Mutation Analysis
Coverage 장에서 프로그램의 어느 부분이 실행되는지를 식별할 수 있는 방법을 소개했다. 이로 인해 테스트 케이스가 프로그램 구조를 얼마나 잘 커버하는지를 평가할 수 있다. 그러나 커버리지만으로는 테스트의 효과를 충분히 측정할 수 없다. 프로그램의 특정 부분을 잘 커버했더라도, 결과의 정확성을 전혀 확인하지 않는 경우도 있기 때문이다.
이번에는 test suite(여러 테스트 케이스, 테스트 묶음)의 효과를 평가하는 또 다른 방법을 소개한다. 코드에 인위적인 결함, 즉 변이를 주입한 후, 이러한 인위적 결함을 테스트 스위트가 감지할 수 있는지 확인한다. 만약 변이를 감지하지 못한다면, 실제 버그도 놓칠 가능성이 높다고 할 수 있다.
Why Structural Coverage is not enough?
그렇다면, 왜 coverage 가 충분하지 않을까?
구조적 커버리지 측정의 문제점 중 하나는 테스트 스위트가 생성한 프로그램 실행이 실제로 올바른지를 확인하지 않는다는 것이다. 예를 들어, 잘못된 출력을 생성하지만 테스트 스위트가 이를 감지하지 못한 경우, 커버리지 관점에서는 올바른 출력과 동일하게 간주된다. 테스트 케이스에서 검증(assertion)을 제거해도 커버리지는 변하지 않지만, 이로 인해 테스트 스위트의 유용성은 크게 떨어진다.
예를 들어 다음과 같은 테스트를 고려해보자.
def ineffective_test_1():
execute_the_program_as_a_whole()
assert True
여기서 마지막 검증은 프로그램이 무엇을 하든지 항상 통과하게 된다. 이 문제를 해결하기 위해, 프로그램에 버그를 주입하고, 테스트 스위트가 이를 탐지할 수 있는지 평가하는 방법을 사용할 수 있다. 하지만, 버그를 수작업으로 생성하는 것은 시간 소모가 크고 개발자의 편견이 개입될 수 있다.
물론 아래와 같이 execute_the_program_as_a_whole()가 예외를 발생시키면 테스트는 실패하겠지만, 이를 피할 방법도 있다.
def ineffective_test_2():
try:
execute_the_program_as_a_whole()
except:
pass
assert True
이 "테스트들"의 문제는 execute_the_program_as_a_whole()이 100% 코드 커버리지(또는 다른 구조적 커버리지 메트릭의 100%)를 달성할 수 있다는 것이다. 하지만 이 100%라는 숫자는 테스트가 버그를 발견할 수 있는 능력을 반영하지 않으며, 실제로는 그 능력이 0%이다.
이것은 최적의 상황이 아니다. 그렇다면 우리의 테스트가 실제로 유용한지 어떻게 확인할 수 있을까?
한 가지 대안은 프로그램에 버그를 주입하고, 주입된 버그를 잡아내는 테스트 스위트의 효과를 평가하는 것이다.
하지만 이 방법에는 또 다른 문제가 있다. 처음에 이러한 버그를 어떻게 만들어낼까?
수동으로 하게 되면, 개발자가 버그가 발생할 가능성이 높은 위치와 그 영향에 대한 선입견에 의해 편향될 가능성이 큽니다. 또한, 좋은 버그를 작성하는 데는 상당한 시간이 걸릴 수 있으며, 그 이점은 매우 간접적이다. 따라서, 이러한 해결책은 충분하지 않다.
Seeding Artifical Faults with Mutation Analysis
변이 분석(Mutation Analysis)은 테스트 스위트의 효과를 평가하기 위한 대체 솔루션을 제공한다. 변이 분석의 개념은 프로그램 코드에 인위적인 결함(변이)을 주입하고, 테스트 스위트가 이를 찾아내는지 확인하는 것이다.
예를 들어, execute_the_program_as_a_whole() 내에서 + 연산자를 -로 바꾸는 것이 이러한 변이가 될 수 있다. 물론, 앞서 설명한 비효과적인 테스트들은 결과를 확인하지 않기 때문에 이 변이를 감지하지 못할 것이다. 그러나 효과적인 테스트는 이를 감지할 것이며, 인위적인 결함을 찾는 데 더 효과적인 테스트일수록 실제 결함을 찾는 데도 더 효과적일 것이라는 가정이 있다.
변이 분석에서 얻을 수 있는 통찰은 프로그래머의 관점에서 버그 삽입의 확률을 고려하는 것이다. 프로그램의 각 요소가 충분히 유사한 관심을 받는다고 가정할 경우, 프로그램의 각 토큰이 잘못 전사될 확률이 유사하다고 가정할 수 있다. 물론, 프로그래머는 컴파일러(또는 기타 정적 분석 도구)가 감지하는 모든 실수를 수정할 것이다. 따라서 컴파일 단계를 통과하는 원본과 다른 유효한 토큰 집합이 해당 프로그램에서 발생할 수 있는 결함을 나타내는 가능한 변이 세트로 간주된다.
테스트 스위트는 이러한 변이(즉, 결함)를 감지하고 예방할 수 있는 능력으로 평가된다. 생성된 모든 유효한 변이 중에서 감지된 변이의 비율은 변이 점수로 계산된다. 이후에 Python 프로그램에서 변이 분석을 구현하는 방법을 살펴볼 것이다. 얻은 변이 점수는 결함을 예방하는 프로그램 분석 도구의 능력을 나타내며, 정적 테스트 스위트, 퍼저(fuzzers)와 같은 테스트 생성기, 정적 및 상징적 실행 프레임워크를 평가하는 데 사용할 수 있다.
약간 다른 관점을 고려하는 것이 직관적일 수 있다. 테스트 스위트는 테스트 대상 프로그램을 입력으로 수용하는 프로그램으로 간주될 수 있다.
이러한 프로그램(테스트 스위트)을 평가하는 가장 좋은 방법은 무엇일까?
우리는 기본적으로 입력 프로그램에 작은 변이를 적용하고, 해당 테스트 스위트가 예상치 못한 동작을 생성하지 않는지 확인함으로써 테스트 스위트를 퍼징(fuzzing)할 수 있다. 테스트 스위트는 원래 프로그램만을 통과시켜야 하며, 따라서 결함으로 간주되지 않는 변이는 테스트 스위트의 결함을 나타낸다.
Structural Coverage Adequacy by Example
커버리지의 문제점과 변이 분석이 어떻게 작동하는지를 설명하기 위해 더 자세한 예시를 소개하겠다. 아래의 triangle() 프로그램은 변의 길이가 a, b, c인 삼각형을 적절한 삼각형 분류로 분류합니다. 우리는 이 프로그램이 올바르게 작동하는지 확인하고자 한다.
def triangle(a, b, c):
if a == b:
if b == c:
return 'Equilateral'
else:
return 'Isosceles'
else:
if b == c:
return "Isosceles"
else:
if a == c:
return "Isosceles"
else:
return "Scalene"
프로그램이 제대로 작동하는지 확인하기 위해 몇 가지 테스트 케이스를 작성했다.
def strong_oracle(fn):
assert fn(1, 1, 1) == 'Equilateral'
assert fn(1, 2, 1) == 'Isosceles'
assert fn(2, 2, 1) == 'Isosceles'
assert fn(1, 2, 2) == 'Isosceles'
assert fn(1, 2, 3) == 'Scalene'
이 테스트들을 실행하면 모두 통과합니다.
strong_oracle(triangle)
>>
그러나 "모든 테스트가 통과했다"는 문장은 우리의 테스트가 효과적일 때만 의미가 있다.
우리 테스트 스위트의 효과는 어느 정도일까? 커버리지 장에서 본 것처럼, 문장 커버리지와 같은 구조적 커버리지 기법을 사용하여 테스트 케이스의 효과를 측정할 수 있다.
커버리지를 시각화하기 위해 show_coverage()라는 함수를 추가한다.
from fuzzingbook.Coverage import Coverage
import inspect
class VisualCoverage(Coverage):
def show_coverage(self, fn):
src = inspect.getsource(fn)
name = fn.__name__
covered = set([lineno for method,
lineno in self._trace if method == name])
for i, s in enumerate(src.split('\n')):
print('%s %2d: %s' % ('#' if i + 1 in covered else ' ', i + 1, s))with VisualCoverage() as cov:
strong_oracle(triangle)
cov.show_coverage(triangle)
strong_oracle() 함수는 모든 가능한 조건을 충분히 커버한 것처럼 보인다. 즉, 구조적 커버리지에 따르면 테스트 케이스 세트가 꽤 괜찮은 편이다. 그러나 얻은 커버리지가 모든 것을 말해줄까? 다음과 같은 테스트 스위트를 대신 고려해보자.
def weak_oracle(fn):
assert fn(1, 1, 1) == 'Equilateral'
assert fn(1, 2, 1) != 'Equilateral'
assert fn(2, 2, 1) != 'Equilateral'
assert fn(1, 2, 2) != 'Equilateral'
assert fn(1, 2, 3) != 'Equilateral'
여기서 확인하고 있는 것은 변이 다른 삼각형이 정삼각형이 아님을 확인하는 것뿐이다. 이 테스트 스위트로 얻은 커버리지는 어떨까?
with VisualCoverage() as cov:
weak_oracle(triangle)
cov.show_coverage(triangle)
실제로 커버리지에서는 차이가 없는 것처럼 보인다. weak_oracle()은 strong_oracle()과 정확히 동일한 커버리지를 얻습니다. 그러나 잠시만 생각해보면, weak_oracle()이 strong_oracle()만큼 효과적이지 않다는 것을 알 수 있다. 하지만 커버리지는 두 테스트 스위트 간의 차이를 구별하지 못한다. 커버리지에서 무엇을 놓치고 있는 걸까?
문제는 커버리지가 우리의 단언문의 품질을 평가할 수 없다는 점이다. 실제로 커버리지는 assertion 에 대해 전혀 신경 쓰지 않는다. 그러나 위에서 보았듯이, 단언문은 테스트 스위트의 효과에서 매우 중요한 부분입니다. 따라서 우리가 필요한 것은 단언문의 품질을 평가할 수 있는 방법이다.
Injecting Artificial Faults
커버리지 장에서 커버리지가 테스트 스위트가 버그를 발견할 가능성을 나타내는 대리 지표로 제시되었습니다. 만약 테스트 스위트가 실제로 버그를 발견할 가능성을 평가하려면 어떻게 할까?
간단히 프로그램에 버그를 하나씩 주입하고, 테스트 스위트가 이러한 버그를 얼마나 많이 감지하는지 세어보면 된다. 감지 빈도는 테스트 스위트가 버그를 발견할 실제 가능성을 제공한다. 이 기법을 결함 주입(Fault Injection)이라고 합니다. 다음은 결함 주입의 예시이다.
def triangle_m1(a, b, c):
if a == b:
if b == c:
return 'Equilateral'
else:
# return 'Isosceles'
return None # <-- injected fault
else:
if b == c:
return "Isosceles"
else:
if a == c:
return "Isosceles"
else:
return "Scalene"
이제 우리의 테스트 스위트가 이 결함을 잡아낼 수 있는지 확인해보자. 먼저 weak_oracle()이 이 변화를 감지할 수 있는지 확인해볼 것이다.
from ExpectError import ExpectError
with ExpectError():
weak_oracle(triangle_m1)
weak_oracle()은 변화를 감지하지 못했습니다. 그렇다면 strong_oracle()은 어떨까?
with ExpectError():
strong_oracle(triangle_m1)
strong_oracle()은 이 결함을 감지할 수 있었으며, 이는 strong_oracle()이 아마도 더 나은 테스트 스위트임을 나타낸다.
결함 주입은 테스트 스위트의 효과를 측정하는 데 좋은 방법이 될 수 있지만, 가능한 결함 목록이 있어야 한다는 전제가 필요합니다. 문제는 이러한 비편향적인 결함 세트를 수집하는 것이 상당히 비용이 많이 든다는 점이다. 감지하기 어렵고 좋은 결함을 만드는 것은 수동적인 과정이며, 생성된 결함은 이를 만든 개발자의 선입견에 의해 편향될 수 있습니다. 또한, 그러한 커스텀 결함이 있다 하더라도 이는 포괄적이지 않으며, 중요한 버그 유형이나 프로그램의 일부를 놓칠 가능성이 크다. 따라서 결함 주입은 커버리지의 충분한 대체재가 되지 못한다.
그렇다면 더 나은 방법이 있을까?
변이 분석은 커스텀된 결함 세트에 대한 대안을 제공한다. 핵심 통찰은, 프로그래머가 해당 프로그램을 이해한다고 가정하면, 대부분의 오류는 매우 작은 전사 오류(몇 개의 토큰)일 가능성이 매우 높다는 것이다. 컴파일러는 이러한 오류의 대부분을 감지할 것이다. 따라서 프로그램에 남아있는 결함의 대부분은 올바른 프로그램의 특정 지점에서 발생하는 작은(단일 토큰) 변이로 인한 것일 가능성이 크다(이 가정은 Competent Programmer Hypothesis 또는 Finite Neighborhood Hypothesis 이라고 한다).
그렇다면 여러 개의 작은 결함으로 구성된 더 큰 결함은 어떨까?
여기서의 핵심 통찰은, 대부분의 복잡한 결함의 경우 단일 작은 결함을 단독으로 감지하는 테스트 케이스가 해당 결함을 포함하는 더 큰 복잡한 결함도 감지할 가능성이 매우 높다는 것이다(이 가정은 Coupling Effect 라고 한다).
이러한 가정을 실제로 어떻게 사용할 수 있을까?
간단히 말해, 원본 프로그램과 작은 변경점(예: 단일 토큰 변경)을 가지는 모든 가능한 유효한 변종을 생성하는 것이다(이러한 변종을 mutants 라고 한다). 그런 다음, 생성된 각 변이체에 대해 주어진 테스트 스위트를 적용한다. 테스트 스위트가 감지한 변이체는 테스트 스위트에 의해 "제거(killed)"되었다고 한다. 테스트 스위트의 효과는 생성된 유효한 변이체 중에서 제거된 변이체의 비율로 나타난다.
다음으로 간단한 변이 분석 프레임워크를 구현하고 이를 사용하여 우리의 테스트 스위트를 평가한다.
Mutating Python Code
Python 프로그램을 조작하기 위해, 우리는 추상 구문 트리(AST) 표현을 사용한다. 이는 프로그램 텍스트를 읽은 후 컴파일러와 인터프리터가 사용하는 내부 표현이다.
간단히 말해, 프로그램을 트리로 변환한 다음 이 트리의 일부를 변경한다. 예를 들어, + 연산자를 -로 또는 그 반대로 변경하거나, 실제 문장을 아무 것도 하지 않는 pass 문으로 변경할 수 있다. 그런 다음, 변이된 트리를 Python 인터프리터에 전달하여 실행하거나, 이를 다시 텍스트 형식으로 변환할 수 있다.
우선, AST 조작 모듈을 가져오고, Python 함수의 소스를 가져오기 위해 inspect.getsource()를 사용할 수 있다. (참고로, 다른 노트북에서 정의된 함수에는 이 방법을 사용할 수 없다.)
import ast
import inspect
triangle_source = inspect.getsource(triangle)
triangle_source
이를 보기 좋게 표현하기 위해 print_content(s, suffix) 함수를 사용하여 문자열 s를 파일과 유사하게 포맷하고 하이라이트한다.

이 소스를 파싱하면 프로그램이 트리 형태로 표현된 추상 구문 트리(AST)를 얻을 수 있다.
이 AST는 어떻게 생겼을까? ast.dump() (텍스트 출력) 를 사용하여 트리 구조를 살펴볼 수 있습니다.
triangle_ast = ast.parse(triangle_source)
print(ast.dump(triangle_ast, indent=4))
텍스트가 너무 많기 떄문에 그래픽 표현으로 더 간단하게 살펴보자.
from bookutils import rich_output
if rich_output():
import showast
showast.show_ast(triangle_ast)
ast.unparse() 함수는 이러한 트리를 다시 익숙한 텍스트 Python 코드 표현으로 변환한다.
print_content(ast.unparse(triangle_ast), '.py')
A Simple Mutator for Functions
이제 triangle() 프로그램을 변형해볼 것이다. 이 프로그램의 유효한 변형 버전을 생성하는 간단한 방법은 일부 문장을 pass로 교체하는 것이다.
MuFunctionAnalyzer는 테스트 스위트의 변형 분석을 담당하는 주요 클래스이다. 이 클래스는 테스트할 함수를 받아들인다. 앞에서 논의한 함수들을 사용하여 소스 코드를 한 번 파싱하고 다시 언파싱함으로써 소스를 정규화한다. 이는 나중에 원본과 변형된 코드 사이의 차이가 공백, 주석 등으로 인해 발생하지 않도록 하기 위함이다.
class MuFunctionAnalyzer:
def __init__(self, fn, log=False):
self.fn = fn
self.name = fn.__name__
src = inspect.getsource(fn)
self.ast = ast.parse(src)
self.src = ast.unparse(self.ast) # normalize
self.mutator = self.mutator_object()
self.nmutations = self.get_mutation_count()
self.un_detected = set()
self.mutants = []
self.log = log
def mutator_object(self, locations=None):
return StmtDeletionMutator(locations)
def register(self, m):
self.mutants.append(m)
def finish(self):
pass
get_mutation_count()는 가능한 변형 수를 가져온다. 이는 어떻게 구현될 수 있는지 이후에 보게 될 것이다.
class MuFunctionAnalyzer(MuFunctionAnalyzer):
def get_mutation_count(self):
self.mutator.visit(self.ast)
return self.mutator.count
Mutator는 개별 변형을 구현하는 기본 클래스이다. 이 클래스는 변형할 위치 목록을 받아들인다. 이 클래스는 mutable_visit() 메서드가 서브클래스에 의해 결정된 모든 관련 노드에 대해 호출되도록 가정한다. 변형 위치 목록 없이 호출되면 가능한 모든 변형 지점을 순회하며 self.count에 개수를 유지한다. 특정 위치 목록과 함께 호출되면 mutable_visit() 메서드가 mutation_visit()을 호출하여 노드에서 변형을 수행한다. 단일 위치가 여러 변형을 생성할 수 있다.
class Mutator(ast.NodeTransformer):
def __init__(self, mutate_location=-1):
self.count = 0
self.mutate_location = mutate_location
def mutable_visit(self, node):
self.count += 1 # statements start at line no 1
if self.count == self.mutate_location:
return self.mutation_visit(node)
return self.generic_visit(node)
StmtDeletionMutator는 모든 문장 처리 방문자에 연결됩니다. 변형은 주어진 문장을 pass 문으로 대체하여 수행된다.
class StmtDeletionMutator(Mutator):
def visit_Return(self, node): return self.mutable_visit(node)
def visit_Delete(self, node): return self.mutable_visit(node)
def visit_Assign(self, node): return self.mutable_visit(node)
def visit_AnnAssign(self, node): return self.mutable_visit(node)
def visit_AugAssign(self, node): return self.mutable_visit(node)
def visit_Raise(self, node): return self.mutable_visit(node)
def visit_Assert(self, node): return self.mutable_visit(node)
def visit_Global(self, node): return self.mutable_visit(node)
def visit_Nonlocal(self, node): return self.mutable_visit(node)
def visit_Expr(self, node): return self.mutable_visit(node)
def visit_Pass(self, node): return self.mutable_visit(node)
def visit_Break(self, node): return self.mutable_visit(node)
def visit_Continue(self, node): return self.mutable_visit(node)
실제 변형은 노드를 pass 문으로 대체하는 것이다.
class StmtDeletionMutator(StmtDeletionMutator):
def mutation_visit(self, node): return ast.Pass()
triangle() 함수의 경우, 이 방문자는 다섯 개의 변형을 생성한다. 즉, 다섯 개의 return 문을 pass로 교체하는 것이다.
MuFunctionAnalyzer(triangle).nmutations
>> 5
개별 변형을 얻는 방법이 필요하다. 이를 위해 MuFunctionAnalyzer를 반복 가능(iterable)하도록 변환한다.
class MuFunctionAnalyzer(MuFunctionAnalyzer):
def __iter__(self):
return PMIterator(self)
class PMIterator:
def __init__(self, pm):
self.pm = pm
self.idx = 0
class PMIterator(PMIterator):
def __next__(self):
i = self.idx
if i >= self.pm.nmutations:
self.pm.finish()
raise StopIteration()
self.idx += 1
mutant = Mutant(self.pm, self.idx, log=self.pm.log)
self.pm.register(mutant)
return mutant
class Mutant:
def __init__(self, pm, location, log=False):
self.pm = pm
self.i = location
self.name = "%s_%s" % (self.pm.name, self.i)
self._src = None
self.tests = []
self.detected = False
self.log = log여기서, PMIterator는 MuFunctionAnalyzer의 반복자 클래스이다. next() 메서드는 해당하는 변형을 반환한다.
Mutant 클래스는 변형 위치를 받으면 변형을 생성하는 로직을 포함한다.
이 클래스는 다음과 같이 사용할 수 있다.
for m in MuFunctionAnalyzer(triangle):
print(m.name)
이름이 다소 일반적이다. 생성된 변형에 대해 더 많은 통찰을 얻을 수 있는지 살펴보자.
generate_mutant() 메서드는 단순히 mutator() 메서드를 호출하고, 변형기에게 AST 복사본을 전달한다.
src() 메서드는 변형된 소스를 반환한다.
class Mutant(Mutant):
def generate_mutant(self, location):
mutant_ast = self.pm.mutator_object(
location).visit(ast.parse(self.pm.src)) # copy
return ast.unparse(mutant_ast)
class Mutant(Mutant):
def src(self):
if self._src is None:
self._src = self.generate_mutant(self.i)
return self._src
아래는 변형을 얻어서 원본과의 차이를 시각화하는 방법이다.
import difflib
for mutant in MuFunctionAnalyzer(triangle):
shape_src = mutant.pm.src
for line in difflib.unified_diff(mutant.pm.src.split('\n'),
mutant.src().split('\n'),
fromfile=mutant.pm.name,
tofile=mutant.name, n=3):
print(line)
출력 예시:
--- triangle
+++ triangle_1
@@ -1,7 +1,7 @@
def triangle(a, b, c):
if a == b:
if b == c:
- return 'Equilateral'
+ pass
else:
return 'Isosceles'
elif b == c:
--- triangle
+++ triangle_2
@@ -3,7 +3,7 @@
if b == c:
return 'Equilateral'
else:
- return 'Isosceles'
+ pass
elif b == c:
return 'Isosceles'
elif a == c:
--- triangle
+++ triangle_3
@@ -5,7 +5,7 @@
else:
return 'Isosceles'
elif b == c:
- return 'Isosceles'
+ pass
elif a == c:
return 'Isosceles'
else:
--- triangle
+++ triangle_4
@@ -7,6 +7,6 @@
elif b == c:
return 'Isosceles'
elif a == c:
- return 'Isosceles'
+ pass
else:
return 'Scalene'
--- triangle
+++ triangle_5
@@ -9,4 +9,4 @@
elif a == c:
return 'Isosceles'
else:
- return 'Scalene'
+ pass
이 차이(diff) 출력에서 +로 시작하는 줄은 추가된 것이며, -로 시작하는 줄은 삭제된 것이다. 다섯 개의 변형 각각이 return 문을 pass 문으로 교체했음을 확인할 수 있다.
이제, diff() 메서드를 Mutant에 추가하여 직접 호출할 수 있도록 한다.
class Mutant(Mutant):
def diff(self):
return '\n'.join(difflib.unified_diff(self.pm.src.split('\n'),
self.src().split('\n'),
fromfile='original',
tofile='mutant',
n=3))
Evaluating Mutations
이제 실제 평가를 구현할 준비가 되었다. 변형된 코드를 평가하기 위해 변형(mutant)을 컨텍스트 관리자로 정의한다. 이 컨텍스트 관리자는 주어진 모든 assert 문이 성공하는지 확인한다.
기본 아이디어는 아래와 같은 코드를 작성할 수 있도록 하는 것이다. 이 때, mutant가 활성화된 동안(with 블록 내에서) 원래 함수는 변형된 함수로 대체된다.
for mutant in MuFunctionAnalyzer(function):
with mutant:
assert function(x) == y
__enter__() 함수는 with 블록에 들어갈 때 호출된다. 이 함수는 변형된 함수를 Python 함수로 생성하고, 이를 global 네임스페이스에 배치하여 assert 문이 원래 함수 대신 변형된 함수를 실행하도록 만든다.
class Mutant(Mutant):
def __enter__(self):
if self.log:
print('->\t%s' % self.name)
c = compile(self.src(), '<mutant>', 'exec')
eval(c, globals())
__exit__() 함수는 예외가 발생했는지(즉, assert 문이 실패했거나 다른 오류가 발생했는지)를 확인하고, 그렇다면 변형이 감지되었음을 표시한다. 마지막으로 원래 함수 정의를 복원한다.
class Mutant(Mutant):
def __exit__(self, exc_type, exc_value, traceback):
if self.log:
print('<-\t%s' % self.name)
if exc_type is not None:
self.detected = True
if self.log:
print("Detected %s" % self.name, exc_type, exc_value)
globals()[self.pm.name] = self.pm.fn
if self.log:
print()
return True
finish() 메서드는 변형에 대해 메서드를 호출하고, 변형이 발견되었는지 확인한 후 결과를 반환한다.
from ExpectError import ExpectTimeout
class MuFunctionAnalyzer(MuFunctionAnalyzer):
def finish(self):
self.un_detected = {
mutant for mutant in self.mutants if not mutant.detected}
변형 점수는 테스트 스위트에 의해 감지된 변형의 비율로 계산된다. 점수 1.0은 모든 변형이 발견되었음을 의미하며, 점수 0.1은 변형의 10%만 감지되었음을 의미한다.
class MuFunctionAnalyzer(MuFunctionAnalyzer):
def score(self):
return (self.nmutations - len(self.un_detected)) / self.nmutations
다음은 이 프레임워크를 사용하는 방법이다.
import sys
for mutant in MuFunctionAnalyzer(triangle, log=True):
with mutant:
assert triangle(1, 1, 1) == 'Equilateral', "Equal Check1"
assert triangle(1, 0, 1) != 'Equilateral', "Equal Check2"
assert triangle(1, 0, 2) != 'Equilateral', "Equal Check3"
mutant.pm.score()
위의 예에서 다섯 개의 변형 중 하나만이 실패한 assert를 유발했다. 따라서 weak_oracle() 테스트 스위트는 20%의 변형 점수를 받는다.
for mutant in MuFunctionAnalyzer(triangle):
with mutant:
weak_oracle(triangle)
mutant.pm.score()
>> 0.2
전역 네임스페이스를 수정하고 있으므로, 변형 내의 반복 루프에서 함수를 직접 참조할 필요가 없다.
def oracle():
strong_oracle(triangle)
for mutant in MuFunctionAnalyzer(triangle, log=True):
with mutant:
oracle()
mutant.pm.score()
즉, 우리는 strong_oracle() 테스트 스위트를 사용하여 100% 변형 점수를 달성할 수 있었다.
다음은 또 다른 예시입니다. gcd()는 두 숫자의 최대 공약수를 계산합니다.
def gcd(a, b):
if a < b:
c = a
a = b
b = c
while b != 0:
c = a
a = b
b = c % b
return a
다음은 이를 위한 테스트입니다. 이 테스트는 얼마나 효과적일까?
for mutant in MuFunctionAnalyzer(gcd, log=True):
with mutant:
assert gcd(1, 0) == 1, "Minimal"
assert gcd(0, 1) == 1, "Mirror"
mutant.pm.score()
>> 0.42857142857142855
위에서 확인할 수 있듯이, TestGCD 테스트 스위트는 42%의 변형 점수를 얻을 수 있었다.
Mutator for Mudules and Test Suites
이전의 triangle() 프로그램을 다시 고려해 보자. 이 프로그램의 유효한 변형 버전을 생성하는 간단한 방법은 일부 문장을 pass로 교체하는 것이다.
입증 목적으로, 프로그램이 다른 파일에 있는 것처럼 진행하고 싶다. 이를 위해 Python에서 Module 객체를 생성하고 함수에 이를 연결할 수 있다.
import types
def import_code(code, name):
module = types.ModuleType(name)
exec(code, module.__dict__)
return module
triangle() 함수를 shape 모듈에 연결한다. shape 모듈을 통해 triangle 함수를 호출할 수 있다.
shape = import_code(shape_src, 'shape')
shape.triangle(1, 1, 1)
>> 'Equilateral'
triangle() 함수를 테스트하기 위해 아래와 같이 StrongShapeTest 클래스를 정의한다.
import unittest
class StrongShapeTest(unittest.TestCase):
def test_equilateral(self):
assert shape.triangle(1, 1, 1) == 'Equilateral'
def test_isosceles(self):
assert shape.triangle(1, 2, 1) == 'Isosceles'
assert shape.triangle(2, 2, 1) == 'Isosceles'
assert shape.triangle(1, 2, 2) == 'Isosceles'
def test_scalene(self):
assert shape.triangle(1, 2, 3) == 'Scalene'
이제, 주어진 클래스에서 테스트 함수를 찾아보는 suite() 라는 helper 함수를 정의한다.
def suite(test_class):
suite = unittest.TestSuite()
for f in test_class.__dict__:
if f.startswith('test_'):
suite.addTest(test_class(f))
return suite
TestTriangle 클래스의 테스트는 여러 테스트 러너를 통해 호출할 수 있다. 가장 간단한 방법은 TestCase의 run() 메서드를 직접 호출하는 것이다.
suite(StrongShapeTest).run(unittest.TestResult())
>> <unittest.result.TestResult run=3 errors=0 failures=0>
TextTestRunner 클래스는 실행의 가시성을 제어할 수 있는 기능을 제공한다. 또한 첫 번째 실패 시 반환할 수 있다.
runner = unittest.TextTestRunner(verbosity=0, failfast=True)
runner.run(suite(StrongShapeTest))
프로그램을 커버리지(코드 커버리지) 하에 실행하는 방법은 다음과 같다.
with VisualCoverage() as cov:
suite(StrongShapeTest).run(unittest.TestResult())
cov.show_coverage(triangle)
다음은 WeakShapeTest 클래스를 정의한 예시이다.
class WeakShapeTest(unittest.TestCase):
def test_equilateral(self):
assert shape.triangle(1, 1, 1) == 'Equilateral'
def test_isosceles(self):
assert shape.triangle(1, 2, 1) != 'Equilateral'
assert shape.triangle(2, 2, 1) != 'Equilateral'
assert shape.triangle(1, 2, 2) != 'Equilateral'
def test_scalene(self):
assert shape.triangle(1, 2, 3) != 'Equilateral'
마찬가지로, 이 테스트가 얼마나 커버리지를 얻는지 확인해보자.
with VisualCoverage() as cov:
suite(WeakShapeTest).run(unittest.TestResult())
cov.show_coverage(triangle)
변형 분석을 하지 않았기 때문에 2개의 test 가 같게 보인다. 변형을 해서 coverage 를 다시 분석해보고자 한다.
MuProgramAnalyzer는 테스트 스위트의 변형 분석을 담당하는 주요 클래스이다. 테스트할 모듈의 이름과 소스 코드를 입력받는다. 소스 코드를 한 번 파싱하고 다시 언파싱하여 정규화한다. 이는 나중에 원본과 변형 간의 차이가 공백, 주석 등으로 인해 발생하지 않도록 하기 위함이다.
class MuProgramAnalyzer(MuFunctionAnalyzer):
def __init__(self, name, src):
self.name = name
self.ast = ast.parse(src)
self.src = ast.unparse(self.ast)
self.changes = []
self.mutator = self.mutator_object()
self.nmutations = self.get_mutation_count()
self.un_detected = set()
def mutator_object(self, locations=None):
return AdvStmtDeletionMutator(self, locations)
Mutator 클래스를 확장한다.
class AdvMutator(Mutator):
def __init__(self, analyzer, mutate_locations=None):
self.count = 0
self.mutate_locations = [] if mutate_locations is None else mutate_locations
self.pm = analyzer
def mutable_visit(self, node):
self.count += 1 # statements start at line no 1
return self.mutation_visit(node)
AdvStmtDeletionMutator는 모든 문장 처리 방문자에 연결된다. 주어진 문장을 pass로 대체하여 변형을 수행한다.
class AdvStmtDeletionMutator(AdvMutator, StmtDeletionMutator):
def __init__(self, analyzer, mutate_locations=None):
AdvMutator.__init__(self, analyzer, mutate_locations)
def mutation_visit(self, node):
index = 0 # 문장을 삭제하는 방법은 단 하나: `pass`로 대체
if not self.mutate_locations: # pass 카운팅
self.pm.changes.append((self.count, index))
return self.generic_visit(node)
else:
mutating_lines = set((count, idx)
for (count, idx) in self.mutate_locations)
if (self.count, index) in mutating_lines:
return ast.Pass()
else:
return self.generic_visit(node)
triangle() 의 변형 개수를 다음과 같이 얻을 수 있다.
MuProgramAnalyzer('shape', shape_src).nmutations
>> 5
개별 변형을 얻기 위해 MuProgramAnalyzer를 반복 가능(iterable)하게 변환한다.
class MuProgramAnalyzer(MuProgramAnalyzer):
def __iter__(self):
return AdvPMIterator(self)
class AdvPMIterator:
def __init__(self, pm):
self.pm = pm
self.idx = 0
class AdvPMIterator(AdvPMIterator):
def __next__(self):
i = self.idx
if i >= len(self.pm.changes):
raise StopIteration()
self.idx += 1
# there could be multiple changes in one mutant
return AdvMutant(self.pm, [self.pm.changes[i]])
Mutant 클래스는 변형 위치를 받으면 변형을 생성하는 로직을 포함한다.
class AdvMutant(Mutant):
def __init__(self, pm, locations):
self.pm = pm
self.i = locations
self.name = "%s_%s" % (self.pm.name,
'_'.join([str(i) for i in self.i]))
self._src = None
다음과 같이 사용할 수 있다.
shape_src = inspect.getsource(triangle)
for m in MuProgramAnalyzer('shape', shape_src):
print(m.name)
generate_mutant() 메서드는 단순히 mutator() 메서드를 호출하고, 변형기에게 AST 복사본을 전달한다. src() 메서드는 변형된 소스를 반환한다. diff() 메서드는 변형을 원본과의 차이로 시각화한다.
import difflib
class AdvMutant(AdvMutant):
def generate_mutant(self, locations):
mutant_ast = self.pm.mutator_object(
locations).visit(ast.parse(self.pm.src)) # copy
return ast.unparse(mutant_ast)
def src(self):
if self._src is None:
self._src = self.generate_mutant(self.i)
return self._src
def diff(self):
return '\n'.join(difflib.unified_diff(self.pm.src.split('\n'),
self.src().split('\n'),
fromfile='original',
tofile='mutant',
n=3))
for mutant in MuProgramAnalyzer('shape', shape_src):
print(mutant.name)
print(mutant.diff())
break
이제 실제 평가를 구현할 준비가 되었다. 이를 위해 테스트 스위트가 정의된 모듈을 수용하고, 해당 모듈에서 테스트 메서드를 호출할 수 있는 기능이 필요다. getitem 메서드는 테스트 모듈을 수락하고, 테스트 모듈의 import 항목을 변형된 모듈로 올바르게 수정하여 MutantTestRunner에 전달한다.
MutantTestRunner는 테스트 모듈에서 모든 test_ 메서드를 호출하고, 변형이 발견되었는지 확인한 후 결과를 반환한다.
class AdvMutant(AdvMutant):
def __getitem__(self, test_module):
test_module.__dict__[
self.pm.name] = import_code(
self.src(), self.pm.name)
return MutantTestRunner(self, test_module)
from ExpectError import ExpectTimeout
class MutantTestRunner:
def __init__(self, mutant, test_module):
self.mutant = mutant
self.tm = test_module
def runTest(self, tc):
suite = unittest.TestSuite()
test_class = self.tm.__dict__[tc]
for f in test_class.__dict__:
if f.startswith('test_'):
suite.addTest(test_class(f))
runner = unittest.TextTestRunner(verbosity=0, failfast=True)
try:
with ExpectTimeout(1):
res = runner.run(suite)
if res.wasSuccessful():
self.mutant.pm.un_detected.add(self)
return res
except SyntaxError:
print('Syntax Error (%s)' % self.mutant.name)
return None
raise Exception('Unhandled exception during test execution')
변형 점수는 score()로 계산된다.
class MuProgramAnalyzer(MuProgramAnalyzer):
def score(self):
return (self.nmutations - len(self.un_detected)) / self.nmutations
프레임워크를 사용하는 방법은 다음과 같다.
import sys
test_module = sys.modules[__name__]
for mutant in MuProgramAnalyzer('shape', shape_src):
mutant[test_module].runTest('WeakShapeTest')
mutant.pm.score()
WeakShape 테스트 스위트는 20%의 변형 점수만을 얻었다.

반면, StrongShapeTest 테스트 스위트를 사용하여 100% 변형 점수를 달성할 수 있었다.
for mutant in MuProgramAnalyzer('shape', shape_src):
mutant[test_module].runTest('StrongShapeTest')
mutant.pm.score()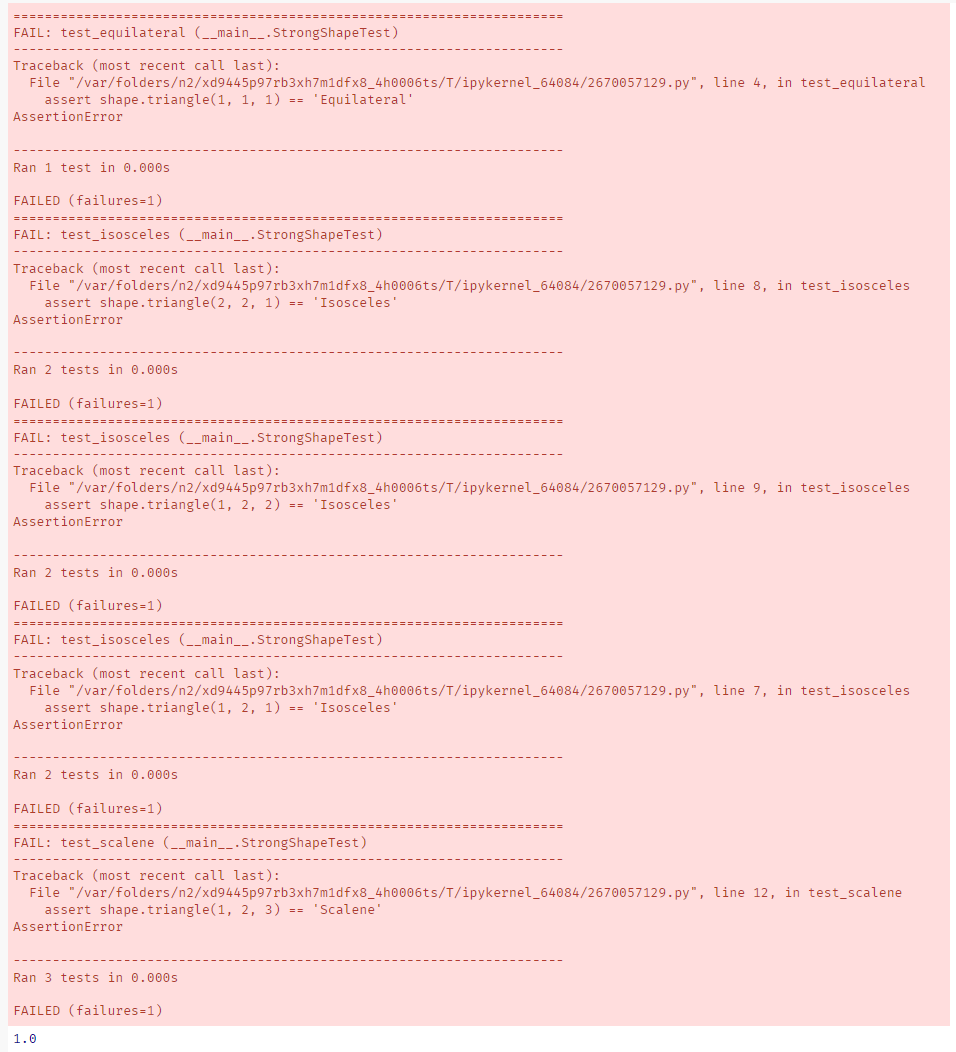
다음은 또 다른 예시인 gcd() 함수이다.
gcd_src = inspect.getsource(gcd)
class TestGCD(unittest.TestCase):
def test_simple(self):
assert cfg.gcd(1, 0) == 1
def test_mirror(self):
assert cfg.gcd(0, 1) == 1
for mutant in MuProgramAnalyzer('cfg', gcd_src):
mutant[test_module].runTest('TestGCD')
mutant.pm.score()
우리는 TestGCD 테스트 스위트가 42%의 변형 점수를 얻을 수 있음을 확인할 수 있었다.
The Problem of Equivalent Mutants
변형 분석에서 발생하는 문제 중 하나는 생성된 모든 변형이 오류를 반드시 포함하지 않는다는 점이다. 예를 들어, 아래의 new_gcd() 프로그램을 고려해 보자.
def new_gcd(a, b):
if a < b:
a, b = b, a
else:
a, b = a, b
while b != 0:
a, b = b, a % b
return a
이 프로그램은 아래와 같은 변형을 통해 생성된 변형 프로그램을 가질 수 있다.
def mutated_gcd(a, b):
if a < b:
a, b = b, a
else:
pass
while b != 0:
a, b = b, a % b
return a
이제 MuFunctionAnalyzer를 사용하여 변형을 생성하고, 각 변형의 소스를 출력해 보자.
for i, mutant in enumerate(MuFunctionAnalyzer(new_gcd)):
print(i, mutant.src())
위의 변형들 중에서 1번 변형은 원본 프로그램과 의미적으로 구별되지 않는다. 이는 중요하지 않은 할당문을 제거했기 때문이다. 이런 식의 변형은 오류를 나타내지 않으며, 이와 같은 변형을 등가 변형(Equivalent Mutants)이라고 한다.
등가 변형 문제의 핵심은 등가 변형이 존재할 때 변형 점수를 판단하기 어렵다는 것이다.
변형 분석(Mutation Analysis)에서, 다양한 변형(mutant)을 만들어 테스트하는 이유는 프로그램의 결함을 발견하거나 테스트 스위트의 강도를 평가하기 위해서이다. 그러나 등가 변형은 결함을 만들어내지 않기 때문에, 등가 변형이 많아지면 변형 분석의 정확도를 떨어뜨릴 수 있다.
이 문제를 해결하기 위한 두 가지 방법을 살펴보자.
1. Statistical Estimation of Number of Equivalent Mutants
만약 살아남은 변형(mutant)의 수가 적다면 이를 수동으로 검사할 수 있다. 그러나 변형의 수가 충분히 많다면, 살아남은 변형 중 일부를 무작위로 선택하여 수동으로 평가하는 방법을 사용할 수 있다. 샘플 크기 결정은 다음과 같은 이항 분포(근사적으로 정규 분포)의 공식을 따른다.
$ n >= {\hat{p}(1-\hat{p})(Z_{\alpha / 2})^{2} \over \Delta^{2}} $
여기서 n 은 샘플의 수, p는 확률 분포의 매개변수, $\alpha$ 는 원하는 정확도, $\Delta$는 정밀도이다.
정확도 95% 에 대해 $Z_{0.95}=1.96$ 일 때, 최대 값 $p(1-p)=0.25$ 를 가지며, $Z$는 정규 분포의 임계 값이다.
$n >= 0.25(1.96 \over \Delta)^{2} $
정밀도 $\Delta=0.01$ (최대 오류 1%) 일 때, 9604개의 변형을 평가해야 한다. 정밀도를 $\Delta=0.1$ (오류10%) 로 완화하면, 96개의 변형만 평가하면 된다.
2. Statistical Estimation of the Number of Immortals by Chao's Estimator
수동 분석이 필요한 샘플링 방법도 매력적이지만, 여전히 제한적이다. 컴퓨팅 파워가 충분하다면, Chao의 추정법을 사용하여 실제 변형의 수(따라서 등가 변형의 수)를 추정할 수 있습니다. Chao의 추정 공식은 다음과 같다.
$ \hat{S}_{Chao1} =\begin{cases} S(n) + {f_{1}^{2} \over 2f_{2}} & if \text{ } f_{2} > 0 \newline S(n) + {f_{1}(f_{1}-1) \over 2} & \text{otherwise} \end{cases} $
기본 아이디어는 각 테스트와 각 변형에 대한 완전한 테스트 매트릭스 $T \times M $ 의 결과를 계산하는 것이다. $ f_{1} $은 정확히 한 번 제거된 변형의 수를 나타내고, $f_{2}$는 정확히 두 번 제거된 변형의 수를 나타낸다. $S(n)$은 제거된 변형의 총 수이다. $\hat{S}_{Chao1}$은 실제 변형 수의 추정치를 제공합니다. 만약 $M$이 생성된 총 변형이라면, $ M-\hat{S}_{Chao1} $은 불사의 변형 수를 나타낸다.
이 불사의 변형은 전통적인 등가 변형과 다르다. 왜냐하면 불사의 여부는 변형의 행동을 구분하는 데 사용된 오라클에 따라 달라지기 때문이다. 예를 들어, 오류를 감지하는 퍼저(fuzzer)를 사용하면 오류를 발생시키지 않는 변형은 감지되지 않는다. 따라서 Chao1 추정치는 퍼저가 무한한 시간 동안 실행된다면 감지할 수 있는 변형의 비대칭 값을 나타낸다. 오라클이 충분히 강력한 경우 불사의 변형 추정치는 실제 등가 변형 추정치에 접근한다.
'연구실 > 퍼징' 카테고리의 다른 글
| [Fuzzing] Lecture 2. Lexical Fuzzing : Mutation-Based Fuzzing (0) | 2024.08.04 |
|---|---|
| [Fuzzing] Lecture 2. Lexical Fuzzing - Code Coverage (0) | 2024.08.02 |
| [Fuzzing] Lecture 2. Lexical Fuzzing(Breaking Things with Random Inputs) (1) | 2024.07.12 |
| [Fuzzing] Lecture 1. Whetting your appetite (Exercise) (2) | 2024.07.08 |
| [Fuzzing] Lecture 1. Whetting Your Appetite (0) | 2024.07.03 |



