이전 내용에서는 program을 test하기 위해 random한 input 을 generate 하는 기본 fuzzing 에 대해서 알아봤었다.
그렇다면 이러한 test 의 효과(fuzzing의 performance)를 어떻게 측정할 수 있을까?
하나의 방법은 발견된 bug 의 수와 심각도를 확인하는 것이다. 하지만, bug가 거의 없는 경우, test가 bug를 발견할 가능성을 추정할 수 있는 대리 척도가 필요하다.
Code Coverage
: test 실행 중에 program의 어느 부분이 실제로 실행되었는지를 측정하는 것이다.
fuzzingbook 에서 제공하는 모듈인 Coverage 클래를 통해 python program의 coverage를 측정할 수 있다.
#pip install fuzzingbook
#pip install --upgrade pip
from fuzzingbook.Coverage import cgi_decode
with Coverage() as cov:
cgi_decode("a+b")
print(cov)
Coverage 객체를 print하면 cover 된 function 이 표시되며, cover 되지 않은 줄 앞에는 # 이 붙는다.
trace() 메소드는 실행된 위치 목록을 반환한다. 각 위치는 (함수 이름, 줄 번호)의 쌍으로 표시된다.
cov.trace()
coverage() 메소드는 실행된 위치의 집합을 반환한다.
cov.coverge()
Coverage 집합은 교집합(여러 실행에서 cover된 위치)과 차집합(실행 a에서 cover되었지만, b에서 커버되지 않은 위치)과 같은 집합 연산의 대상이 될 수 있다.

CGI Decoder
: CGI encoding 된 string을 decode 하는 python function 이다. 이는 URL(웹 주소)에서 공백과 특정 구두점과 같은 유효하지 않은 문자를 encoding하는 데 사용된다.
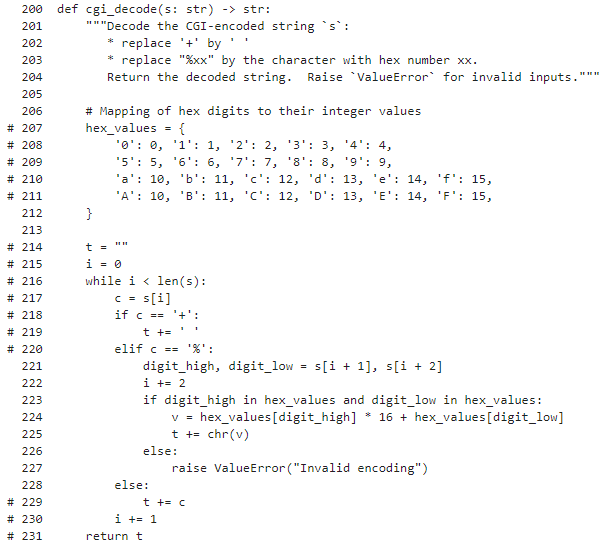
def cgi_decode(s: str) -> str:
"""Decode the CGI-encoded string `s`:
* replace '+' by ' '
* replace "%xx" by the character with hex number xx.
Return the decoded string. Raise `ValueError` for invalid inputs."""
# Mapping of hex digits to their integer values
hex_values = {
'0': 0, '1': 1, '2': 2, '3': 3, '4': 4,
'5': 5, '6': 6, '7': 7, '8': 8, '9': 9,
'a': 10, 'b': 11, 'c': 12, 'd': 13, 'e': 14, 'f': 15,
'A': 10, 'B': 11, 'C': 12, 'D': 13, 'E': 14, 'F': 15,
}
t = ""
i = 0
while i < len(s):
c = s[i]
if c == '+':
t += ' '
elif c == '%':
digit_high, digit_low = s[i + 1], s[i + 2]
i += 2
if digit_high in hex_values and digit_low in hex_values:
v = hex_values[digit_high] * 16 + hex_values[digit_low]
t += chr(v)
else:
raise ValueError("Invalid encoding")
else:
t += c
i += 1
return t
공백은 + 로 대체되며, 다른 유효하지 않은 문자는 %xx 로 대체되며 여기서 xx는 두 자리 16진수이다.
예를 들어, "Hello, world!" 는 "Hello%2c+world%21"로 변환되며, 여기서 2c와 21은 각각 ',' dhk '!'의 16진수 값이다.

그렇다면, cgi_decode() 를 체계적으로 test하려면 어떻게 해야 할까? 두 가지 방법이 있다.
- Black-Box Testing : specification 에서 test를 도출하는 것이다.
- '+' 의 올바른 교체 test
- '%xx' 의 올바른 교체 test
- 다른 문자의 비대체 test
- 불법 input 인식 test
4가지가 모두 통과함을 알 수 있다.
assert cgi_decode('+') == ' '
assert cgi_decode('%20') == ' '
assert cgi_decode('abc') == 'abc'
try:
cgi_decode('%?a')
assert False
except ValueError:
pass
Black-Box Testing 의 장점은 지정된 동작의 오류를 찾는 것이다. 이는 특정 구현에 독립적이며, 구현 전에도 테스트를 작성할 수 있게 한다. 단점은 구현된 동작이 일반적으로 사양 동작보다 더 많은 범위를 다루기 때문에, 사양에만 기반한 테스트는 모든 구현 세부 사항을 커버하지 못할 수 있다는 점이다.
- White-Box Testing : Black-Box Testing 과 달리, 내부 구조에서 test를 도출한다. 이는 code 의 구조적 기능을 cover하는 개념과 밀접하게 연결된다. 예를 들어, 코드의 어떤 구문이 test 중 실행되지 않았다면, 이 구문에서 발생할 수 있는 error 는 발생할 수 없다. 따라서, test 가 충분하다고 할 수 있기 전에 충족해야 하는 여러 Coverage Criteria 이 있다.
- Statement Coverage : code의 문장은 최소 하나의 test input 에 의해 실행되어야 한다.
- Branch Coverage : 코드의 각 분기는 최소 하나의 test input 에 의해 수행되어야 한다. (이는 if 와 while 결정이 한 번은 참, 한 번은 거짓이 되는 것을 의미한다.)
위의 cgi_decode() 를 고려하고, 코드의 각 문장이 최소 한 번은 실행되도록 하려면 무엇을 해야 할까? 다음을 cover 해야 한다.
- if c == '+' 다음의 블록
- if c == '%' 다음의 두 블록(valid input과 invalid input에 대해 각각)
- 모든 다른 문자를 위한 최종 else case
이는 위의 Black-Box Testing 과 동일한 조건을 결과적으로 발생시키며, 다시 말해 위의 asserting 들이 코드의 모든 문장을 cover 할 것이다. 이러한 일치는 꽤 일반적입니다. programmer 들은 보통 서로 다른 행동을 서로 다른 코드 위치에 구현하는 경향이 있기 때문에, 이러한 위치를 커버하는 것은 서로 다른(지정된) 행동을 cover 하는 test case를 이끌어 낸다.
White-Box Testing 의 장점은 구현된 동작에서 Error 를 찾는 것이다. Specification 이 충분한 detail을 제공하지 않는 경우에도 수행할 수 있으며, 실제로 이는 specification 의 corner case를 식별하고 지정하는 데 도움이 된다. 단점은 구현되지 않은 동작을 놓칠 수 있다는 것이다. 특정 기능이 누락된 경우, 화이트박스 테스트는 이를 발견하지 못할 것이다.
Tracing Executions
: White-Box Testing 의 좋은 기능 중 하나는 실제로 일부 프로그램 기능이 cover 되었는지 자동으로 평가할 수 있다는 것이다. 이를 위해 프로그램의 실행을 도구화하여 실행 중에 특수 기능이 어떤 코드가 실행되었는지를 추적하도록 한다. test 후, 이 정보를 programmer 에게 전달하여 아직 cover 되지 않은 code 를 cover 하는 test 작성에 집중할 수 있다.
sys.settrace(f) 함수는 실행된 각 줄마다 호출되는 추적 함수를 정의할 수 있게 한다. 더욱이, 현재 함수와 이름, 현재 변수 내용 등에 접근할 수 있다. 이는 동적 분석(실행 중 실제로 일어나는 일을 분석하는 것) 도구로 이상적이다.
sys.settrace()를 사용하여 실행이 어떻게 진행되는지 추적해 보자.
먼저, 각 줄마다 호출될 추적 함수를 정의한다. 이 함수에는 세 가지 매개변수가 있다.
- 'frame' 매개변수는 현재 frame 을 얻을 수 있게 하며, 현재 위치와 변수에 접근할 수 있게 한다.
- 'frame.f_code' : 현재 실행 중인 코드, 'frame.f_code.co_name'은 함수 이름이다.
- 'frame.f_lineno' : 현재 줄 번호를 보유한다.
- 'frame.f_locals' : 현재 local 변수와 인수를 보유한다.
- 'event' 매개변수는 'line'(새로운 줄이 도달됨) 또는 'call' (함수가 호출됨) 과 같은 event 유형을 나타내는 string 이다.
- 'arg' 매개변수는 일부 event 에 대한 추가 인수이다. 예를 들어 'return' event 의 경우, 'arg' 는 return 값을 보유한다.
추적 함수는 실행된 현재 줄을 보고하는 데 사용된다.
from types import Frametype, TracebackType
coverage = []
def traceit(frame: FrameType, event: str, arg: Any) -> Optional[Callable]:
"""Trace program execution. To be passed to sys.settrace()."""
if event == 'line':
global coverage
function_name = frame.f_code.co_name
lineno = frame.f_lineno
coverage.append(lineno)
return traceit
sys.settrace() 를 사용하여 추적을 turn on 하고 turn off 할 수 있다.
import sys
def cgi_decode_traced(s: str) -> None:
global coverage
coverage = []
sys.settrace(traceit) # Turn on
cgi_decode(s)
sys.settrace(None) # Turn off
이제 cgi_decode("a+b")를 계산할 때, cgi_decode()를 통해 실행이 어떻게 진행되는지 볼 수 있다. hex_values, t 및 i의 초기화 후, while 루프가 입력의 각 문자마다 세 번 수행되는 것을 확인할 수 있다.
cgi_decode_traced("a+b")
print(coverage)
실제로 어떤 줄이었는지 확인하기 위해, 'cgi_decode_code'의 source code를 가져와 'cgi_decode_lines' 라는 배열로 변환하여 coverage 정보를 주석으로 추가할 수 있다.
먼저, cgi_decode' 의 source code 를 가져온다.
import inspect
cgi_decode_code = inspect.getsource(cgi_decode)from booktuils import print_content, print_file
print_content(cgi_decode_code[:300] + "..." , ".py")
splitlines() 를 사용하여 code 를 줄 번호로 index 된 줄 배열로 분할한다.
cgi_decode_lines[L]는 소스 코드의 L번 줄이다.
cgi_decode_lines = [""] + cgi_decode_code.splitlines()
cgi_decode_lines[1]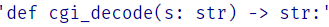
첫 번째로 실행된 줄(9)은 hex_values의 초기화이다.
cgi_decode_lines[9:13]
다음은 t의 초기화이다.
cgi_decode_lines[15]
실제로 한 번 이상 cover 된 줄을 확인하려면, coverage를 집합으로 변환할 수 있다.
covered_lines = set(coverage)
print(covered_lines)
이제 전체 코드를 출력하고, cover 되지 않은 줄에 # 로 표시할 수 있다. 이러한 주석의 목적은 개발자가 cover 되지 않은 줄에 주의를 기울이도록 유도하는 것이다.
for lineno in range(1, len(cgi_decode_lines)):
if lineno not in covered_lines:
print("# ", end="")
else:
print(" ", end="")
print("%2d " % lineno, end="")
print_content(cgi_decode_lines[lineno], '.py')
print()
실행되지 않은 줄(특히 주석)이 실행되지 않은 이유는 실행 가능하지 않기 때문이다. 그러나 elif c == '%' 아래의 줄이 아직 실행되지 않은 것을 볼 수 있다. "a+b"가 우리의 유일한 test case 라면, 이 누락된 coverage 는 이제 이러한 # 으로 표시된 줄을 실제로 커버하는 다른 test case 를 만들도록 격려할 것이다.
Coverage Class
이 책에서는 fuzzing 과 같은 다양한 test 생성 기술의 효과를 측정하고, test 생성을 코드 커버리지로 유도하기 위해 커버리지를 계속 사용할 것이다. 이전 구현에서의 전역 coverage 변수는 조금 번거로웠다. 따라서 책에서 제공해주는 쉽게 커버리지를 측정할 수 있도록 구현된 기능을 사용해보자.
아래는 Coverage class 이다.
class Coverage:
"""Track coverage within a `with` block. Use as
```
with Coverage() as cov:
function_to_be_traced()
c = cov.coverage()
```
"""
def __init__(self) -> None:
"""Constructor"""
self._trace: List[Location] = []
# Trace function
def traceit(self, frame: FrameType, event: str, arg: Any) -> Optional[Callable]:
"""Tracing function. To be overloaded in subclasses."""
if self.original_trace_function is not None:
self.original_trace_function(frame, event, arg)
if event == "line":
function_name = frame.f_code.co_name
lineno = frame.f_lineno
if function_name != '__exit__': # avoid tracing ourselves:
self._trace.append((function_name, lineno))
return self.traceit
def __enter__(self) -> Any:
"""Start of `with` block. Turn on tracing."""
self.original_trace_function = sys.gettrace()
sys.settrace(self.traceit)
return self
def __exit__(self, exc_type: Type, exc_value: BaseException,
tb: TracebackType) -> Optional[bool]:
"""End of `with` block. Turn off tracing."""
sys.settrace(self.original_trace_function)
return None # default: pass all exceptions
def trace(self) -> List[Location]:
"""The list of executed lines, as (function_name, line_number) pairs"""
return self._trace
def coverage(self) -> Set[Location]:
"""The set of executed lines, as (function_name, line_number) pairs"""
return set(self.trace())
def function_names(self) -> Set[str]:
"""The set of function names seen"""
return set(function_name for (function_name, line_number) in self.coverage())
def __repr__(self) -> str:
"""Return a string representation of this object.
Show covered (and uncovered) program code"""
t = ""
for function_name in self.function_names():
# Similar code as in the example above
try:
fun = eval(function_name)
except Exception as exc:
t += f"Skipping {function_name}: {exc}"
continue
source_lines, start_line_number = inspect.getsourcelines(fun)
for lineno in range(start_line_number, start_line_number + len(source_lines)):
if (function_name, lineno) not in self.trace():
t += "# "
else:
t += " "
t += "%2d " % lineno
t += source_lines[lineno - start_line_number]
return twith OBJECT [as VARIABLE]:
BODY
OBJECT가 정의되고 VARIABLE에 저장된 상태로 BODY를 실행한다. 흥미로운 점은 BODY의 시작과 끝에서 OBJECT.__enter__()와 OBJECT.__exit__()라는 특수 메서드가 자동으로 호출된다. 심지어 BODY에서 예외가 발생하더라도 호출된다. 이를 통해 Coverage 객체를 정의할 수 있으며, Coverage.__enter__()는 자동으로 추적을 켜고, Coverage.__exit__()는 추적을 다시 끄게 된다. 추적 후에는 커버리지에 접근할 수 있는 특수 메서드를 사용할 수 있습니다. 아래는 사용 예시이다.
with Coverage() as cov:
cgi_decode("a+b")
print(cov.coverage())
보시다시피 Coverage() 클래스는 실행된 줄 뿐만 아니라 함수 이름도 추적한다. 이는 여러 파일에 걸쳐 있는 프로그램에 유용하다.
대화형으로 사용할 때, 단순히 Coverage 객체를 출력하여 다시 # 으로 표시된 cover 되지 않은 줄과 함께 코드를 나열할 수 있다.
print(cov)
Comparing Coverage
coverage 를 실행된 줄의 집합으로 나타내기 때문에, 이러한 집합에 대해 집합 연산을 적용할 수 있다. 예를 들어, 개별 test case 에서 cover 된 줄과 그렇지 않은 줄을 찾을 수 있다.
with Coverage() as cov_plus:
cgi_decode("a+b")
with Coverage() as cov_standard:
cgi_decode("abc")
cov_plus.coverage() - cov_standard.coverage()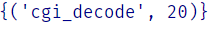
또한, 어떤 줄이 아직 커버되지 않았는지 비교할 수 있다. cov_max를 최대 커버리지로 정의해 보자.
with Coverage() as cov_max:
cgi_decode('+')
cgi_decode('%20')
cgi_decode('abc')
try:
cgi_decode('%?a')
except Exception:
pass
그런 다음, 특정 테스트 케이스에서 커버되지 않은 줄을 쉽게 확인할 수 있다.
cov_max.coverage() - cov_plus.coverage()
{('cgi_decode', 22),
('cgi_decode', 23),
('cgi_decode', 24),
('cgi_decode', 25),
('cgi_decode', 26),
('cgi_decode', 28)}
다시 말해, 입력에 "%xx"가 포함되지 않은 부분을 처리하는 줄이다.
Coverage of Basic Fuzzing
이제 우리의 커버리지 추적을 사용하여 테스트 방법의 효과를 평가할 수 있다. 특히, 무작위 입력만으로 cgi_decode()에서 최대 커버리지를 달성하는 도전 과제가 주어다. 원칙적으로, 우리는 우주에 존재하는 모든 문자열을 결국 생성하게 될 것이므로 결국 도달할 것입니다. 하지만 정확히 얼마나 걸릴까? 이를 위해 cgi_decode()에서 단 하나의 퍼징 반복을 실행해보자.
from Fuzzer import fuzzer
sample = fuzzer()
sample
>> '!7#%"*#0=)$;%6*;>638:*>80"=</>(/*:-(2<4 !:5*6856&?""11<7+%<%7,4.8,*+&,,$,."'
다음은 호출과 우리가 달성한 커버리지이다. 우리는 "잘못된 %xx 형식에 의해 발생하는 ValueError 예외를 무시할 수 있도록 cgi_decode()를 try...except 블록으로 랩핑한다.
with Coverage() as cov_fuzz:
try:
cgi_decode(sample)
except:
pass
cov_fuzz.coverage()
이것이 이미 최대 커버리지일까? 분명히, 아직도 누락된 줄이 있다.
cov_max.coverage() - cov_fuzz.coverage()
이제 100개의 무작위 입력을 통해 커버리지를 증가시켜 보자. 우리는 cumulative_coverage 배열을 사용하여 시간에 따라 달성된 커버리지를 저장한다. cumulative_coverage[0]은 입력 1 이후의 커버된 총 줄 수, cumulative_coverage[1]은 입력 1~2 이후의 커버된 줄 수, 그리고 계속된다.
trials = 100
def population_coverage(population: List[str], function: Callable) \
-> Tuple[Set[Location], List[int]]:
cumulative_coverage: List[int] = []
all_coverage: Set[Location] = set()
for s in population:
with Coverage() as cov:
try:
function(s)
except:
pass
all_coverage |= cov.coverage()
cumulative_coverage.append(len(all_coverage))
return all_coverage, cumulative_coverage
이제 100개의 입력을 생성하여 커버리지가 어떻게 증가하는지 확인한다.
def hundred_inputs() -> List[str]:
population = []
for i in range(trials):
population.append(fuzzer())
return populationall_coverage, cumulative_coverage = \
population_coverage(hundred_inputs(), cgi_decode)
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(cumulative_coverage)
plt.title('Coverage of cgi_decode() with random inputs')
plt.xlabel('# of inputs')
plt.ylabel('lines covered')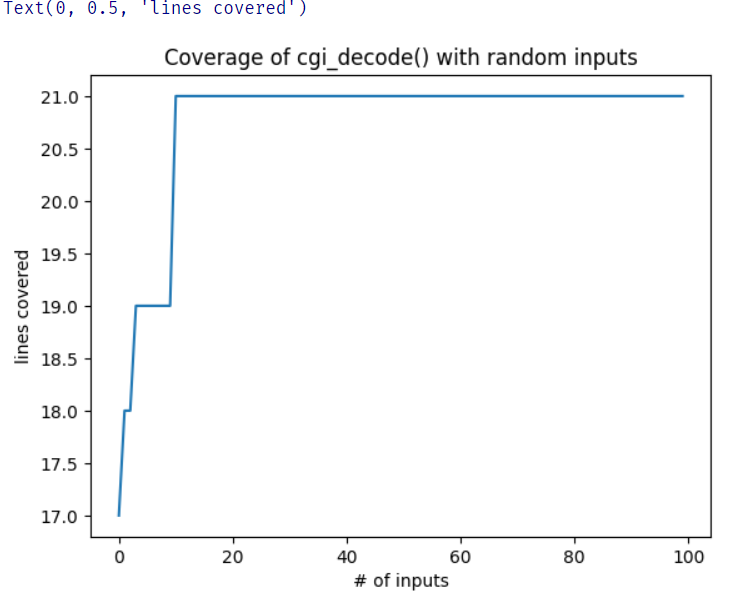
이는 단 하나의 실행일 뿐이다. 따라서, 이를 여러 번 반복하고 평균을 plotting 한다.
runs = 100
# Create an array with TRIALS elements, all zero
sum_coverage = [0] * trials
for run in range(runs):
all_coverage, coverage = population_coverage(hundred_inputs(), cgi_decode)
assert len(coverage) == trials
for i in range(trials):
sum_coverage[i] += coverage[i]
average_coverage = []
for i in range(trials):
average_coverage.append(sum_coverage[i] / runs)plt.plot(average_coverage)
plt.title('Average coverage of cgi_decode() with random inputs')
plt.xlabel('# of inputs')
plt.ylabel('lines covered')
평균적으로 40-60 fuzzing inputs 이후에 full coverage 를 달성하는 것을 볼 수 있다.
Getting Coverage from External Programs
예제로 C 프로그램에 대한 커버리지를 얻는 방법을 시연해 보자. 이번에는 명령줄에서 실행되는 프로그램으로 구현한다.
$ ./cgi_decode 'Hello+World'
>> Hello World
C 코드는 먼저 일반적인 C 인클루드를 포함한 파이썬 문자열로 제공된다.
cgi_c_code = """
/* CGI decoding as C program */
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
"""
여기서는 hex_values의 초기화가 있다.
cgi_c_code += r"""
int hex_values[256];
void init_hex_values() {
for (int i = 0; i < sizeof(hex_values) / sizeof(int); i++) {
hex_values[i] = -1;
}
hex_values['0'] = 0; hex_values['1'] = 1; hex_values['2'] = 2; hex_values['3'] = 3;
hex_values['4'] = 4; hex_values['5'] = 5; hex_values['6'] = 6; hex_values['7'] = 7;
hex_values['8'] = 8; hex_values['9'] = 9;
hex_values['a'] = 10; hex_values['b'] = 11; hex_values['c'] = 12; hex_values['d'] = 13;
hex_values['e'] = 14; hex_values['f'] = 15;
hex_values['A'] = 10; hex_values['B'] = 11; hex_values['C'] = 12; hex_values['D'] = 13;
hex_values['E'] = 14; hex_values['F'] = 15;
}
"""
여기서는 입력 소스(s)와 출력 대상(t)을 위한 포인터를 사용한 cgi_decode()의 실제 구현이 있다.
cgi_c_code += r"""
int cgi_decode(char *s, char *t) {
while (*s != '\0') {
if (*s == '+')
*t++ = ' ';
else if (*s == '%') {
int digit_high = *++s;
int digit_low = *++s;
if (hex_values[digit_high] >= 0 && hex_values[digit_low] >= 0) {
*t++ = hex_values[digit_high] * 16 + hex_values[digit_low];
}
else
return -1;
}
else
*t++ = *s;
s++;
}
*t = '\0';
return 0;
}
"""
마지막으로, 첫 번째 인수를 받아 'cgi_decode' 를 호출하는 driver 가 있다.
cgi_c_code += r"""
int main(int argc, char *argv[]) {
init_hex_values();
if (argc >= 2) {
char *s = argv[1];
char *t = malloc(strlen(s) + 1); /* output is at most as long as input */
int ret = cgi_decode(s, t);
printf("%s\n", t);
return ret;
}
else
{
printf("cgi_decode: usage: cgi_decode STRING\n");
return 1;
}
}
"""
C source code 를 생성한다.
with open("cgi_decode.c", "w") as f:
f.write(cgi_c_code)
이제 syntax highlighting 과 함께 C source code를 확인할 수 있다.
from bookutils import print_file
print_file("cgi_decode.c")
이제 C 코드를 컴파일하여 실행 파일을 생성할 수 있다. --coverage 옵션은 C 컴파일러에 코드를 도구화하여 런타임에 커버리지 정보를 수집하도록 지시한다. (정확한 옵션은 컴파일러마다 다르다.)
!cc --coverage -o cgi_decode cgi_decode.c
이제 프로그램을 실행하면 커버리지 정보가 자동으로 수집되고 보조 파일에 저장된다.
!./cgi_decode 'Send+mail+to+me%40fuzzingbook.org'
>> Send mail to me@fuzzingbook.org
커버리지 정보는 gcov 프로그램에 의해 수집된다. 각 source file 에 대해 새로운 .gcov 파일이 생성되며, 이 파일에 커버리지 정보가 포함된다.
!gcov cgi_decode.c
File 'cgi_decode.c'
Lines executed:92.50% of 40
Creating 'cgi_decode.c.gcov'
.gcov 파일의 각 줄에는 호출 횟수(-는 실행 불가능한 줄을 나타내며, #####는 0을 나타냄)와 줄 번호가 접두어로 표시된다. 예를 들어 cgi_decode()를 보면 잘못된 입력에 대한 return -1을 제외한 코드가 모두 실행된 것을 볼 수 있다.
lines = open('cgi_decode.c.gcov').readlines()
for i in range(30, 50):
print(lines[i], end='')
이 파일을 읽어와 커버리지 집합을 얻어보자.
def read_gcov_coverage(c_file):
gcov_file = c_file + ".gcov"
coverage = set()
with open(gcov_file) as file:
for line in file.readlines():
elems = line.split(':')
covered = elems[0].strip()
line_number = int(elems[1].strip())
if covered.startswith('-') or covered.startswith('#'):
continue
coverage.add((c_file, line_number))
return coverage
coverage = read_gcov_coverage('cgi_decode.c')
이 집합을 사용하면, Python programs 과 마찬가지로 coverage 계산을 수행할 수 있다.
Finding Errors with Basic Fuzzing
: 충분한 시간이 주어진다면, 어떤 프로그래밍 언어에서든지 간에 cgi_decode()의 모든 줄을 커버할 수 있다. 그러나 이는 그들이 오류가 없다는 것을 의미하지는 않는다. 우리는 cgi_decode()의 결과를 확인하지 않기 때문에, 함수는 어떤 값을 반환하더라도 우리가 확인하거나 알 수 없다. 이러한 오류를 잡으려면 결과 검사자(일반적으로 오라클이라고 불림)를 설정하여 테스트 결과를 확인해야 한다. 우리의 경우, 파이썬 구현과 C 구현의 cgi_decode()를 비교하여 둘 다 같은 결과를 산출하는지 확인할 수 있다.
그러나 퍼징이 훌륭한 점은 실행 결과를 확인하지 않고도 내부 오류를 발견할 수 있다는 점이다. 실제로, cgi_decode()에서 fuzzer()를 실행하면 다음 코드가 보여주는 것처럼 이 오류를 쉽게 발견할 수 있다.
from ExpectError import ExpectError
with ExpectError():
for i in range(trials):
try:
s = fuzzer()
cgi_decode(s)
except ValueError:
pass
cgi_decode() 가 crash 될 수 있습니다. 왜 그럴까? 입력을 살펴보자.
s
>> '82 202*&<1&($34\'"/\'.<5/!8"\'5:!4))%;'
문제는 문자열 끝에 있다. '%' 문자 이후에 구현은 항상 두 개의 (16진수) 문자를 액세스하려고 시도하지만, 만약 존재하지 않으면 IndexError 예외가 발생한다.
'연구실 > 퍼징' 카테고리의 다른 글
| [Fuzzing] Lecture 2. Lexical Fuzzing : Mutation Analysis (0) | 2024.08.22 |
|---|---|
| [Fuzzing] Lecture 2. Lexical Fuzzing : Mutation-Based Fuzzing (0) | 2024.08.04 |
| [Fuzzing] Lecture 2. Lexical Fuzzing(Breaking Things with Random Inputs) (1) | 2024.07.12 |
| [Fuzzing] Lecture 1. Whetting your appetite (Exercise) (2) | 2024.07.08 |
| [Fuzzing] Lecture 1. Whetting Your Appetite (0) | 2024.07.03 |



