파라미터로 충분하지만, 논문에 따라 두개의 파라미터로 설명함)
그리고 최적화 알고리즘이 수행되는 방식은 다음과 같다.

처음에는 이미지 G를 무작위로 초기화해서 백색 노이즈의 이미지로 만들고, Cost Function을 통해 Gradient Descent를 수행해서 Cost Function을 최소화하고 G를 업데이트한다. 이 과정은 이미지 G의 픽셀 값을 업데이트하는 것이고, 학습이 진행될 수록 style로 렌더링된 content 이미지를 얻을 수 있을 것이다.
앞서 언급한 Content cost function 에 대해 알아보자.

만약 layer l을 사용해서 content cost를 계산한다고 했을 때, hidden layer 1을 선택한다면 생성된 이미지가 content image와 매우 비슷한 픽셀값을 가지도록 할 것이고, layer가 깊다면 content와 너무 동떨어진 이미지가 생성될 것이다. 따라서 layer l은 너무 얕지도, 깊지도 않은 layer로 선택해야 한다.
pre-trained ConvNet을 사용해서, content image와 generated image가 주어지면 이 두 이미지가 얼마나 유사한지 측정하면 된다. (ex : VGG network)
즉, a^[l](C) 와 a^[l](G) 를 구해서, 두 activation이 유사하다면 두 이미지가 비슷하다라는 것을 의미한다. 그래서 Content Cost는 다음과 같이 구할 수 있고, 우리는 이 Cost를 최소화하도록 최적화하면 된다.

다음으로, style cost function 에 대해 알아보자.

이미지의 style이 의미하는 것은 무엇일까? Style Image의 측정방법을 정의하기 위해서 우리고 한 layer L을 선택했다고 가정해보자. 그렇다면 우리는 channel들 사이에서 분포하는 activation들의 상관 관계로 style을 정의할 수 있다.
한 layer L을 통해서 nH, nW, nC=5 block이 output으로 나왔을 때, 각 channel들의 쌍을 서로 비교해서 어떤 상관관계를 가지고 있는지 확인하는 것이다.

따라서, 만약 빨간색 channel과 노란색 channel이 있을 때, 빨간색 채널은 수직 텍스쳐를 나타내고, 노란색 채널은 주황빛 계열의 색을 나타낸다고 하자. 만약 두 채널이 서로 상관관계가 높다면 수직 텍스쳐가 있을 때, 주황빛 계열을 가지게 된다는 뜻이고, 상관관계가 없다면 수직 텍스쳐가 있더라도 주황 계열이 아닐 수도 있다는 것이다.
이렇게 상관관계의 정도로 생성된 이미지(G) 와 Input Style 이미지(S) 의 유사한 정도를 측정할 수 있다.
위 아이디어를 공식으로 표현하면 다음과 같다.
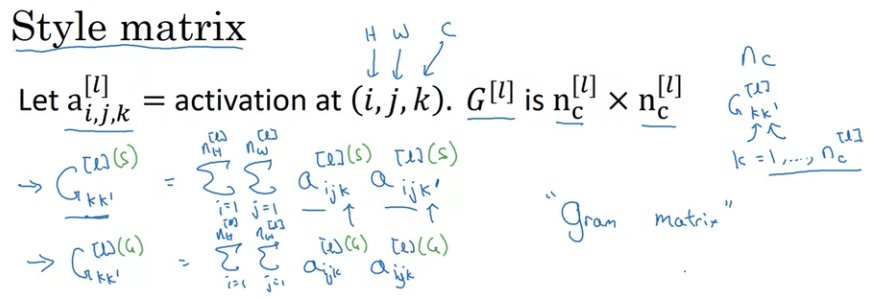
Style matrix로 모든 상관관계를 측정하는데, Style matrix는 위와 같이 계산된다. Gkk′[l] 는 k와 k′의 상관관계 정도를 의미하며 k는 1 ~ n_c[l]의 값이다. Gram matrix라고도 부른다. 이렇게 Style matrix를 정의하고, 이 행렬들을 사용해서 Style Cost function을 정의하면 아래와 같다.

여기서 λ(정규화 상수)는 Cost Function에서 β를 곱하기 때문에 중요하지 않다.
이렇게 하면, 꽤 잘 보이는 neural artistic 을 생성할 수 있고, 이를 통해 퀄리티가 꽤 좋은 artwork 를 성할 수 있다.
'연구실 > 인공지능(Coursera)' 카테고리의 다른 글
| [AI 13주차] Natural Language Processing & Word Embeddings (0) | 2024.08.18 |
|---|---|
| [AI 12주차] Sequence Model : 순환 신경망(RNN) (1) | 2024.08.16 |
| [AI 10주차] Object Detection (1) | 2024.08.09 |
| [AI 9주차] 심층 컨볼루션 모델(Deep convolution model) (0) | 2024.08.07 |
| [AI 8주차] Convolution Neural Network (CNN) 기초 (0) | 2024.08.05 |



