Hyperparameter Tuning
hyperparameter 를 어떻게 잘 설정할 수 있는지에 대해서 알아보자.
hyperparameter 를 잘 설정하기 위해서 어떻게 해야 잘 탐색할 수 있을까?
Don't use a grid
machine learning algorithm 초기 세대에는 grid로 point 들을 sampling 했다.
아래와 같이 hyperparameter가 2개가 있고, hyperparameter 1을 learning rate, hyperparameter 2를 epsilon 이라고 하자.

25개의 point 들이 있다. 근데, 여기서 epsilon은 값을 바꿔도 크게 달라지지 않아서 크게 중요하지 않지만, learning rate는 아주 중요하다. 값에 따라 결과가 많이 달라진다. 그런데, 위와 같이 grid 로 sampling을 하게 되면 중요한 learning rate 값에 대해서 training 하는 동안 5가지 밖에 try 를 하지 못한다.
Deep learning 에는 point 들을 random 하게 samling 한다. 이렇게 하는 이유는 어떤 hyperparameter가 특정 problem 에 대해서 중요한지 미리 알 수 없기 때문이다. 실제로 몇몇 hyperparameter 가 다른 hyperparameter 보다 더 중요하다.
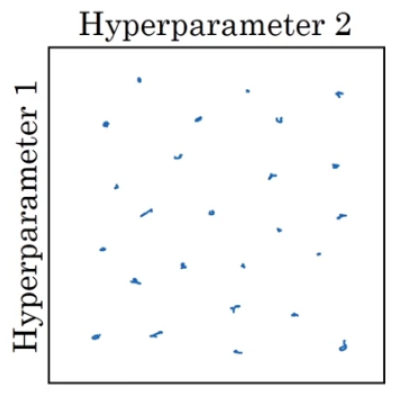
random 하게 sampling 을 하게 되면, 25가지의 learning rate 에 대해서 try 를 하게 되므로 잘 작동하는 값을 찾을 가능성이 높아진다. 그래서 random 하게 point 들을 sampling 해서 search를 해야 한다.
만약, hyperparameter가 3가지가 있다면 어떻게 될까?
아래와 같이 3차원의 cube 형태로 탐색을 하게 된다.

실제로, deep learning 에는 hyper parameter의 종류가 아주 많다. 3개 이상인 경우가 많다. 그래서, 어떤 hyperparameter가 중요한지 미리 알기는 어려워서 random 하게 sampling 해서 중요한 hyperparameter에 대해서 풍부하게 탐색을 할 수 있도록 해야 한다.
Coarse to fine
: deep learning 에서 사용되는 용어이다. 이는 각 hyperparameter 의 범위를 coarse(거친) 값으로 놓고, 그 중 가장 의미있는 값을 선택한 뒤 그 주변에서 fine(세밀한) 탐색을 해서 더 optimize하는 것을 의미한다.
2차원의 hyperparameter 예시들이 있다고 해보자. 실제로 training을 하면서 어떠한 point 들이 잘 동작하는지 알게 될 것이다. 이러한 point 들 주변에 다른 몇몇 point 들도 잘 동작하는 경향이 있다. 그래서, 이러한 point 들을 hyperparameter의 작은 region 으로 zoom in (grouping) 해서 이 region 에 대해서 더 세밀하게 탐색하는 것을 의미한다.

다시 말해서, 전체 사각형의 대략적인 sampling 을 한 후, 더 작은 사각형으로 더 조밀하게 sampling 할 수 있다.
Using an Appropriate Scale to pick hyperparameters
random 하게 sampling 한다는 것은 random하게 uniform 하게 sampling 하는 것을 의미하는 것이 아니다. hyperparameter들을 탐색할 적절한 scale 를 선택하는 것이 중요하다.

hidden units 의 개수를 선택하려고 한다고 할 때, 좋은 값의 범위가 50~ 100 이라고 해보자.이 때, 이러한 숫자들 내에서 linear scale로 random 하게 숫자 값을 선택할지도 모른다.
또한, nerual network 에서 layer의 개수를 결정한다고 할 때, 좋은 값의 범위가 2~4라고 해보자. random 하게 uniform 하게 sampling 해서 마찬가지로 linear scale로 2,3,4 가 합리적이라고 생각할 수 있다. 하지만, 이러한 방법이 모든 hyperparameter에 적용되는 것은 아니다.
hyperparameter learning rate(α)
0.0001이 낮은 경계선이고, 1 이 높은 경계선일 때, linear scale에서 uniform 하게 random sampling하면 0.1 에서 1사이에 값이 90% 있고, 나머지 10%만 0.0001과 0.1 사이에 있을 것이다. 이는 올바르지 않다.
이 경우에는 log scale 로 hyperparameter를 나누고 uniform 하게 random 탐색하는 것이 더 합리적이다.

0.0001 과 0.1 사이에 25%, 0.001과 0.001 사이에 25%, 0.01 과 0.1 사이에 25%, 0.1 과 1 사이에 25%가 된다.
이를 구현해보면 아래와 같다.
r = -4 * np.random.rand() # r ⊆ [-4, 0]
α = 10^r # α ⊆ [0.0001, 1]
일반화를 하면 아래와 같다.
r = a+ (b-a) * np.random.rand() # r ⊆ [a, b]
α = 10^r # α ⊆ [10^a, 10^b]
hyperparameter exponentially weighted moving averages(β)
0.9가 낮은 경계선이고 0.999가 높은 경계선일 때, 앞서 봤던 상황과 비슷하게 맞춰주기 위해서 1- β 로 생각해보자.

이를 log scale로 나눠서 random하게 sampling할 수 있다. 구현해보자.
r = -3 + 2 * np.random.rand() # r ⊆ [-3, -1]
1-β = 10^r # 1-β ⊆ [0.001, 0.1]
β = 1-10^r # β ⊆ [0.9, 0.999]
일반화 하면 아래와 같다.
r = a + (b-a) * np.random.rand() # r ⊆ [a, b]
β = 1-10^r # β ⊆ [1-10^b, 1-10^a]
그렇다면 이 경우에 linear scale로 sampling하는 것이 왜 합리적이지 않을까?
왜냐하면, β 가 1에 가까운 경우에 되게 예민하기 때문이다. 예를 들면, 0.9000 에서 0.9005 로의 변화는 미미하지만, 0.999 에서 0.9995로의 변화는 크다. 그래서 1에 가까운 region에 대해서는 더 densely 하게 sample 하도록 하기 위해서 log scale을 사용한다.
이제, hyperparameter 탐색 과정을 organize 하는 2가지 방식에 대해서 알아보자.
- Babysitting one model
: Data set은 매우 크지만, CPU와 GPU 자원과 같은 것들이 충분하지 않아서 보통 한 번에 하나의 model 만 training 시킬 수 있다. 이 경우, 해당 model이 train되는 동안에 계속해서 돌봐줄 수 있다.

예를 들어, 첫날(day 0) 에 parameter를 random하게 initialization 하고 training을 시작한다고 가정해보자. 그런 다음 하루 동안 cost function J가 점차 decrease하는 learning curve를 점진적으로 관찰한다. 첫째 날이 끝나면(day 1) J가 잘 학습되는 것 같으니 learning rate를 조금 increase 시켜볼 수 있다. 그리고 2일이 지나면(day 2) 여전히 잘 진행되고 있으니 momentum 항을 조금 조정하거나 learning 변수를 조금 줄여볼 수 있다. 그렇게 해서 이제 day 3에서 매일매일 parameter를 조정해보면서 learning을 지속적으로 관찰한다. 만약에 어느날 learning rate가 너무 높다는 것을 발견하면 이전 날의 model로 돌아갈 수도 있다. 이렇게 매일 learning curve를 보면서 parameter를 조금씩 조정해 나간다. 이러한 방식이 babysitting one model이고, 동시에 여러 model을 training 시킬 충분한 resource가 되지 않는 경우에 사용하는 방식이다. 이처럼 하나의 모델을 세심하게 돌보는 것을 panda 전략이라고 하는데, 판다가 새끼를 낳을 때, 보통 한 번에 한 마리의 새끼만 낳고 그 새끼 판다가 생존할 수 있도록 많은 노력을 기울이기 때문이다.
2. Training many models in parallel
: 이 방법에서는 특정 hyperparameter 설정을 가진 model을 하나 실행하고, 하루나 며칠 동안 자동으로 learning을 진행하게 한다. 그러면 어떤 learning curve가 생성된다. 동시에 다른 hyperparameter 설정을 가진 두 번째 model 을 시작할 수 있다. 이 두 번 째 model 은 다른 learning curve 을 생성할 것이다. 동시에 세 번째 model 을 training 할 수 있다. 그리고 또 다른 model을 training하는데, 이는 수렴하지 않을 수도 있다. 이렇게 여러 model을 parallel 하게 training 하는 것이다. 이 방법을 통해 다양한 hyperparameter 설정을 시도할 수 있으며, 여러 model 의 결과를 비교하여 가장 잘 작동하는 model 을 빠르게 선택할 수 있다.

parallel하게 여러 model을 훈련하는 것을 cavier 전략이라고 하는데, 물고기가 번식하는 과정은 하나에 많은 집중을 쏟기보다 하나 또는 그 이상이 더 잘 살아남기를 그지 지켜보기 때문이다.
Batch Normalization
batch normalization 은 hyperparameter 탐색을 더 쉽게 해주고, neural network를 더 robust 하게 만들어준다. 또한, 모든 매우 깊은 신경망을 train 하는 것을 더 쉽게 만들어준다.
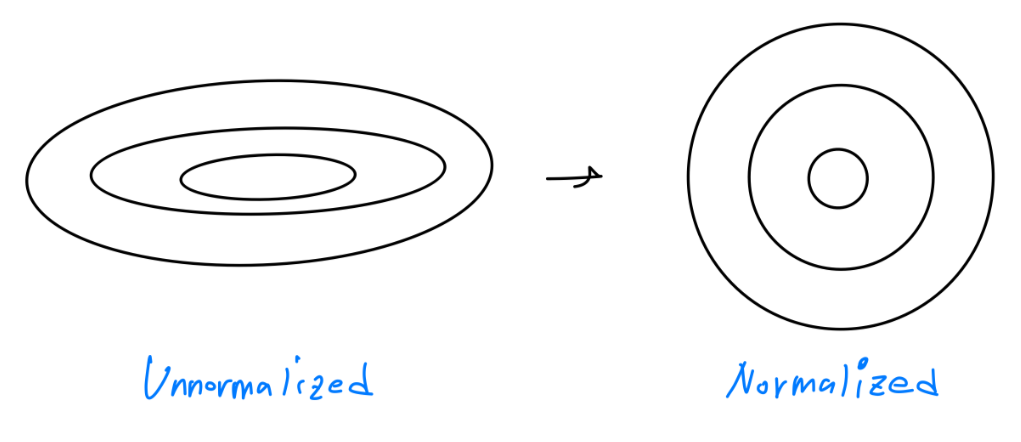
전에 input feature 를 normalize하는 것은 learning 을 더 빠르게 해줄 수 있다고 했었다. 아래와 같은 계산 과정을 거친다.

normalize를 하게 되면 cost function 의 윤곽이 길쭉한 모양에서 둥근 모양으로 될 것이다. 그래서 gradient descent 를 통통해 parameter를 optimize 하는데 더 쉽고 빠르게 만들어준다.
그렇다면 DNN 에서는 Z랑 a 값 중에서 어떤 값을 normalize 해야 할까?
실제로 Z 값을 더 자주 normalize 한다.
아래는 이를 구현한 코드이다.
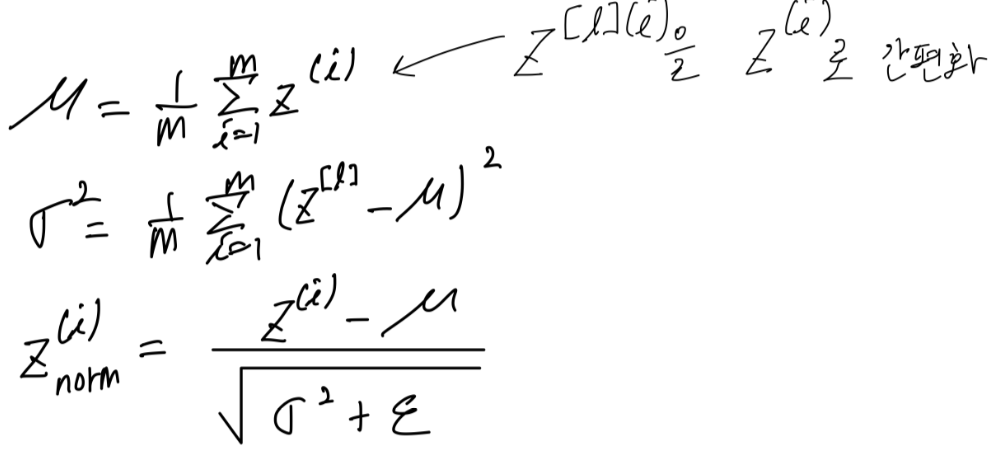
(가 더 정확하지만, 간편하게 하기 위해 몇 번째 layer인지는 생략)
위의 식을 통해 z의 모든 구성요소가 평균이 0이고, 분산이 1이 된다. 하지만, 우리는 hidden unit들이 항상 평균이 0이고, 분산이 1이 되기를 원치 않는다. 다른 분포를 가지는 것이 더 이치에 맞다.
아래의 식을 이용하자.

γ와 β의 다른 값을 선택함으로써 hidden unit values 의 평균과 분산을 다르게 설정할 수 있다.
batch normalization는 이 정규화 과정을 input layer 에만 적용하는 것이 아니라, DNN 에서 hidden layer value 에도 적용한다는 것을 의미한다.
sigmoid function 을 사용하는 경우, 값들이 항상 특정 영역에 집중되지 않기를 원할 수 있다. 더 큰 분산을 갖거나 평균이 0과 다른 값을 가지도록 하여 sigmoid function 의 비선형성을 더 잘 활용할 수 있다. 이는 모든 값들이 단순히 선형 영역에만 머무르는 것을 방지하기 위함이다.
이제, DNN 에서 batch normalization이 적용되는 지 살펴보자.
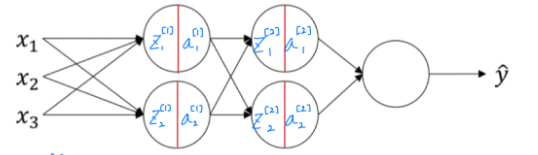

그래서 이제 이 γ와 β는 알고리즘의 새로운 parameter 가 된다. γ와 β 매개변수는 단순히 gradient descent 만을 사용해서 업데이트하는 것이 아니라, Momentum, RMSprop, Adam과 같은 optimizer 를 사용하여 업데이트할 수도 있다.
실제로, training set의 mini-batch 에서는 아래와 같이 적용된다.

이제, 간단하게 정리하기 위해서 parameterization 에 detail 를 살펴보자.
Z^[l] = W^[l]*a^[l-1] + b^[l]
Batch Norm 는 mini-batch 를 보고 Z^[l] 을 먼저 평균과 표준 편차로 정규화한 후, β와 γ로 rescale 한다. 여기서, b^[l] 의 값이 실제로는 그냥 빼지게 된다. 왜냐하면 Batch Norm 단계에서는 Z^[l] 의 평균을 계산하고 그 평균을 빼기 때문이다.
그래서, mini-batch 의 모든 예제에 일정한 상수(b^[l])를 더하는 것은 아무런 변화를 주지 않는다. Batch Norm 이 이 층의 Z^[l] 값들의 평균을 0으로 만들기 때문에, parameter b^[l] 을 갖는 것은 의미가 없다. 따라서 batch Norm를 사용한다면 실제로 그 매개변수 b^[l] 를 제거할 수 있다.

이제, Batch Norm 을 사용해서 gradient descent 를 어떻게 implement 할 수 있는 지 살펴보자.

그렇다면, 어떻게 Batch Norm이 learning 을 효율적으로 빠르게 해줄 수 있는지 살펴보자.
예를 들어, 몇몇 feature 가 0에서 1까지의 범위를 갖고, 일부는 1에서 1,000까지의 범위를 갖을 때, 모든 특성을 정규화하여 유사한 범위를 가지도록 하면 학습 속도가 증가할 수 있다.
이와 비슷한 방식으로, 배치 정규화는 input layer 뿐만 아니라 hidden layer 값들도 정규화하여 유사한 효과를 제공한다. 이로 인해 학습이 더 빨라질 수 있다.
예를 들어, 로지스틱 회귀 또는 얕은 신경망과 같은 네트워크에서 훈련을 수행한다고 가정해보자. 모든 데이터셋이 검은 고양이 이미지로 구성된 경우, 이 네트워크를 색깔 있는 고양이 데이터에 적용하려고 하면 cost function 이 잘 동작하지 않을 수 있다.

검은 고양이 데이터로 훈련된 모델이 색깔 있는 고양이 데이터에서 잘 작동할 것으로 기대하지 않을 수 있다. 이처럼 데이터 분포가 변하는것을 공변량 변화(covariate shift) 라고 한다. 이는 X에서 Y로의 매핑을 학습한 경우, X의 분포가 변하면 학습 알고리즘을 다시 훈련시켜야 할 수도 있다는 것을 의미한다.
배치 정규화는 데이터 분포의 변화를 어느 정도 완화시켜줌으로써, 모델이 다양한 분포의 데이터를 더 잘 일반화할 수 있도록 돕는다. 이로 인해 모델이 새로운 데이터에 더 잘 적응할 수 있게 되어, 재훈련의 필요성을 줄일 수 있다.
또한, Batch Norm은 network 의 더 깊은 층에서 weight 를 안정화시킨다.
신경망의 학습 과정을 third hidden layer 의 관점에서 살펴보면, 이 네트워크는 W^[3]와 b^[3] 를 학습한다. 세 번째 hidden layer 의 관점에서 보면, 이전 layer 에서 전달된 일련의 값을 받아서 output ŷ 이 true value Y와 가까워지도록 처리해야 한다.
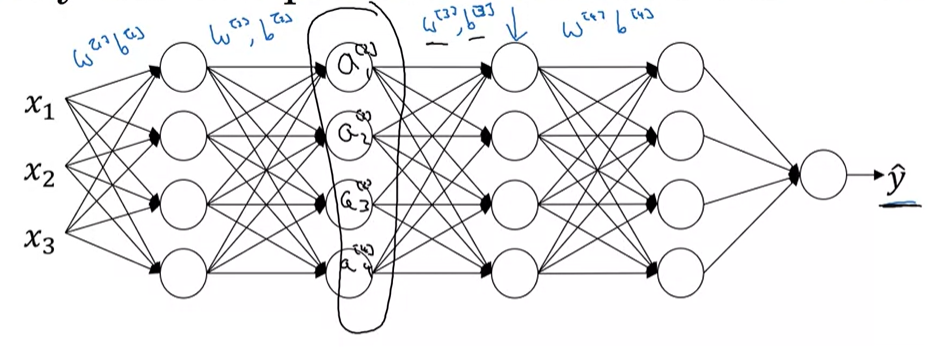
세 번째 hidden layer는 a1^[2] , a2^[2], a3^[2] , a4^[2] 를 입력 받는다. 이 layer의 역할은 이러한 값을 받아서 Y로 매핑하는 것이다. 하지만 network 는 W^[2], b^[2] 와 W^[1], b^[1] 도 조정하고 있으므로, 이 값들로 인해 A^[2] 는 계속해서 변하게 된다. 따라서 세 번째 hidden layer 의 관점에서, 이러한 hidden unit 값들은 항상 변하고 있으며, 이는 공변량 변화(covariate shift) 문제를 일으킨다.
이처럼 실제로 신경망이 이전 계층의 매개변수를 업데이트할 때 값들이 변한다. 하지만 batch Norm 은 이러한 값들이 어떻게 변하든, Z^[2] 의 평균과 분산이 동일하게 유지되도록 보장한다. 이렇게 하면 이전 layer 의 parameter update 가 세 번째 layer가 학습해야 하는 값들의 분포에 미치는 영향을 줄인다. 배치 정규화는 입력 값들의 변화를 줄여주며, 이러한 값들을 더 안정적으로 만듭니다. 그래서 신경망의 이후 계층들이 더 확실한 기반 위에서 학습할 수 있도록 도와준다.
mini-batch X^{t}는 Z^{t} 값을 가지며, 해당 mini-batch 만의 평균(mean)과 분산(variance)이 계산된다. 이 평균과 분산에는 약간의 noise 가 포함되어 있다. 마찬가지로 Z^{t}[l] 에도 약간의 noise 가 있기 때문에, noise 가 있는 평균과 분산을 사용하여 계산된 z~^{t}[l] 에도 노이즈가 있다. 따라서 Dropout 과 비슷하게 각 hidde layer 의 활성화 함수에 일부 noise 를 추가하여 약간의 일반화(generalization) 효과를 준다.
hidden unit 에 noise 를 추가하면, 이후의 hidden unit 들이 특정 hidden unit 에 너무 의존하지 않도록 강제한다. 그러나 추가된 노이즈가 매우 작기 때문에, 이는 큰 정규화 효과를 주지는 않습니다. 더 강력한 정규화 효과가 필요하다면, 배치 정규화와 드롭아웃을 함께 사용할 수 있다.
추가로, mini-batch size 를 늘리면, 더 큰 mini-batch 를 사용함으로써 noise 를 줄이고 regularization 효과도 줄어든다.
실제로, Batch Norm 를 regularization 도구로 사용하지는 않는다. 이는 hidden unit 의 활성화 값을 정규화하여 학습 속도를 높이기 위한 수단으로 사용된다. 배치 정규화에는 약간의 regularization 효과가 있지만, 이를 주된 목적으로 사용하지는 않는다. 따라서 배치 정규화는 학습 속도를 높이기 위한 수단으로 사용해야 한다.
이번에는 test time에서의 Batch Norm 을 살펴보자. (여기서 m 은 전체 training example 이 아니라 mini-batch size이다.)
Batch Norm 는 training 시 한 번에 하나의 mini-batch 를 처리하지만, test 시에는 한 번에 하나의 sample 만 처리해야 할 수도 있다. 이를 어떻게 네트워크에 적용할 수 있는지 확인해보자.
아래는 Batch Norm 을 implement 했던 식이다.

여기서 scaling 계산에 필요한 μ와 σ^2 는 전체 mini-batch 배치에서 계산된다. 그러나 test 시에는 64, 128 또는 256개의 예제를 동시에 처리할 수 없을 수도 있다. 따라서 μ와 σ^2 를 계산하는 다른 방법이 필요하다. 한 예제의 평균과 분산을 계산하는 것은 의미가 없다.
test 시 neural network을 적용하기 위해 μ와 σ^2에 대한 별도의 추정값을 사용해야 한다. 이를 위해 실제로 사용하는 방법은 mini-batch 전반에 걸친 exponentially weighted moving average(EWMA)을 사용하여 μ와 σ^2 를 추정하는 것이다.

L layer을 선택하고 mini-batch X^{1} 를 처리한다고 가정해보자.
EWMA 사용하여 해당 hidden layer 의 Z의 평균을 추정한다. 마찬가지로, 분산을 추적하기 위해 EWMA 을 사용한다. neural network이 여러 mini-batch 를 통해 training 되는 동안 각 layer에서 관찰되는 μ와 σ^2의 moving average을 유지한다.
이처럼 test 시에는 이 방정식을 사용하는 대신, 지수 가중 이동 평균으로 계산한 μ와 σ^2를 사용하여 Znorm{t}[l](i)를 계산하여 test 한다.
Programming Frameworks
neural networks 를 implement 하는 것을 용이하게 해주는 많은 deep learning framework 가 있다.
- Caffe / Caffe2
- CNTK
- DL4J
- Keras
- Lasagne
- mxnet
- PaddlePaddle
- Tensorflow
- Theano
- Torch
특정 framework 들을 강하게 지지하기 보다는 framework 를 선택할 때 고려해야할 기준 3가지를 설명하고자 한다.
- Ease of programming (development and deployment) : neural network 를 개발하고 반복하는 것 뿐만 아니라, 실제로 수천, 수백만 또는 수억 명의 사용자가 사용할 수 있도록 배포하는 것도 포함한다.
- Running speed : 대규모 data set 에서 training 할 때 일부 framework 는 neural network 를 더 효율적으로 실행하고 train 할 수 있게 해준다.
- Truly open (open source with good governance) : framework 가 진정으로 오픈되려면 open source 뿐만 아니라 좋은관리 체계를 가져야 한다. software 산업에서는 일부 회사가 software를 open source로 공개하지만, 단일 기업이 software를 통제하는 역사를 가지고 있다. 몇 년 동안 사람들이 software를 사용하기 시작하면, 일부 회사는 open source 를 닫거나 기능을 자체 독점 cloud service 로 옮기는 역사를 가지고 있다. 따라서, framework 가 장기적으로 open source로 남을 것인지, 아니면 현재 open source로 공개되어 이썯라도 미래에 단일 회사의 통제하에 닫힐지 여부를 얼마나 신뢰할 수 있는지에 주목한다. 하지만 적어도 단기적으로는 사용 언어의 선호도(Python, java, c++ 등) 와 작업하는 application 에 따라 여러 framework 가 좋은 선택이 될 수 있다.
현재 살아남은 framework 로는 Tensorflow와 PyTorch가 있다. 과거부터 TensorFlow가 독점하다시피 했지만, 논문을 쓸 떄 활용하는 framework는 대부분이 PyTorch 라고 한다. 따라서 둘 다 다룰줄 알아야 한다.
deep learning framework 중에 하나인 tensorflow 에 대해서 알아보자.
TensorFlow
TensorFlow 프로그램의 기본 구조를 단계별로 설명하여 TensorFlow를 사용하여 프로그램을 구현하고 신경망을 직접 구현하는 방법을 살펴보고자 한다.
cost function J(w) = w^2 - 10w + 25라고 하자. 우리는 cost function 을 minimize 하기 위한 w 값이 5라는 것을 알고 있다. 하지만 이를 모른다고 가정하고, 이 함수를 Tensorflow 로 minimize 하는 방법을 살펴보자.
import numpy as np
import tensorflow as tf
w = tf.Variable(0.0, dtype=tf.float32) # w 초기화: 0
optimizer = tf.keras.optimizers.Adam(learning_rate=0.1) # 최적화 알고리즘 정의 : Adam, learning rate : 0.1
def train_step():
with tf.GradientTape() as tape:
cost = w**2 - 10*w + 25
trainable_variables = [w]
grads = tape.gradient(cost, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
우선, train 하기 전에 w 를 print 해보자.
print(w)
>> <tf.Variable 'Variable:0' shape=() dypte=float32, numpy=0.0>
1번의 train 이 끝나고 나서의 w 를 print 해보자.
train_step()
print(w)
>> <tf.Variable 'Variable:0' shape=() dypte=float32, numpy=0.09999997>
이제, 1000번 training 을 하고 w를 print 해보자.
for i in range(1000):
train_step()
print(w)
>>>> <tf.Variable 'Variable:0' shape=() dypte=float32, numpy=5.000001>
거의 정답과 아주 유사하게 나온 것을 확인할 수 있다.
TensorFlow 는 cost function 만 정의하면 자동으로 backpropagation 을 수행하고 기울기를 계산한다. 그래서 우리는 forward propagation 만 설계하면 된다. 이처럼 복잡한 DNN 을 설계하는데 있어서 도움을 준다.
'연구실 > 인공지능(Coursera)' 카테고리의 다른 글
| [AI 9주차] 심층 컨볼루션 모델(Deep convolution model) (0) | 2024.08.07 |
|---|---|
| [AI 8주차] Convolution Neural Network (CNN) 기초 (0) | 2024.08.05 |
| [AI 6주차] Optimization Algorithm (0) | 2024.07.15 |
| [AI 5주차] Deep learning의 실용적인 측면 (0) | 2024.07.02 |
| [AI 4주차] DNN(깊은 신경망) (0) | 2024.06.27 |



