Fuzzing : Breaking Things with Random Inputs
Fuzzing이라고 알려져 있는 random text generation의 핵심 아이디어는 Failure를 드러내기 위해 program에 random 문자열을 넣는 것이다.
Fuzzers
Fuzzer는 Fuzzers에 대한 base class이다. Fuzzer가 가지고 있는 RandomFuzzer 는 단순 인스턴스화이다.
Fuzzer의 fuzz()는 생성된 input 의 문자열을 return 해주는 메소드이다.
class RandomFuzzer(Fuzzer):
"""Produce random inputs."""
def __init__(self, min_length: int = 10, max_length: int = 100,
char_start: int = 32, char_range: int = 32) -> None:
"""Produce strings of `min_length` to `max_length` characters
in the range [`char_start`, `char_start` + `char_range`)"""
self.min_length = min_length
self.max_length = max_length
self.char_start = char_start
self.char_range = char_range
def fuzz(self) -> str:
string_length = random.randrange(self.min_length, self.max_length + 1)
out = ""
for i in range(0, string_length):
out += chr(random.randrange(self.char_start,
self.char_start + self.char_range))
return out
import bookutils.setup
from typing import Dict, Tuple, Union, List, Any
import Intro_Testing
from Fuzzer import RandomFuzzer
random_fuzzer = RandomFuzzer()
random_fuzzer.fuzz()
RandomFuzzer() 생성자는 많은 keyword 매개변수를 허용한다.
print(RandomFuzzer.__init__.__doc__)
아래는 10~20 길이를 갖는 'A'~'Z' 범위의 랜덤한 문자열을 출력하는 예시이다.
random_fuzzer = RandomFuzzer(min_length=10, max_length=20, char_start=65, char_range=26)
random_fuzzer.fuzz()

Fuzzer는 fuzz된 문자열을 input 으로 취하는 Runner와 쌍으로 존재한다. 그 결과는 class 해당 상태와 결과(Pass, Fail, Unresolved) 이다. PrintRunner는 단순하게 주어진 input을 print out 하고, Pass 결과를 return 한다.
class PrintRunner(Runner):
"""Simple runner, printing the input."""
def run(self, inp) -> Any:
"""Print the given input"""
print(inp)
return (inp, Runner.UNRESOLVED)
from Fuzzer import RandomFuzzer, PrintRunnerprint_runner = PrintRunner()
random_fuzzer.run(print_runner)
ProgramRunner는 생성된 input을 외부 program으로 넣는다.
그 결과는 program 상태와 결과(Pass, Fail. Unresolved)의 쌍이다.
class ProgramRunner(Runner):
"""Test a program with inputs."""
def __init__(self, program: Union[str, List[str]]) -> None:
"""Initialize.
`program` is a program spec as passed to `subprocess.run()`"""
self.program = program
def run_process(self, inp: str = "") -> subprocess.CompletedProcess:
"""Run the program with `inp` as input.
Return result of `subprocess.run()`."""
return subprocess.run(self.program,
input=inp,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
def run(self, inp: str = "") -> Tuple[subprocess.CompletedProcess, Outcome]:
"""Run the program with `inp` as input.
Return test outcome based on result of `subprocess.run()`."""
result = self.run_process(inp)
if result.returncode == 0:
outcome = self.PASS
elif result.returncode < 0:
outcome = self.FAIL
else:
outcome = self.UNRESOLVED
return (result, outcome)
from Fuzzer import RandomFuzzer, PrintRunner, ProgramRunnercat = ProgramRunner('cat')
random_fuzzer.run(cat)

이를 정리하면 다음과 같다.

Fuzzer 모듈에 Fuzzer와 Runner라는 class가 쌍으로 각각 존재한다.
- Fuzzer : base class
- RandomFuzzer : 매개변수 제약에 따른 random한 string 을 생성하는 class
- fuzz() : 생성된 input을 갖는 string 을 return 한다.
- RandomFuzzer : 매개변수 제약에 따른 random한 string 을 생성하는 class
- Runner : fuzz된 문자열을 input으로 취하는 class
- ProgramRunner
- run() : 생성된 input을 외부 program 에 넣는다.
- PrintRunner
- run() : 주어진 input을 print 한다.
- ProgramRunner
A Simple Fuzzer
fuzz generator를 build 하기 위해서 random 문자를 만들어서 이를 buffer string 변수 (out)에 더하고 마지막에 문자열을 return 한다.
아래는 실제 fuzzer() 함수이다.
def fuzzer(max_length: int=100, char_start: int = 32, char_range : int = 32) -> str:
"""A string of up to `max_length` characters
in the range [`char_start`, `char_start` + `char_range`)"""
string_length = random.randrange(0, max_length+1)
out = ""
for i in range(0, string_length):
out += chr(random.randrange(char_start, char_start+char_range))
return out
default 는 random 문자열을 return 한다.
fuzzer()
fuzzing이 다른 종류의 input 을 만들도록 쉽게 설정될 수 있다.
아래는 일련의 소문자를 생산하도록 하는 예시이다. 여기서, ord('char')는 'char'를 ASCII 코드로 return 해주는 메소드이다.
fuzzer(1000, ord('a'), 26)
아래는 임의 길이의 10진수 문자열을 만드는 예제이다.
fuzzer(100, ord('0'), 10)
Fuzzing External Programs
fuzz된 input 으로 외부 program을 호출한다고 하면 어떤 일이 일어날지 살펴보자.
우선, fuzz된 test data로 input file을 만들고, 이러한 input file을 program 으로 넣어보자.
- Creating Input Files
import os
import tempfile
basename = "input.txt"
tempdir = tempfile.mkdtemp()
FILE = os.path.join(tempdir, basename)
print(FILE)
이 파일에 내용을 쓰기 위해 파일을 open 할 수 있다.
data = fuzzer()
with open(FILE, 'w') as f:
f.write(data)
해당 파일에 내용이 잘 들어갔는지 확인하기 위해 파일을 읽어서 해당 내용과 fuzz된 내용과 일치하는지 확인해볼 수 있다.
contents = open(FILE).read()
print(contents)
assert(contents == data)
Invoking External Programs
input file 을 갖고 있으므로, 이를 가지고 외부 program 을 호출할 수 있다.
bc 는 계산 program이다. 산술식을 평가한다.
import os
import subprocess
program = 'bc'
with open(FILE, 'w') as f:
f.write("2 + 2\n")
result = subprocess.run([program, FILE],
stdin=subprocess.DEVNULL,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines = True) # will be 'text' in python 3.7
program 의 output 을 확인할 수 있다.
result.stdout
>> '4\n'
상태도 확인할 수 있다. 0의 값은 program이 올바르게 끝났다는 것을 의미한다.
result.returncode
>> 0
에러가 있다면 에러 메시지를 확인할 수도 있다.
result.stderr
>> ''
실제로 원하는 프로그램을 넣을 수 있지만, 만약 프로그램이 system을 바꾸거나 피해를 끼친다면 fuzz된 input이 정확하게 this.bc를 수행하는 명령이나 data를 포함할 위험이 있다.
file를 제거하는 program을 test 한다고 했을 때, 나의 모든 file 들을 제거할 인자를 생산할 확률이 얼마나 될까?
rm -fr . whatever ...
rm -fr / whatever ...
생각했던 것 보다 확률이 더 높을지도 모른다. 만약 모든 file의 root( / )를 제거한다면, 전체 파일 시스템이 사라질 것이다. 만약 현재 폴더( . )를 제거한다면, 현재 디렉토리에 있는 모든 파일들이 제거될 것이다.
전체 문자 중 `. ` , ` / ` 둘 중에 하나가 선택될 확률은 2 / 32 이다. 정확하게 1개의 문자 길이인 문자열을 만들거나 0개의 문자 길이인 문자열을 확률은 2 / 101 이다. 문자열의 길이는 random.randrange(0, max_length+1)를 호출함으로서 결정되기 때문이다. 여기서 max_length의 default 길이는 100이다. 한편, 문자 길이가 0개거나 1개인 경우에는 제외해야 하므로 두 문자 이상이 나올 확률은 1- (2/101) = 99/101 이다. 따라서, 모든 파일이 제거될 확률은 다음과 같이 계산된다.
- 첫 번째 문자: / or . 일 확률 => 2/32
- 두 번째 문자: 공백일 확률 => 1/32
- 두 문자 이상일 확률 => (1-2/101) = 99/101
2/32 * 1/32 * 99/101 = 0.001914 ...
따라서, 1 / 1000 정도의 확률이다.
Long-Running Fuzzing
앞서 언급한 파일 제거 프로그램을 테스트하기 위해 많은 입력을 프로그램에 feed 하여 프로그램이 일부 입력에서 crash 하는지 확인하는 과정을 살펴보자. 결과는 input data 와 실제 result 를 쌍으로 저장한다. 이 코드는 실행하는데 오래걸릴 수 있다.
trials = 100
program = "bc"
runs = []
for i in range(trials):
data = fuzzer()
with open(FILE, "w") as f:
f.write(data)
result = subprocess.run([program, FILE],
stdin=subprocess.DEVNULL,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
runs.append((data, result))
100번의 시도를 통해 input data 를 생성하여 file 에 저장한 다음 'bc' 프로그램으로 실행한다. 그 결과를 runs 리스트에 저장한다.
통계를 query할 수 있다. 실제로 통과된 실행 수를 query 할 수 있다. 즉, 오류 메시지가 없는 실행 수를 구할 수 있다.
sum(1 for (data, result) in runs if result.stderr == "")
>> 9
오류 메시지가 없는 실행에 대해서 1을 반환하여, 이러한 실행의 총 합계를 구하는 코드이다. 9개만 통과되었다. 대부분의 input들이 invalid 하다. 아래 코드를 통해 첫 번째 오류 메시지를 확인해보자.
errors = [(data, result) for (data, result) in runs if result.stderr != ""]
(first_data, first_result) = errors[0]
print(repr(first_data))
print(first_result.stderr)'5&8>"86,?"/7!1%5-**&-$&)$91;"21(\'8"(%$4,("(&!67%89$!.?(*(96(28$=6029:<:$(6 !-+2622(&4'
Parse error: bad character '&'
/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1
random 한 input이 유효한 산술 표현식을 포함할 가능성이 낮기 때문에 대부분의 input 이 invalid 하다는 것을 확인할 수 있다.
추가로, illegal character , parse errror, syntax error 이외의 error message가 있는지 확인해볼 수 있다.
[result.stderr for (data, result) in runs if
result.stderr != ""
and "illegal character" not in result.stderr
and "parse error" not in result.stderr
and "syntax error" not in result.stderr]["\nParse error: bad character '&'\n /var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1\n\n",
'\nParse error: bad expression\n /var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1\n\n',
'\nParse error: bad expression\n /var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1\n\n',
'\nParse error: bad token\n /var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1\n\n',
'\nParse error: bad token\n /var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1\n\n',
'\nParse error: bad token\n /var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1\n\n',
'\nParse error: bad token\n /var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1\n\n',
'\nParse error: bad token\n /var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/tmpq311ya4x/input.txt:1\n\n',
...
]
sum(1 for (data, result) in runs if result.returncode != 0)
>> 91
이처럼 파일 제거 프로그램이 random input에 대해 어떻게 반응하는지 test하고, error message 를 분석하여 프로그램의 취약성을 찾는 과정을 보여준다.
fuzzing을 통해 다양한 입력에 대해 bc 프로그램을 테스트했지만, 대부분의 오류는 illegal character, parse error, syntax error와 같은 형태로 나타났다.
Bugs Fuzzers Find
: Miller 와 그의 학생들이 1989년에 퍼저를 처음 사용했을 때, UNIX utilities 중 약 1/3 이 문제가 있다는 사실을 발견했다. 이들은 fuzzing input 에 의해 crash 되거나, 멈추거나, 실패했다. 많은 UNIX utilities가 network input을 처리하는 script 에서 사용되었기 때문에 이는 매우 심각한 결과였다. 그래서, programmer 들은 빠르게 그들 자신의 fuzzer 를 만들어 오류를 수정하고 외부 input을 신뢰하지 않게 되었다. Miller와 그의 학생들이 어떠한 종류의 문제들을 발견했는지 살펴보자.
- Buffer Overflows : C 언어와 같은 언어에서 입력의 최대 길이를 초과하면 버퍼 오버플로우가 발생할 수 있다. 예를 들어, 문자열을 복사할 때 8자 이상의 문자열을 복사하면 메모리의 다른 부분에 영향을 줄 수 있다.
char weekday[9]; // 8 characters + trailing '\0' terminator
strcpy (weekday, input);
Python 코드로 이러한 버퍼 오버플로우를 시뮬레이션할 수 있다. 입력이 너무 길면 ValueError 를 발생시키는 함수를 작성하여 이를 확인할 수 있다.
def crash_if_too_long(s):
buffer = "Thursday"
if len(s) > len(buffer):
raise ValueError
- Missing Error Checks : 많은 프로그래밍 언어는 예외 처리를 제공하지 않고, 대신 함수가 특별한 오류 코드를 반환한다. 예를 들어, C의 getchar() 함수는 입력이 더 이상 없을 때 EOF(end of file)를 반환한다. 하지만 이 오류 코드를 처리하지 않으면 무한 루프에 빠질 수 있다.
while (getchar()!= ' ')
Python 코드로 이 상황을 시뮬레이션할 수 있으며, 시간이 초과되면 함수 실행을 중단시켜 무한 루프를 방지할 수 있다.
def hang_if_no_space(s):
i = 0
while True:
if i < len(s):
if s[i] == ' ':
break
i += 1from ExpectError import ExpectTimeout
trials = 100
with ExpectTimeout(2):
for i in range(trials):
s = fuzzer()
hang_if_no_space(s)
- Rogue Numbers : fuzzer 는 input 에 비정상적인 값을 쉽게 생성할 수 있다. 예를 들어, 매우 큰 값이나 음수 값을 입력하면 프로그램이 메모리 할당에 실패하거나 이상한 동작을 할 수 있다.
Python 코드로 이러한 상황을 시뮬레이션할 수 있다. 특정 값이 너무 크면 오류를 발생시키는 함수를 작성하여 이를 확인할 수 있다.
def collapse_if_too_large(s):
if int(s) > 1000:
raise ValueErrorlong_number = fuzzer(100, ord('0'), 10)
print(long_number)
>> 7056414967099541967374507745748918952640135045with ExpectError():
collapse_if_too_large(long_number)
Catching Error
: Miller와 그의 학생들이 처음으로 fuzzer 를 만들었을 때, program이 crash 되거나 멈추는 현상으로 error 를 쉽게 식별할 수 있었다. 그러나 실패가 더 미묘한 경우에는 추가적인 검사가 필요하다.
Generic Checkers
: Buffer overflows 는 일반적인 문제의 특정 사례다. C 및 C++와 같은 언어에서는 프로그램이 초기화되지 않았거나 이미 해제되었거나 데이터 구조의 일부가 아닌 메모리의 임의의 부분에 접근할 수 있다. 이는 최대의 성능이나 제어가 필요한 경우 좋지만, 실수를 피하고 싶을 때는 매우 나쁘다. 다행히 run-time에 이러한 문제를 잡는 도구들이 있으며, 퍼징(fuzzing)과 결합했을 때 매우 유용하다.
- Checking Memory Accesses : test 중 문제 있는 메모리 접근을 잡기 위해, C program 을 특별한 메모리 검사 환경에서 실행할 수 있다. run-time 에 이러한 환경들은 모든 메모리 작업이 유효하고 초기화된 메모리를 접근하는지 검사한다. 인기있는 예로는 LLVM Address Sanitizer 가 있으며, 이는 잠재적으로 위험한 메모리 안전성 위반을 탐지합니다. 다음 예제에서는 LLVM Address Sanitizer 를 사용하여 간단한 C program을 컴파일하고 할당된 메모리 부분을 넘어 읽음으로써 경계 밖 읽기 오류를 유발한다.
with open("program.c", "w") as f:
f.write("""
#include <stdlib.h>
#include <string.h>
int main(int argc, char** argv) {
/* Create an array with 100 bytes, initialized with 42 */
char *buf = malloc(100);
memset(buf, 42, 100);
/* Read the N-th element, with N being the first command-line argument */
int index = atoi(argv[1]);
char val = buf[index];
/* Clean up memory so we don't leak */
free(buf);
return val;
}
""")from bookutils import print_file
print_file("program.c")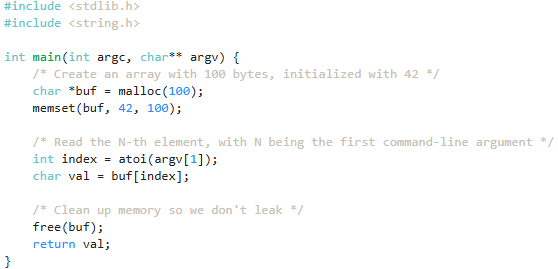
jupyter notebook 에서 아래 shell 명령어를 실행해보자.
!clang -fsanitize=address -g -o program program.c
clang은 c 언어를 위한 컴파일러이다. LLVM 프로젝트의 일부로 개발되었다. -fsanitize=address 는 주소 검사를 활성화한다. 주소 검사는 메모리 관련 오류를 탐지하는 데 사용되며, 주로 다음과 같은 오류를 찾는다.
- stack overflow
- heap buffer overflow
- Use-after-free
- Double-free
- memory leak
-g 는 디버깅 정보를 포함하도록 컴파일한다. -o program 은 컴파일된 실행 파일의 이름을 program으로 지정한다. program.c 는 컴파일할 source file 의 이름이다.
아래는 정상적인 경우에 대한 프로그램 실행이다. buf [99]
!./program 99; echo $?
>> 42
아래는 경계 밖 접근하는 경우에 대한 프로그램 실행이다. buf [110]
!./program 110=================================================================
==84371==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x000101002a9e at pc 0x000100fc3e84 bp 0x00016ee3e8a0 sp 0x00016ee3e898
READ of size 1 at 0x000101002a9e thread T0
#0 0x100fc3e80 in main program.c:12
#1 0x194be60dc (<unknown module>)
0x000101002a9e is located 10 bytes after 100-byte region [0x000101002a30,0x000101002a94)
allocated by thread T0 here:
#0 0x1018df124 in wrap_malloc+0x94 (libclang_rt.asan_osx_dynamic.dylib:arm64e+0x53124)
#1 0x100fc3dc8 in main program.c:7
#2 0x194be60dc (<unknown module>)
SUMMARY: AddressSanitizer: heap-buffer-overflow program.c:12 in main
C program 에서 error 를 찾고 싶다면 퍼징(fuzzing)을 위한 이러한 검사 기능을 켜는 것은 꽤 쉽다. 도구에 따라 실행 속도가 느려질 수 있지만(AddressSanitizer의 경우 일반적으로 2배 느려짐), 이러한 버그를 찾는 데 드는 인간의 노력에 비하면 CPU 사이클은 매우 저렴하다.
메모리 경계 밖 접근은 큰 보안 위험을 초래할 수 있다. 이는 공격자가 접근해서는 안 되는 정보를 접근하거나 수정할 수 있게 하기 때문입니다. 유명한 예로는 OpenSSL library에서 발견된 HeartBleed bug가 있다. 이 라이브러리는 네트워크 상의 통신 보안을 제공하는 암호화 프로토콜을 구현한다. (이 텍스트를 브라우저에서 읽고 있다면, 이러한 프로토콜을 사용하여 암호화된 것이다.)
HeartBleed 버그는 SSL Heartbeat service 에 특별히 조작된 명령을 보내어 악용되었다. 이는 반대편 서버가 여전히 작동 중인지 확인하는 데 사용된다. 클라이언트는 서비스에 "BIRD" (4자)를 보내면, 서버는 "BIRD"로 응답하여 서버가 작동 중임을 확인할 수 있다. 불행히도, 이 서비스는 서버에 요청된 문자 수보다 더 많은 문자를 응답하도록 악용될 수 있었습니다. 이는 아래 만화에서 잘 설명되어 있다.
Server, Are you still there? If so, reply "POTATO" (6 Letters).
>> POTATO
Server, Are you still there? If so, reply "BIRD" (4 Letters).
>> BIRD
Server, Are you still there? If so, reply "HAT" (500 Letters).
>> "HAT". Lucas requests the "missed connections" page. Eve(Administrator) wants to set
server's master key to "14835038534". Isabel wants pages about snakes but not too long".
User Karen wants to change account passward to "CoHoBaSt". User ...
OpenSSL 구현에서는 이러한 메모리 내용이 암호화 인증서, 비밀 키 등을 포함할 수 있으며, 심지어 누군가가 이 메모리를 접근했는지 전혀 눈치채지 못할 수도 있다. HeartBleed 버그가 발견되었을 때, 이 버그는 이미 여러 해 동안 존재해 왔으며, 어떤 비밀이 이미 유출되었는지 아무도 알 수 없었다.
그렇다면, HeartBleed 버그는 어떻게 발견되었을까? 매우 간단하다.
Codenomicon 회사와 Google의 연구원들이 OpenSSL 라이브러리를 메모리 검사기(memory sanitizer)를 사용하여 컴파일한 후, 퍼징된 명령으로 라이브러리를 공격했다. 메모리 검사기는 경계 밖 메모리 접근이 발생했는지 감지할 수 있으며, 실제로 이 버그를 매우 빠르게 발견했다.
- Information Leaks : 정보 유출은 불법적인 메모리 접근을 통해서만 발생하는 것이 아니다. "유효한" 메모리 내에서도 발생할 수 있다. 특히 이 "유효한" 메모리에 민감한 정보가 포함되어 있다면 그 정보가 유출되지 않도록 해야 한다. 아래는 이러한 문제를 설명하기 위한 Python 프로그램 예제이다.
우선, 실제 data와 random data로 채워진 program memory 를 만든다.
secrets = ("<space for reply>" + fuzzer(100) +
"<secret-certificate>" + fuzzer(100) +
"<secret-key>" + fuzzer(100) + "<other-secrets>")
그리고 "deadbeef" 라는 marker로 초기화되지 않은 메모리를 추가한다.
uninitialized_memory_marker = "deadbeef"
while len(secrets) < 2048:
secrets += uninitialized_memory_marker
아래와 같이 heartbeat servise와 유사한 서비스를 정의한다. 이 서비스는 응답할 문자열(reply)과 길이(length)를 받아 메모리에 저장한 후 지정된 길이만큼 응답을 보낸다.
def heartbeat(reply: str, length: int, memory: str) -> str:
# Store reply in memory
memory = reply + memory[len(reply):]
# Send back heartbeat
s = ""
for i in range(length):
s += memory[i]
return s
위의 서비스는 표준 문자열에서는 정상적으로 동작한다.
print(heartbeat("potato", 6, memory=secrets))
>> potato
print(heartbeat("bird", 4, memory=secrets))
>> bird
하지만, 길이가 응답 문자열보다 길면 메모리의 추가 내용이 유출된다. 이는 여전히 배열 경계 내에서 발생하므로 주소 검사기는 이를 감지하지 못한다.
print(heartbeat("hat", 500, memory=secrets))
"""
>> hatace for reply>#,,!3?30>#61)$4--8=<7)4 )03/%,5+! "4)0?.9+?3();<42?=?0
<secret-certificate>7(+/+((1)#/0\'4!>/<#=78%6$!!$<-"3"\'-?1?85!05629%/); *)1\'/=9%
<secret-key>.(#.4%<other-secrets>deadbeefdeafbeef...
"""
이러한 문제를 탐지하려면 유출되어서는 안 되는 정보를 식별해야 한다. 다음은 이러한 체크를 시뮬레이션하는 작은 Python 예제이다.
from ExpectError import ExpectError
import random
with ExpectError():
for i in range(10):
s = heartbeat(fuzzer(), random.randint(1, 500), memory=secrets)
assert not s.find(uninitialized_memory_marker)
assert not s.find("secret")
이 체크를 통해 실제로 secrets와 초기화되지 않은 메모리가 유출되는 것을 발견할 수 있다.
정보 유출은 불법적인 메모리 접근뿐만 아니라 "유효한" 메모리에서도 발생할 수 있다. 이러한 유효한 메모리에 민감한 정보가 포함되어 있다면 유출되지 않도록 해야 한다. 이를 방지하기 위한 체크 방법을 살펴보자.
Program-Specific Checkers
: 특정 프로그램이나 서브 시스템에 적용할 수 있는 검사 도구를 만들 수 있다. 여기서 중요한 개념 중 하나는 assertion 이다. 이는 중요한 함수의 입력 조건(전제 조건)과 결과(후제 조건)를 검사하는 술어입니다. 어설션을 많이 사용할수록 실행 중에 오류를 감지할 확률이 높아진다. 성능에 대한 영향을 걱정하는 경우, assertion을 프로덕션 코드에서 비활성화할 수 있다.
assertion을 사용하여 복잡한 데이터 구조의 무결성을 검사하는 것이 중요하다. 아래 코드는 공항 코드와 공항명을 mapping하는 간단한 예제이다.
from typing import Dict
airport_codes: Dict[str, str] = {
"YVR": "Vancouver",
"JFK": "New York-JFK",
"CDG": "Paris-Charles de Gaulle",
"CAI": "Cairo",
"LED": "St. Petersburg",
"PEK": "Beijing",
"HND": "Tokyo-Haneda",
"AKL": "Auckland"
} # plus many moreprint(airport_codes["YVR"])
>> Vancouver
print("AKL" in airport_codes)
>> True
이 공항 코드 list 는 중요하다. 잘못된 코드가 포함되면 애플리케이션에 영향을 미칠 수 있다. 따라서 리스트의 일관성을 검사하는 함수를 도입다. 이를 표현 불변 조건(representation invariant)이라 하며, 이를 검사하는 함수는 일반적으로 repOK()라고 한다.
개별 공항 코드를 검사하는 함수 code_repOK를 정의한다. 코드가 일관되지 않으면 실패합니다.
def code_repOK(code: str) -> bool:
assert len(code) == 3, "Airport code must have three characters: " + repr(code)
for c in code:
assert c.isalpha(), "Non-letter in airport code: " + repr(code)
assert c.isupper(), "Lowercase letter in airport code: " + repr(code)
return True
assert code_repOK("SEA")
이제 리스트의 모든 요소를 code_repOK로 검사한다.
def airport_codes_repOK() -> bool:
for code in airport_codes:
assert code_repOK(code)
return True
from ExpectError import ExpectError
with ExpectError():
assert airport_codes_repOK()
리스트에 잘못된 요소를 추가하면 검사에 실패한다. (공항 코드가 3자가 아님)
airport_codes["YMML"] = "Melbourne"
"""
=>airport_codes: Dict[str, str] = {
"YVR": "Vancouver",
"JFK": "New York-JFK",
"CDG": "Paris-Charles de Gaulle",
"CAI": "Cairo",
"LED": "St. Petersburg",
"PEK": "Beijing",
"HND": "Tokyo-Haneda",
"AKL": "Auckland",
"YMML" : Melbourne" # changed
}
"""
with ExpectError():
assert airport_codes_repOK()
리스트를 직접 수정하는 대신, 요소를 추가하는 함수를 정의하여 코드를 검사한다.
def add_new_airport(code: str, city: str) -> None:
assert code_repOK(code)
airport_codes[code] = city
with ExpectError():
add_new_airport("BER", "Berlin")
airport_codes Dictionary에 잘못된 요소가 삽입되어 있지만, 전체 코드를 검사하지 않고 호출하는 특정 코드에 대해서만 검사를 하므로 에러가 발생하지 않는다.
인자 리스트에 오류가 있는지 확인할 수도 있다.
with ExpectError():
add_new_airport("London-Heathrow", "LHR")
airport_codes Dictionary에 잘못된 요소가 삽입되어 있지만, 전체 코드를 검사하지 않고 호출하는 특정 코드에 대해서만 검사를 하지만, 특정 코드가 에러가 있으므로, 특정 코드에 대한 에러만 발생시킨다.
리스트의 올바른 표현을 보장하기 위해 변경 전후로 검사를 수행하는 함수 add_new_airport_2 를 정의한다.
def add_new_airport_2(code: str, city: str) -> None:
assert code_repOK(code)
assert airport_codes_repOK()
airport_codes[code] = city
assert airport_codes_repOK()
with ExpectError():
add_new_airport_2("IST", "Istanbul Yeni Havalimanı")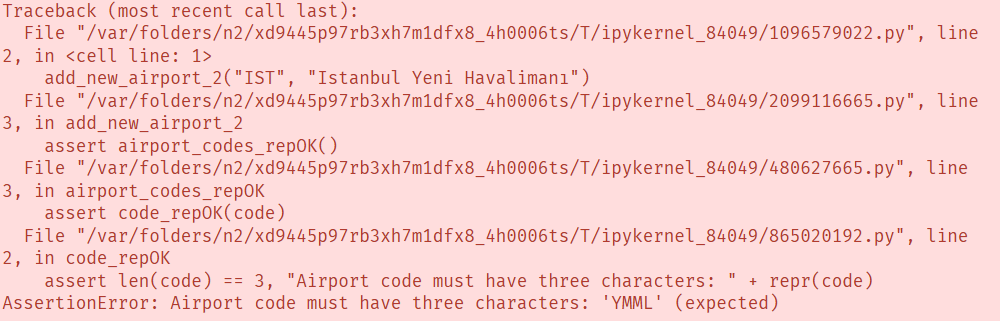
airport_codes Dictionary에 잘못된 요소가 삽입되어 있어서 전체 코드를 검사하는 과정에서 YMML 에 대한 에러 메시지가 발생한다.
아래는 레드-블랙 트리(Red-Black Tree)와 같은 복잡한 데이터 구조의 무결성을 검사하는 예제이다.
class RedBlackTree:
def repOK(self) -> bool:
assert self.rootHasNoParent()
assert self.rootIsBlack()
assert self.rootNodesHaveOnlyBlackChildren()
assert self.treeIsAcyclic()
assert self.parentsAreConsistent()
return True
def rootIsBlack(self) -> bool:
if self.parent is None:
assert self.color == "BLACK"
return True
def add_element(self, elem) -> None:
assert self.repOK()
# Add the element
assert self.repOK()
def delete_element(self, elem) -> None:
assert self.repOK()
# Delete the element
assert self.repOK()
repOK() 메서드는 RedBlackTree 클래스의 객체에서 실행됩니다. 요소가 추가되거나 삭제될 때마다 일관성 검사를 자동으로 수행합니다.
Static Code Checkers
: repOK() assertion 에서 얻을 수 있는 많은 이점은 정적 타입 검사기를 사용하여도 얻을 수 있다. 예를 들어, Python의 MyPy 정적 검사기는 인수의 타입이 올바르게 선언되면 타입 오류를 즉시 찾을 수 있다
typed_airport_codes: Dict[str, str] = {
"YVR": "Vancouver",
}
typed_airport_codes[1] = "First" # This will be caught by MyPy$ mypy airports.py
airports.py: error: Invalid index type "int" for "Dict[str, str]"; expected type "str"
더 고급 속성을 정적으로 검사하는 것은 한계가 있지만, repOK() assertion은 여전히 필요하며 좋은 테스트 생성기와 함께 사용하면 최상의 결과를 얻을 수 있다.
A Fuzzing Architecture
먼저, input 을 실행할 객체의 개념인 Runner를 보자.
Outcome = str
class Runner:
"""Base class for testing inputs."""
# Test outcomes
PASS = "PASS"
FAIL = "FAIL"
UNRESOLVED = "UNRESOLVED"
def __init__(self) -> None:
"""Initialize"""
pass
def run(self, inp: str) -> Any:
"""Run the runner with the given input"""
return (inp, Runner.UNRESOLVED)
여기서는 입력을 받아 실행하는 기본 클래스이다. 더 복잡한 Runner를 만들기 위해 이 클래스를 기반으로 상속하여 추가 메서드를 추가하거나 기존 메서드를 재정의할 수 있다.
아래는 입력을 단순히 출력하는 PrintRunner의 예시이다.
class PrintRunner(Runner):
"""Simple runner, printing the input."""
def run(self, inp) -> Any:
"""Print the given input"""
print(inp)
return (inp, Runner.UNRESOLVED)p = PrintRunner()
(result, outcome) = p.run("Some input")
>>Some inputprint(result)
>>Some input
print(outcome)
>>UNRESOLVED
ProgramRunner 클래스는 input을 프로그램의 표준 input으로 보낸다.
import subprocess
from typing import Union, List, Tuple
class ProgramRunner(Runner):
"""Test a program with inputs."""
def __init__(self, program: Union[str, List[str]]) -> None:
"""Initialize.
`program` is a program spec as passed to `subprocess.run()`"""
self.program = program
def run_process(self, inp: str = "") -> subprocess.CompletedProcess:
"""Run the program with `inp` as input.
Return result of `subprocess.run()`."""
return subprocess.run(self.program,
input=inp,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
def run(self, inp: str = "") -> Tuple[subprocess.CompletedProcess, Outcome]:
"""Run the program with `inp` as input.
Return test outcome based on result of `subprocess.run()`."""
result = self.run_process(inp)
if result.returncode == 0:
outcome = self.PASS
elif result.returncode < 0:
outcome = self.FAIL
else:
outcome = self.UNRESOLVED
return (result, outcome)
cat 프로그램은 입력을 받아 그대로 출력을 하는 유틸리티로, 이를 사용하여 ProgramRunner의 동작을 시연할 수 있습니다. 아래는 ProgramRunner 클래스의 정의와 이를 사용한 cat 프로그램의 예제입니다:
cat = ProgramRunner(program="cat")
cat.run("hello")
>> (CompletedProcess(args='cat', returncode=0, stdout='hello', stderr=''), 'PASS')
print("Standard Output:", result.stdout)
>> Standard Output : hello
print("Outcome:", outcome)
>> Outcome: PASS
Fuzzer Classes
Fuzzer는 데이터를 소비자에게 실제로 제공하는 클래스를 정의한다.
class Fuzzer:
"""Base class for fuzzers."""
def __init__(self) -> None:
"""Constructor"""
pass
def fuzz(self) -> str:
"""Return fuzz input"""
return ""
def run(self, runner: Runner = Runner()) -> Tuple[subprocess.CompletedProcess, Outcome]:
"""Run `runner` with fuzz input"""
return runner.run(self.fuzz())
def runs(self, runner: Runner = PrintRunner(), trials: int = 10) -> List[Tuple[subprocess.CompletedProcess, Outcome]]:
"""Run `runner` with fuzz input, `trials` times"""
return [self.run(runner) for i in range(trials)]
기본 Fuzzer는 많은 작업을 수행하지 않지만, RandomFuzzer는 임의의 입력을 생성하는 기능을 구현한다.
import random
class RandomFuzzer(Fuzzer):
"""Produce random inputs."""
def __init__(self, min_length: int = 10, max_length: int = 100, char_start: int = 32, char_range: int = 32) -> None:
"""Produce strings of `min_length` to `max_length` characters
in the range [`char_start`, `char_start` + `char_range`)"""
self.min_length = min_length
self.max_length = max_length
self.char_start = char_start
self.char_range = char_range
def fuzz(self) -> str:
string_length = random.randrange(self.min_length, self.max_length + 1)
out = "".join(chr(random.randrange(self.char_start, self.char_start + self.char_range)) for _ in range(string_length))
return outrandom_fuzzer = RandomFuzzer(min_length=20, max_length=20)
for i in range(10):
print(random_fuzzer.fuzz())'>23>33)(&"09.377.*3
*+:5 ? (?1$4<>!?3>.'
4+3/(3 (0%!>!(+9%,#$
/51$2964>;)2417<9"2&
907.. !7:&--"=$7',7*
(5=5'.!*+&>")6%9)=,/
?:&5) ";.0!=6>3+>)=,
6&,?:!#2))- ?:)=63'-
,)9#839%)?&(0<6("*;)
4?!(49+8=-'&499%?< '
아래는 RandomFuzzer를 사용하여 cat 프로그램에 임의의 입력을 생성하고 실행하는 예제이다.
for i in range(10):
inp = random_fuzzer.fuzz()
result, outcome = cat.run(inp)
assert result.stdout == inp
assert outcome == Runner.PASS
여러 번 실행하여 결과 확인할 수 있다.
results = random_fuzzer.runs(cat, 10)
for result, outcome in results:
print(result.stdout)
print(outcome)'연구실 > 퍼징' 카테고리의 다른 글
| [Fuzzing] Lecture 2. Lexical Fuzzing : Mutation Analysis (0) | 2024.08.22 |
|---|---|
| [Fuzzing] Lecture 2. Lexical Fuzzing : Mutation-Based Fuzzing (0) | 2024.08.04 |
| [Fuzzing] Lecture 2. Lexical Fuzzing - Code Coverage (0) | 2024.08.02 |
| [Fuzzing] Lecture 1. Whetting your appetite (Exercise) (2) | 2024.07.08 |
| [Fuzzing] Lecture 1. Whetting Your Appetite (0) | 2024.07.03 |


